在看这篇文章前,需要了解两方面知识
能量函数https://blog.csdn.net/a6333230/article/details/79751825
范数https://blog.csdn.net/a6333230/article/details/87860875
正则化用途:避免过拟合问题
如何用?
把正则项(L-1或者L-2范数)加入到能量函数中一起运算,和惩罚函数类似。

惩罚?→能量函数一般都是用来描述一个方程的最优解,找到了能量函数的最小值就找到了方程的最优解,而这个最小值的求解过程多数是一步一步地迭代。惩罚就是能量函数里面的一项,能量函数想要找到最小值,如果迭代的方向不满足惩罚函数需要的方向,那么惩罚函数就变大了,你想小?我偏不要,除非你按我说的做。
例如:

J就是我们的能量函数,前一项(h-y)就是我们的现有函数和目标函数的差值,后一项就是惩罚项,学过范数的能够看出这个后一项类似于二范数,所以这里说的正则项多数是引入的1范数或者2范数。
我们知道了什么是正则项了,那么我们为什么要这么做呢?
从范数(正则项)中我们可以看出,我们要想让J变小,在让(h-y)变小的同时我们还需要让θ的和变小,如何变小呢,尽量让θ的总体数目变小、单个的值变小。
这里可以对应到机器学习当中的权重,更好理解的就是
y=θ1x1+θ2x2+θ3x3+θ4x4……
总体数目变小,有些θ变为0无效掉就好
y=θ1x1+θ4x4……
那么哪些可以变成0能,这个就需要看前一项了(h-y),怎么变对它有利怎么来。
单个的值变小,让每个θ都不过大,这就像不能把鸡蛋都放在一个篮子里一样,不让某几项其作用太大,避免由于为了拟合某几项而造成的整体拟合效果不佳。它的控制也是(h-y)项决定的。
还有就是有些方程如果不加正则项其结果可能一直在跳动不能收敛,当加入正则项后,整个函数开始以正则项为主了。
例如:比较犯难,一个事三个人做也行,四个人做也行,无法得到最终策略,加上正则项人越多花钱越多,所以问题的最终策略就收敛到了找三个人做这件事了。哪三个人?要钱最少的(当然人家要钱多有人家的道理)。
其实他们放到了一起(h-y)与θ,就是一根绳上的蚂蚱,相互制约,最终目的都是为了能量函数最小。
让整体变小的过程是什么呢?迭代,迭代,迭代……涉及到很多参数的函数最优,很多情况下都是迭代。能量函数对变量进行求导,然后对变量进行迭代。
例如
y=0.1x^2
y对x求导0.2x
现在x=10,0.2x=2
迭代x2=x-0.2x(负梯度方向走下降最快(有人会问这里不是求导么?怎么和梯度有关,问得好,去看下这篇比较精彩的讲解:https://blog.csdn.net/a6333230/article/details/81220252))
经过迭代,我们现在的x就变成了x=x2=8,这样看我们就朝着变小的方向进行移动了。机器学习中的w权重迭代就是这个道理。
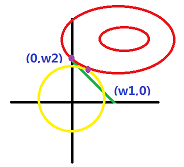
最后再提一下L-1和L-2的区别(L-1具有稀疏性,L-2不具有(稀疏性——可以去掉方程中的几项,也就是几项的权重为0))
例如
L-1:θ1+θ2+θ3+……
L-2:(θ1)平方+(θ2)平方+(θ3)平方+……

L-1是个棱体,L-2是个球体。
棱体在每个顶点都会出现一些参数为0的现象
而且在求最优时,最终结果很有可能出现在顶点上。而球体则不易出现该现象