原文:https://www.linuxidc.com/Linux/2016-12/137936.htm
一、简介
1、环形队列是一种特殊的队列结构,保证了元素也是先进先出的,但与一般队列的区别是,他们是环形的,即队列头部的上个元素是队列尾部,通常是容纳元素数固定的一个闭环。采用环形缓冲区的好处为,当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝提高效率
2、优点:
保证元素的先进先出。
元素空间可以重复利用。
为多线程数据通信提供了一种高效的机制。
3、实现
Linux kernal kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的。
源码:kernel/kfifo.c
1: struct kfifo {
2: unsigned char *buffer; /* the buffer holding the data ,用于存放数据的缓存*/
3: unsigned int size; /* the size of the allocated buffer,缓冲区空间的大小,在初化时,将它向上圆整成2的幂*/
4: unsigned int in; /* data is added at offset (in % size),指向buffer中队头 */
5: unsigned int out; /* data is extracted from off. (out % size),指向buffer中的队尾 */
6: spinlock_t *lock; /* protects concurrent modifications,如果使用不能保证任何时间最多只有一个读线程和写线程,必须使用该lock实施同步。 */
7: };
结构图:
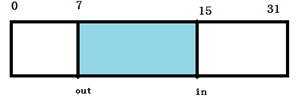
“取模运算”的效率并没有 “位运算” 的效率高,可以将kfifo->size取模运算可以转化为与运算,如下:kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
tips:判断n能否被2整除:
bool is_power_of_2(unsigned long n)
{
return (n != 0 && ((n & (n - 1)) == 0));
}
为什么kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的呢?因为上一节中讲的内存屏障。
| smp_rmb | 适用于多处理器的读内存屏障。 |
| smp_wmb | 适用于多处理器的写内存屏障。 |
| smp_mb | 适用于多处理器的内存屏障 |
二、代码分析
入队__kfifo_put和出队__kfifo_get代码分析
1、__kfifo_put是入队操作,它先将数据放入buffer中,然后移动in的位置,其源代码如下:
1: unsigned int __kfifo_put(struct kfifo *fifo,
2: const unsigned char *buffer, unsigned int len)
3: {
4: unsigned int l;
5:
6: len = min(len, fifo->size - fifo->in + fifo->out);
7:
8: /*
9: * Ensure that we sample the fifo->out index -before- we
10: * start putting bytes into the kfifo.
11: */
12:
13: smp_mb();
14:
15: /* first put the data starting from fifo->in to buffer end */
16: l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
17: memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
18:
19: /* then put the rest (if any) at the beginning of the buffer */
20: memcpy(fifo->buffer, buffer + l, len - l);
21:
22: /*
23: * Ensure that we add the bytes to the kfifo -before-
24: * we update the fifo->in index.
25: */
26:
27: smp_wmb();
28:
29: fifo->in += len;
30:
31: return len;
32: }
分析:
6行,环形缓冲区的剩余容量为fifo->size - fifo->in + fifo->out,让写入的长度取len和剩余容量中较小的,避免写越界;
13行,加内存屏障,保证在开始放入数据之前,fifo->out取到正确的值(另一个CPU可能正在改写out值)
16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1),所以fifo->size - (fifo->in & (fifo->size - 1)) 即位 fifo->in 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为需要拷贝l 字节到fifo->buffer + fifo->in的位置上。
17行,拷贝l 字节到fifo->buffer + fifo->in的位置上,如果l = len,则已拷贝完成,第20行len – l 为0,将不执行,如果l = fifo->size - (fifo->in & (fifo->size - 1)) ,则第20行还需要把剩下的 len – l 长度拷贝到buffer的头部。
27行,加写内存屏障,保证in 加之前,memcpy的字节已经全部写入buffer,如果不加内存屏障,可能数据还没写完,另一个CPU就来读数据,读到的缓冲区内的数据不完全,因为读数据是通过 in – out 来判断的。
29行,注意这里 只是用了 fifo->in += len而未取模,这就是kfifo的设计精妙之处,这里用到了unsigned int的溢出性质,当in 持续增加到溢出时又会被置为0,这样就节省了每次in向前增加都要取模的性能,锱铢必较,精益求精,让人不得不佩服。
2、__kfifo_get是出队操作,它从buffer中取出数据,然后移动out的位置,其源代码如下:
1: unsigned int __kfifo_get(struct kfifo *fifo,
2: unsigned char *buffer, unsigned int len)
3: {
4: unsigned int l;
5:
6: len = min(len, fifo->in - fifo->out);
7:
8: /*
9: * Ensure that we sample the fifo->in index -before- we
10: * start removing bytes from the kfifo.
11: */
12:
13: smp_rmb();
14:
15: /* first get the data from fifo->out until the end of the buffer */
16: l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
17: memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
18:
19: /* then get the rest (if any) from the beginning of the buffer */
20: memcpy(buffer + l, fifo->buffer, len - l);
21:
22: /*
23: * Ensure that we remove the bytes from the kfifo -before-
24: * we update the fifo->out index.
25: */
26:
27: smp_mb();
28:
29: fifo->out += len;
30:
31: return len;
32: }
分析:
6行,可去读的长度为fifo->in – fifo->out,让读的长度取len和剩余容量中较小的,避免读越界;
13行,加读内存屏障,保证在开始取数据之前,fifo->in取到正确的值(另一个CPU可能正在改写in值)
16行,前面讲到fifo->size已经2的次幂圆整,而且kfifo->out % kfifo->size 可以转化为 kfifo->out & (kfifo->size – 1),所以fifo->size - (fifo->out & (fifo->size - 1)) 即位 fifo->out 到 buffer末尾所剩余的长度,l取len和剩余长度的最小值,即为从fifo->buffer + fifo->in到末尾所要去读的长度。
17行,从fifo->buffer + fifo->out的位置开始读取l长度,如果l = len,则已读取完成,第20行len – l 为0,将不执行,如果l =fifo->size - (fifo->out & (fifo->size - 1)) ,则第20行还需从buffer头部读取 len – l 长。
27行,加内存屏障,保证在修改out前,已经从buffer中取走了数据,如果不加屏障,可能先执行了增加out的操作,数据还没取完,令一个CPU可能已经往buffer写数据,将数据破坏,因为写数据是通过fifo->size - (fifo->in & (fifo->size - 1))来判断的 。
29行,注意这里 只是用了 fifo->out += len 也未取模,同样unsigned int的溢出性质,当out 持续增加到溢出时又会被置为0,如果in先溢出,出现 in < out 的情况,那么 in – out 为负数(又将溢出),in – out 的值还是为buffer中数据的长度。
最后,多生产者/多消费者模式的共享队列需要用到gcc4.2以上内置提供__sync_synchronize()这类的函数。