1. 先看看它们长啥样吧!(它们有两种定义,第一种是使能了程序trace功能的宏定义,第二种是普通的宏定义,咱们分析普通宏定义吧)
# define likely(x) __builtin_expect(!!(x), 1) # define unlikely(x) __builtin_expect(!!(x), 0)
2. 从宏中我们可以看到__builtin_expect,这是什么?
这是gcc内置的函数,用来进行分支预测
3. 总是听大家说这样做可以优化性能,但是怎么做到的呢?
3.1 arm处理器中一条指令的执行分为三个阶段,取指,译码,执行;
3.2 提一下流水线,流水线可以提高性能,那么以三级流水线为例;
3.3 加入流水线后,CPU在执行当前指令的时候,已经将接下来要执行指令的取指译码过程完成了,配下图看看;
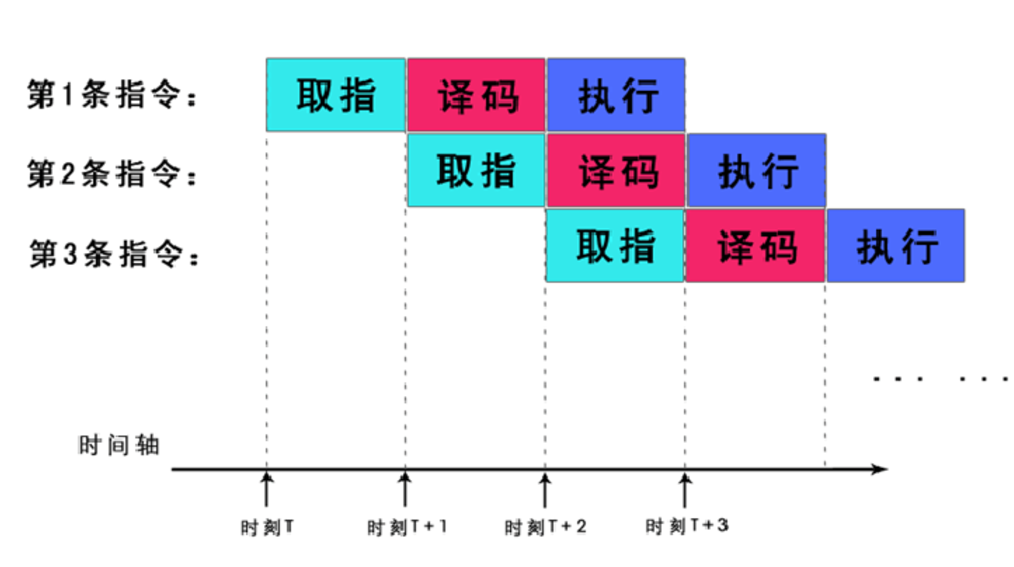
3.4 如果cpu通过判断不执行接下来的指令,那么必然要将已完成的取指译码丢掉,这必然会降低cpu的性能;
3.5 因此如果判断的结果出现的可能性很大,那么cpu就能大大避免丢掉已完成的取指译码,这样也就提高了cpu的性能。
4. 既然这个__builtin_expect是gcc内置的,那么我们去gcc源码中找一下它吧