版权声明:本文内容来源于网络,如有侵权请联系删除 https://blog.csdn.net/ZyhMemory/article/details/88533901
推荐阅读:
Nosql基础
Nosql数据库基础
什么是Nosql
NoSQL 是 Not Only SQL 的缩写,意即"不仅仅是SQL"的意思,泛指非关系型的数据库。它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准、事务的ACDI属性、表结构等等。相比传统数据库,叫它分布式数据管理系统更贴切,数据存储更加灵活多样。
特点
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- 高性能,高可用性和可伸缩性
Redis
Redis简介
- Redis是一款开源的、高性能的键-值存储(key-value store)。它常被称作是一款数据结构服务器(data structure server)。Redis的键值可以包括字符串(strings)类型,同时它还包括哈希(hashes)、列表(lists)、集合(sets)和 有序集合(sorted sets)等数据类型。 对于这些数据类型,你可以执行原子操作。例如:对字符串进行附加操作(append);递增哈希中的值;向列表中增加元素;计算集合的交集、并集与差集等。
- 为了获得优异的性能,Redis采用了内存中(in-memory)数据集(dataset)的方式。同时,Redis支持数据的持久化,你可以每隔一段时间将数据集转存到磁盘上(snapshot),或者在日志尾部追加每一条操作命令(append only file,aof)。
Redis同样支持主从复制(master-slave replication),并且具有非常快速的非阻塞首次同步( non-blocking first synchronization)、网络断开自动重连等功能。同时Redis还具有其它一些特性,其中包括简单的事物支持、发布订阅 ( pub/sub)、管道(pipeline)和虚拟内存(vm)等 。 - Redis具有丰富的客户端,支持现阶段流行的大多数编程语言。
- Redis还提供了网页练习(http://try.redis.io)。
Redis支持的数据类型
String(字符串)
- string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
- string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
- string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
- 实例

- 在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为 abc。
- 注意:一个键最大能存储512MB。
Hash(哈希)
- Redis hash 是一个键值(key=>value)对集合。
- Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
- 实例

- 实例中我们使用了 Redis HMSET, HGET 命令,HMSET 设置了两个 field=>value 对, HGET 获取对应 field 对应的 value。
- 每个 hash 可以存储 2^32 -1 键值对(40多亿)。
List(列表)
- Redis的list类型其实就是一个每个子元素都是string类型的双向链表,链表的最大长度是2^32。list既可以用做栈,也可以用做队列。
- Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
- 实例

- 列表最多可存储 2^32 - 1 元素 (4294967295, 每个列表可存储40多亿)。
Set(集合)
- Redis的Set是string类型的无序集合。
- 集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
- sadd 命令
- 添加一个 string 元素到 key 对应的 set 集合中,成功返回1,如果元素已经在集合中返回 0,如果 key 对应的 set 不存在则返回错误。
- sadd key member
- 实例

- 以上可以看出,为0的为乱序排列。
Redis常用命令
对key操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
EXPIRE 将key的生存时间设置为ttl秒
PEXPIRE 将key的生成时间设置为ttl毫秒
EXPIREAT 将key的过期时间设置为timestamp所代表的的秒数的时间戳
PEXPIREAT 将key的过期时间设置为timestamp所代表的的毫秒数的时间戳
ttl:获得一个key的活动时间
String
SET key value //设置key-value对
GET key /获取值
MSET key1 value1 key2 value2…. //批量设置key
MGET key1 key2 key3 …… //批量获取key
SETNX key value //当且仅当key不存在时才设置
SETEX key second value //设置k-v对时并且设置过期时间
GETSET key value //获取旧值设置新值
STRLEN key //字符串长度
APPEND key value //追加值
GETRANGE key-name start end //返回次字符串的start到end之间的字符
SETRANGE key-name offset value //将value代替从offset开始的字符串
INCR、DECR、INCRBY、DECRBY、INCRBYFLOAT //增加值
GETBIT key-name offset //将字符串看做是二进制位串,并返回位串中的偏移量offset的二进制位的值
SETBIT key-name offset value //将字符串看做是二进制位串,并将位串中偏移量offset的二进制值设置为- value
BITCOUNT key-name [start end] //统计二进制位串里面值为1的数量
BITOP AND|OR|XOR|NOT dest-key key1 key2… 对多个key执行并或异或非,并将结果存入到dest-key
List
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素
ltrim(key, start, end):截取名称为key的list
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值
lrem(key, count, value):删除count个key的list中值为value的元素
lpop(key):返回并删除名称为key的list中的首元素
rpop(key):返回并删除名称为key的list中的尾元素
blpop(key1, key2,… key N, timeout):lpop命令的block版本。
brpop(key1, key2,… key N, timeout):rpop的block版本。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
Set
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :移到集合元素
scard(key) :返回名称为key的set的基数
sismember(key, member) :member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
sunion(key1, (keys)) :求并集
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
sdiff(key1, (keys)) :求差集
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
Sorted set
zadd key score member 添加元素到集合,元素在集合中存在则更新对应score
zrem key member 删除指定元素,1表示成功,如果元素不存在返回0
zincrby key incr member 增加对应member的score值,然后移动元素并保持skip list有序。返回更新后的score值
zrank key member 返回指定元素在集合中的排名(下标,非score),集合中元素是按score从小到大排序的
zrevrank key member 同上,但是集合中元素是按score从大到小排序
zrange key start end 类似lrange操作从集合中取指定区间的元素。返回的是有序结果
zrevrange key start end 同上,返回结果是按score逆序的
zrangebyscore key min max 返回集合中score在给定区间的元素
zcount key min max 返回集合中score在给定区间的数量
zcard key 返回集合中元素个数
zscore key element 返回给定元素对应的score
zremrangebyrank key min max 删除集合中排名在给定区间的元素
zremrangebyscore key min max 删除集合中score在给定区间的元素
Hash
hset(key, field, value):向名称为key的hash中添加元素field
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, (fields)):返回名称为key的hash中field i对应的value
hmset(key, (fields)):向名称为key的hash中添加元素field
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
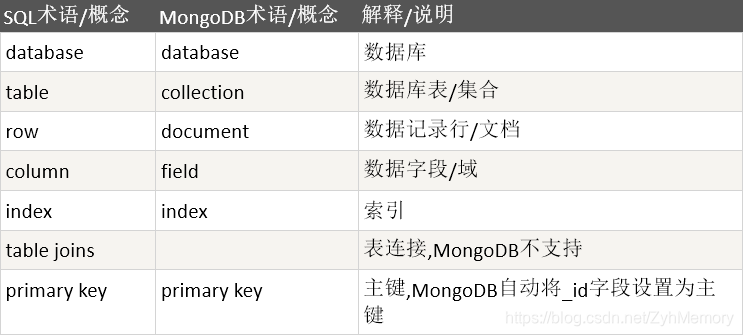
Mongodb
Mongodb简介
什么是Mongodb?
- MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
- 在高负载的情况下,添加更多的节点,可以保证服务器性能。
- MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
- MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。

主要特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=“Sameer”,Address=“8 Gandhi Road”)来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
Mongodb基础概念
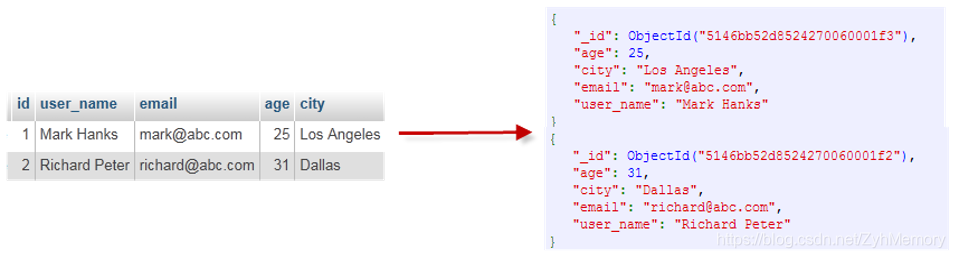
数据逻辑层次关系:文档=>集合=>数据库
- 一个document里可以包含多种类型的field,可以是日期、数字等,也可以是数组,还可以内嵌别的文档:
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ],
views : NumberLong(1250000)
}
- 上面的document中:
- _id是一个objectid,是一个唯一值
- name则是包含了一个有2个field的嵌套文档
- contribs是个数组
- birth和death为date类型
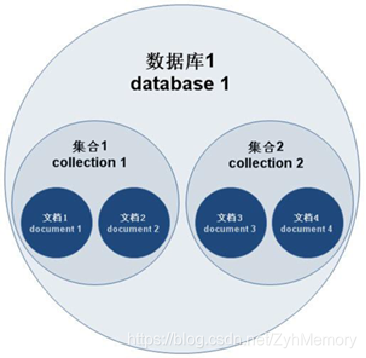
集合
- 集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表格。
- 集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。
- 比如,我们可以将以下不同数据结构的文档插入到集合中:
{"site":"test"}
{"site":"test.com","name":"test2"}
{"site":"www.test.com","name":"test3","num":5}
- 当第一个文档插入时,集合就会被创建。
- 合法的集合名
- 集合名不能是空字符串""。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
文档
- 文档是一组键值(key-value)对(即BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
- 一个简单的文档例子如下:
{"site":"test", "name":"测试"}
- 需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
- 文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
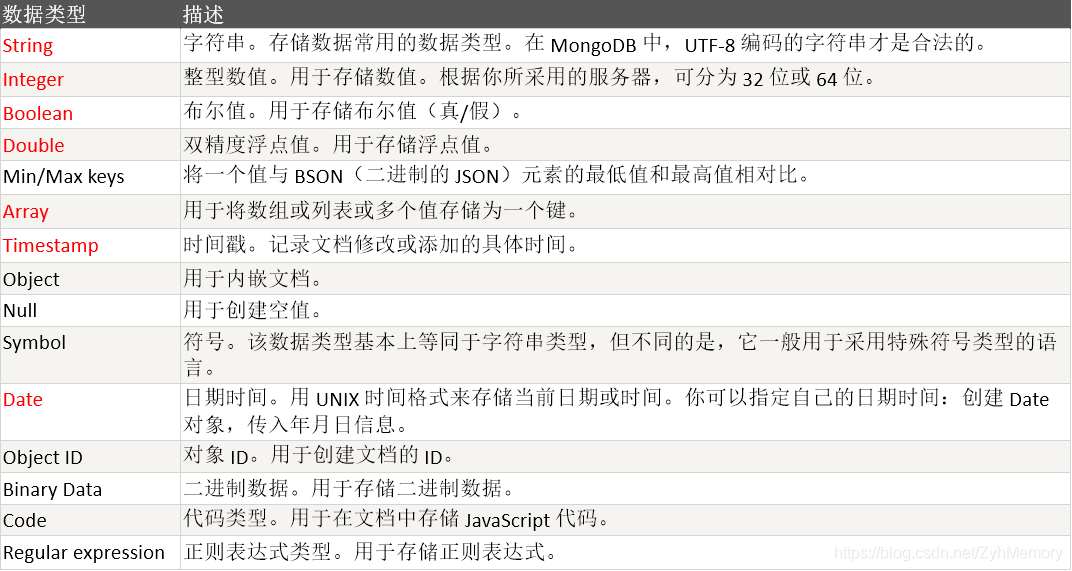
Mongodb数据类型
Mongodb基本操作命令
插入
db.test.insert({name:”Jim”})
db.test.save({name:”Tom”})
删除
db.col_name.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档。
- writeConcern :(可选)抛出异常的级别。
db.test.remove()这个命令会删除集合内所有文档,但是不会删除集合本身,索引一会保留。
db.test.remove({name:”Jim”})删除符合条件的Document
db.drop_collection(“bar”)删除集合,速度快
更新
db.col_name.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
- query : update 的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入记录,true 为插入,默认是 false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
通过 update() 方法来更新 col_1 集合中的 title
$set 操作符为部分更新操作符,只更新 $set 之后的数据,而不是覆盖之前的数据
db.col_1.update({ 'title': 'MongoDB 教程' }, { $set: { 'title': 'MongoDB' } })
以上语句只会修改第一条发现的文档,如果要修改多条相同的文档,则需要设置 multi 参数为 true。
db.col_1.update({ 'title': 'MongoDB 教程' }, { $set: { 'title': 'MongoDB' } }, { multi: true })
查询
db.col_name.find().find() 方法,它返回集合中所有文档。
db.col_name.find().findOne() 方法,它只返回一个文档。
db.col_name.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
db.col_name.find().pretty() --格式化输出
db.col_name.find().count() --查看集合中文档的个数
db.col_name.find().skip().limit() --读取指定记录的条数
排序:
sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
db.col_name.find().sort({key:1})
Where 语句
如果你想获取"col"集合中 "likes" 大于100,小于 200 的数据,你可以使用以下命令:
db.col.find({likes : {$lt :200, $gt : 100}})
Select * from col where likes>100 AND likes<200; --类似于SQL语句
Mongodb索引基础
- 创建索引:
db.test.ensureIndex({name:1})、
db.test.ensureIndex({name:-1})
db.test.ensureIndex({date:-1,name:1}) // 1 为指定按升序创建索引,-1 为按降序来创建索引
- 内嵌文档的索引:
db.test.ensureIndex({blog.title:1})
- 索引名称:
db.test.ensureIndex({name:1},{name:”myIndex”});
- 唯一索引:
db.test.ensureIndex({name:1},{unique:true}); // 默认情况下insert并不检,查文档是否插入过
- 修改索引:
db.test.ensureIndex({name:-1},{background:true})
- 查看索引:
db.test.getIndex()
- 删除索引:
db.runCommand({dropIndexes:”test”,index:”*”})
db.runCommand({dropIndexes:”test”,index:”myIndex”})
- 建立索引时要考虑如下问题:
- 会做什么样的查询?其中那些键需要索引?
- 每个键的索引方向是怎么样的?
- 如何应用扩展?有没有种不同的键的排列可以使常用数据更多的保存在内存中?
Mongodb练习题
-
将下面的信息写入到mongodb中的students的集合中
name: xiaohong ,age:14 ,sex:女,hobby:看书、音乐、画画db.students.insert({name:”xiaohong”,age:14,sex:”女”,hobby:[”看书”,”音乐”,”画画”]}); -
查看students集合中所有age为14 的文档信息
db.students.find({age:14}); -
查看students集合中所有age大于7并且小于 14 的文档信息
db.students.find({age:{$gt:7,$lt:14}); -
删除students集合中所有age为12的文档
db.students.remove({age:12}); -
将students中name为xiaomi的age修改为13
db.students.update({name:”xiaomi”},{$set:{age:13}});