在此得感谢一位博主写的博客,他园子的地址路径:https://www.cnblogs.com/zhaof/p/6897393.html
一.什么是爬虫:
网络爬虫:又叫网络蜘蛛,网络机器人等,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。就是通过程序去获取Web页面上自己想要的数据,及自动抓取数据。
二.爬虫可以做什么:
爬取能够通过浏览器访问的一切数据(资源什么的,吭吭吭......)
三.爬虫的本质:
模拟浏览器打开Web页面获取我们想要的资源。
(
了解:浏览器打开网页的过程:
在浏览器输入地址——>经DNS服务器找到服务器主机——>向服务器发送请求——>服务器经解析返回给
用户浏览器结果(html,js,css等文件内容)——>浏览器经解析,以HTML代码构成了网络页面
爬虫的任务: 通过分析和过滤HTML代码,获取服务器返回的(html,js,css等文件内容)。
)
四.爬虫的基本流程:
①:发起请求:通过HTTP库向目标站点发起请求,也就是发送一个Request,请求可以包含额外的header()等信息,等待服务器响应
②:获取响应内容:如果服务器能正常响应(返回值判断),会得到一个Response(实质上是一个文件对象),Response的内容便是所要获取的页面内容,类型可能是HTML,Json字符串,二进制数据(图片或者视频)等类型
③:解析获取的内容(转换可以使用某些方法能够提取的数据类型):内容可能是HTML,可以用正则表达式,页面解析库进行解析,可能是Json,可以直接转换为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理
④:保存数据:保存到文本,数据库,或某种格式的文件
五.Request和Reaponse:
1.概述:
①Request:浏览器发送消息给所在网址的服务器这过程,叫做HTTP Request
②Response:服务器收到浏览器所发消息,然后根据消息做相应的处理,然后返回消息传回浏览器的过程,叫做HTTP Response
2.Request包含的内容:
①请求方式:GET/POST两种类型常用(区分优缺点,此处不做详细说明)
②请求URL(统一资源占位符,常称作网址):互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
③请求头:包含请求时的头部信息,如User-Agent,Host,Cookies等信息,以下是请求qq浏览器时,请求头包含的全部信息:
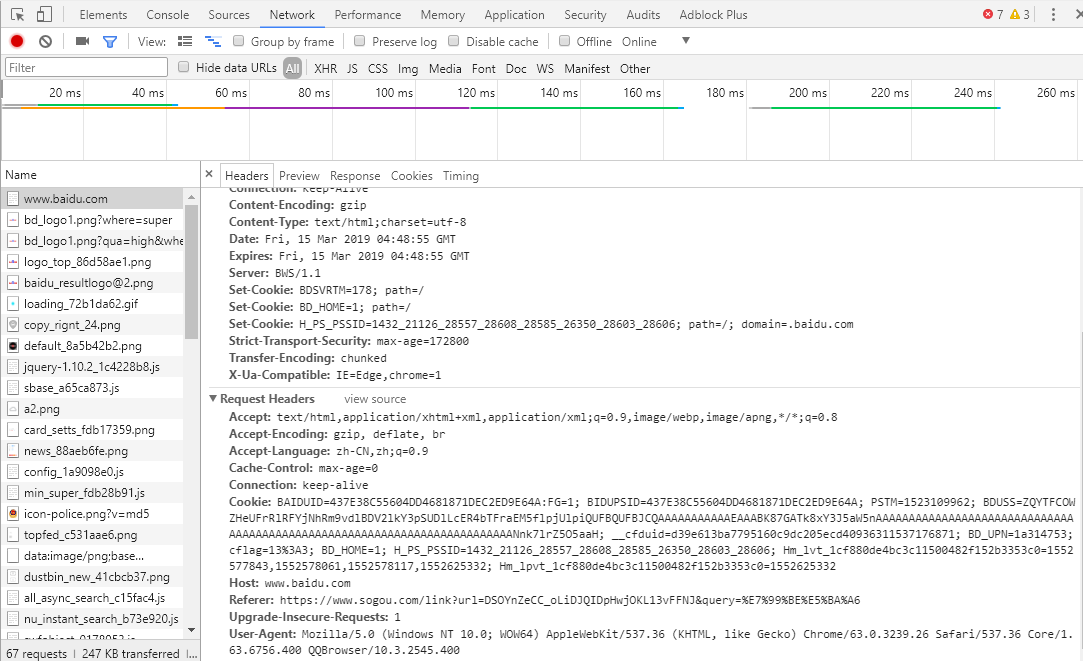
④请求体:包含一些信息的对象
3.Response包含的内容:
①响应状态(第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔):200代表成功,301跳转,
404找不到页面,502服务器错误
②响应头:如内容类型,类型的长度,服务器信息 设置Cookie
③响应体:最主要的部分,包含请求资源的内容,如网页HTMl,图片,二进制数据等