选择题

解析:在for循环的循环条件
(y = 123) && (x < 4)中 ,&&表示逻辑与,从左向右判断两边条件是否成立,只有当两边的条件都为真时,这条语句才为真。左边y = 123是赋值语句,一直为真;右边x<4刚开始也为真,随着x++,当x=4的时候x<4条件不成立,那么(y = 123) && (x < 4)这条语句为假,循环结束。所以x从0到3能够执行循环,当x等于4的时候循环结束,一共执行4次。

解析:本题考查
printf的格式化输出。printf可以在%和格式字符(s,d,f等)中间插入格式修饰符,用于指定输出数据的域宽(字宽,所占的列数),如用“%5d”,指定输出数据占5列,输出的数据在域内向右靠齐,可以在在指定域宽前加-表示向左靠齐,如"%-5d",表示输出的数据在域内向左靠齐。在使用f格式符时,可以指定数据宽度和小数位数,用%m.nf其中,m表示输出数据的宽度,即占m列,n表示小数点后保留n位小数。(若不需强调输出数据宽度,可直接用%.nf)。本题中“%5.3s”表示字宽为5,小数点后面的是精度,这里的3表示打印3个字符,在域内向右对齐,所以前面要有2个空格。
解析:本题中for循环判断条件中,
j = 0是赋值语句,那么该循环将会出现无限循环或者一次也不循环的情况。
解析:本题考查逻辑与
&&与逻辑或||,他们都是从左向右进行真假判断的。(a == 1 && b++==2)中a == 1为真,b++==2中++为后置,先使用再++,所以b++==2也为真,所以(a == 1 && b++==2)这条语句为真,++之后b=3;进入之后的判断语句(b!=2||c--!=3)中,因为是||,所以只要一个为真就为真,上面得到b=3所以b!=2为真,不用再进行c--!=3真假的判断。所以输出结果为1,3,3。

解析:本题主要考查类型提升,题目中的类型中
double为最高值,所以最后计算结果的类型就是double类型。

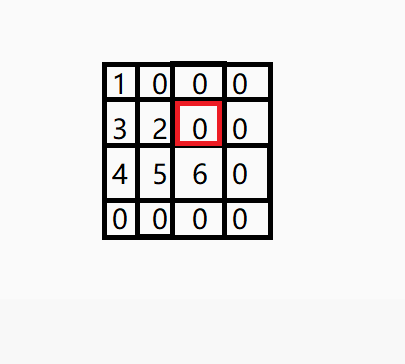
解析:本题考查二维数组的概念。二维数组的第一个
[]表示的是行数,第二个[]表示的是列数,可以不指定行数,但是二维数组的列数必须指定。本题中二维数组p是4行4列,可用下图表示。p[1][2]表示第2行第3列,由下图可知为0。
解析:本题考查或
|,有一个为真即为真,是对二进制数值进行计算,正数的原码、反码和补码相同,可以直接换算成二进制计算。
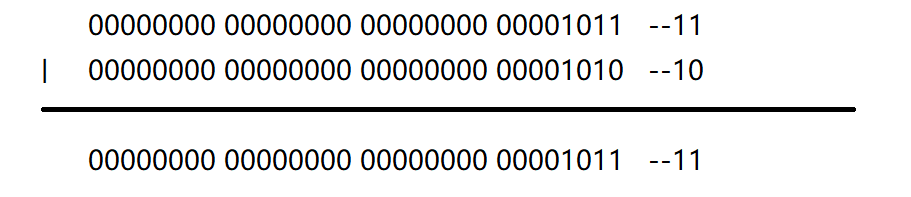

解析:本题考查的是左移位操作符,移动的是二进制位。
<<左移位操作符,后面补0;>>右移位操作符,前面补符号位。可以理解为左移n位,就是扩大2n倍;右移n位,就是缩小2n倍。1<<5变为32,-1之后为31,a=21,^为按位异或,计算方法是:同为假,异为真,也是二进制位运算:

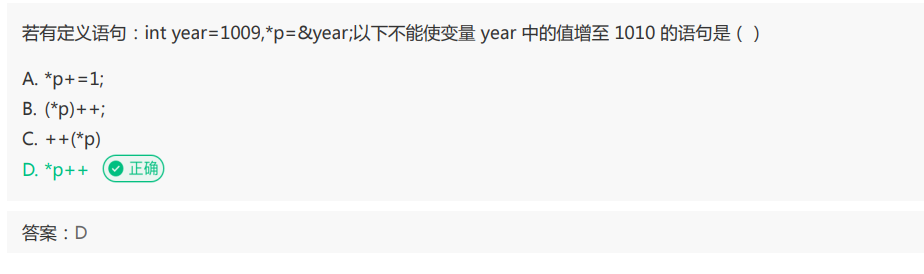
解析:本题考查指针及前置++和后置++的用法。前置++是先++再使用;后置++是先使用再++。A中
*p+=1可以表示为*p=*p+1,p是指向year的指针,所以*p表示的就是year的值,*p的改变也会引起year的改变;B中也是对*p进行++,可以改变year的值;C中使用前置++改变*p的值,可以改变year的值;D中*p++相当于*(p++),改变的是p指针并没有改变year。
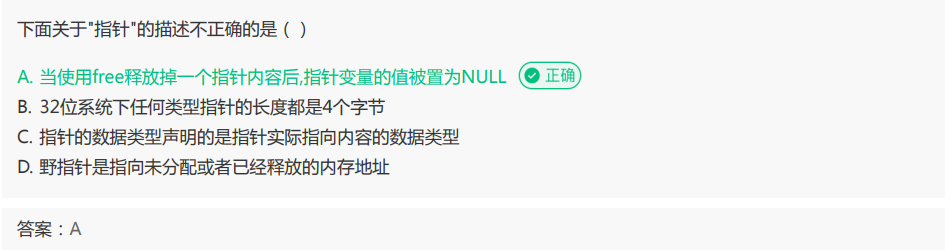
解析: free只是对在堆上开辟的空间进行释放,并不会把指针变量的值置为NULL; 32位系统下任何类型指针的长度都是4个字节,64位系统下任何类型指针的长度都是8个字节;指针的数据类型声明的是指针实际指向内容的数据类型;野指针是指向未分配或者已经释放的内存地址。
编程题
1.组队竞赛
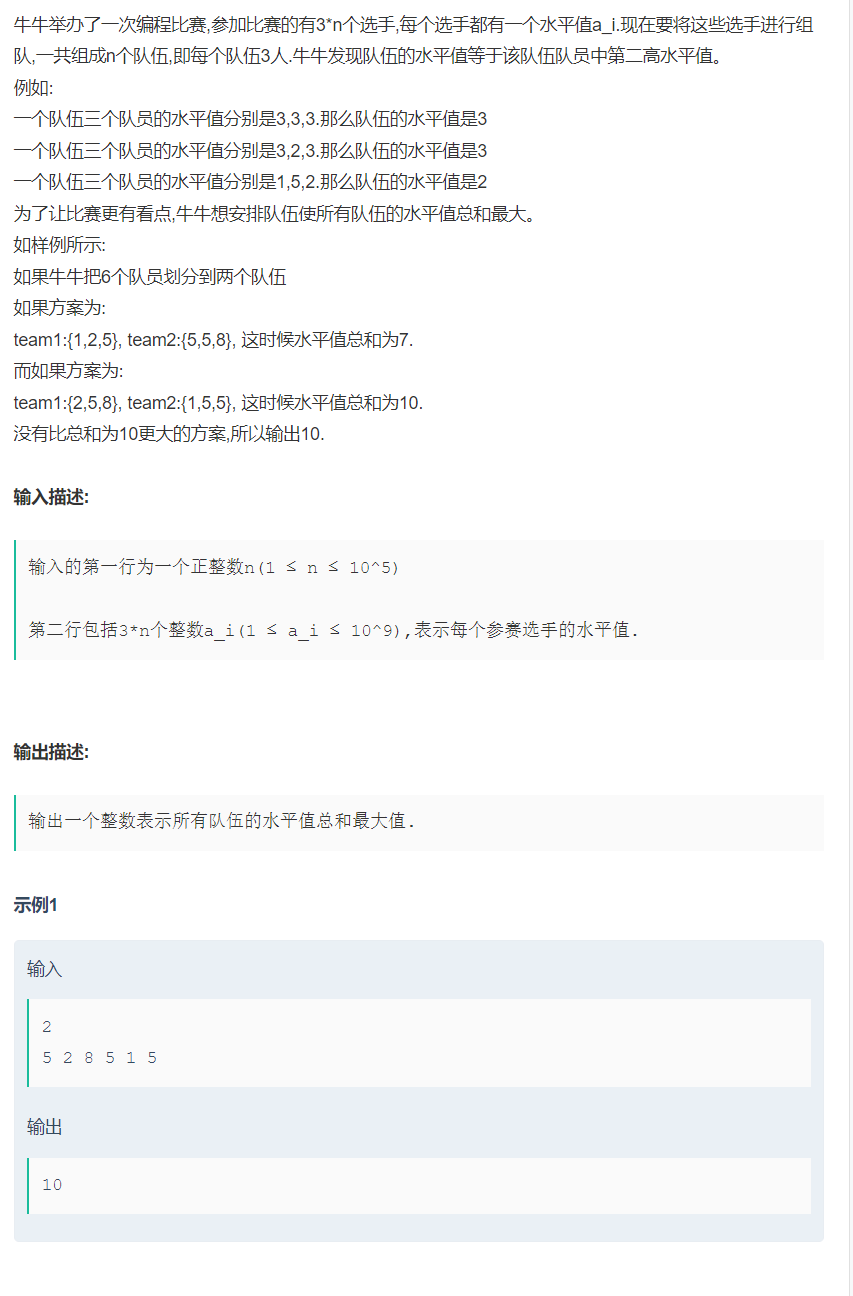
解析:假设总共有9个参赛选手,他们的水平值经过sort排序后为:1 2 3 4 5 6 7 8 9 。当1,8,9为一个队伍,2, 6,7为一个队伍,3, 4,5为一个队伍的时候,队伍的水平值为 8,6,4;此时队伍水平值总和最大,为18。假设数组元素个数为vv.size, sort排完序后数组元素8的下标为[vv.size - 2],6的下标为[vv.size - 4],4的下标为[vv.size - 6], 此例中队伍个数nums是3,参赛选手个数即数组元素个数vv.size为9,(vv.size -1)得到的是数组中最后一个元素的下标 , (vv.size -2) 得到的是当1,8,9这个队伍中的水平值,每次-2可得到各队伍的水平值,依次得到 8 6 4。注意计算输出结果的时候数据类型使用long long。
#include <iostream>
#include <vector>//vector的头文件
#include <algorithm>//sort的头文件
using namespace std;//展开命名空间
int main()
{
int _nums = 0;
cin >> _nums;
vector<int> vv;
vv.reserve(3*nums);//开辟空间,指定空间大小
//reverse开辟空间,并不会初始化,不改变size大小,所以不能使用vv.size()
//for(int i = 0; i < vv.size(); i++)
for(int i = 0; i < 3 * nums; i++)
{
//因为数组长度未知,不能直接使用cin >> vv[i]
int t = 0;
cin >> t;
vv.push_back(t);//尾插,插入数据
}
sort(vv.begin(),vv.end());//排序
long long sum = 0;
int j = 0;
for(int i = (vv.size()-2); i >= 0; i -= 2)
{
if(j < _nums)//查看队伍个数
{
sum += vv[i];
j++;
}
else
break;
}
cout << sum;
return 0;
}
答案解析:队伍的水平值等于该队伍队员中第二高水平值,为了所有队伍的水平值总和最大的解法,也就是说每个队伍
的第二个值是尽可能大的值。所以实际值把最大值放到最右边,最小是放到最左边。
【解题思路】:
本题的主要思路是贪心算法,贪心算法其实很简单,就是每次选值时都选当前能看到的局部最解忧,所以这里的贪心就是保证每组的第二个值取到能选择的最大值就可以,我们每次尽量取最大,但是最大的数不可能是中位数,所以退而求其次,取 每组中第二大的
例如 现在排序后 有 1 2 5 5 8 9 ,那么分组为1 8 9 和 2 5 5
关系arr[arr.length-2*(i+1)]
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main() {
int n = 0;
// IO型OJ可能会有多组测试用例,所以这里要持续接收输入多组测试用例。
while(cin >> n)
{
long long sum = 0;
vector<int> v;
v.resize(3*n);
for(int i = 0; i < v.size(); i++)
{
cin >> v[i]; //输出各个值
}
sort(v.begin(),v.end()); //从低到高排序
for(int i = 0; i < n; i++) //设置循环条件为队伍个数
{
sum += v[v.size() -( (i + 1) * 2)]; //将各个队伍的第二水平高的值加起来
}
/*greater<int> g; //也可以考虑用升序的方式找
sort(v.begin(),v.end(),g);
for(int i = 0; i < n; i++)
{
sum += v[(i * 2) + 1];
}*/
cout << sum;
}
}
// 64 位输出请用 printf("%lld")
2.删除公共字符
解析:使用string类实例化两个字符串,需要使用getline函数输入字符串,因为C++中使用cin输入字符串遇到空格只会保留空格之前的,遇到回车的时候停止。通过将输入的第一个字符串中的每个字符依次分别和第二个字符串中的元素进行比较,如果遇到相同的字符,则直接删除掉第一个字符串中的字符元素,并继续比较。
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
string s1;//第一个字符串
string s2;//第二个字符串
getline(cin,s1);
getline(cin,s2);
for(int i = 0; i < s2.size(); i++)
{
// while(s1.find(s2[i]) != string::npos) //查找失败返回npos
// {
// //找到之后删除
// s1.erase(s1.find(s2[i]),1);
// }
for(int j = 0; j < s1.size(); j++)
{
if(s1[j] == s2[i])
{
//找到之后直接用erase删除
s1.erase(j, 1);
}
}
}
cout << s1;
return 0;
}
答案解析:本题如果使用传统的暴力查找方式,如判断第一个串的字符是否在第二个串中,在再挪动字符删除这个字符
的方式,效率为O(N^2),效率太低,很难让人满意。
- 将第二个字符串的字符都映射到一个hashtable数组中,用来判断一个字符在这个字符串。
- 判断一个字符在第二个字符串,不要使用删除,这样效率太低,因为每次删除都伴随数据挪动。这里可
以考虑使用将不在字符添加到一个新字符串,最后返回新新字符串。
#include<iostream>
#include<string>
using namespace std;
int main()
{
// 注意这里不能使用cin接收,因为cin遇到空格就结束了。
// oj中IO输入字符串最好使用getline。
string str1,str2;
//cin>>str1;
//cin>>str2;
getline(cin, str1);
getline(cin, str2);
// 使用哈希映射思想先str2统计字符出现的次数
int hashtable[256] = {0};
for(size_t i = 0; i < str2.size(); ++i)
{
hashtable[str2[i]]++;
}
// 遍历str1,str1[i]映射hashtable对应位置为0,则表示这个字符在
// str2中没有出现过,则将他+=到ret。注意这里最好不要str1.erases(i)
// 因为边遍历,边erase,容易出错。
string ret;
for(size_t i = 0; i < str1.size(); ++i)
{
if(hashtable[str1[i]] == 0)
ret += str1[i];
}
cout<<ret<<endl;
return 0;
}