print的格式
转义字符\可以转义很多字符,比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\表示的字符就是\,这一点跟其他常用语言一致。
如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python还允许用 r 表示’'内部的字符串默认不转义,如
print('\\\t\\')
print(r'\\\t\\')
输出结果为
\ \
\\\t\\
python用 … 输出多行内容,如
print('''line1
line2
line3''')
输出结果为
line1
line2
line3
python无法像C#的const或者readonly那样定义常量,只能约定用大写作为常量,值依然可以改变
PI = 3.14159265359
python有两种除法,一种是/,另一种是//
/结果不取整,//结果取整 ,如:
print(10/3)
print(10//3)
结果为
3.3333333333333335
3
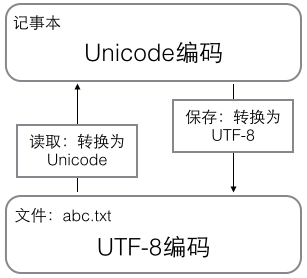
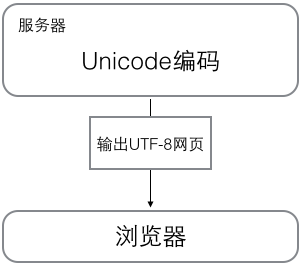
编码关系
ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符’0’和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间
文章引用自廖雪峰教程
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000