title: HashMap解析(一):hash(key)
date: 2019-03-07 19:44:54
categories:
- Java基础
tags: - HashMap
- 容器类
HashMap解析(一):hash(key)
引言
HashMap是Map接口的一个实现类,它的实现方式利用了hash,使用了数组链表的形式来存储数据,HashMap内部维护了一个Node<k,v>类型的数组table(哈希表),每个元素table[i]指向一个单向链表,根据键存取值,通过相应的运算得到数组中的索引位置,然后再操作table[i]指向的单向链表。这个数组在初次使用的时候会被初始化,并且,数组长度为2的次方数。
transient Node<K,V>[] table;
在HashMap中,它是一种数组链表的形式,每个存入的元素被包装成一个Node,Node是一个内部类,源码如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
在
Node中,维护了节点元素、元素的key、key的hash值,以及下一个节点next,这种方式就构成了一个单向链表的形式。
hash(key)
先来看看put方法:
public V put(K key, V value) {
//计算出key的hash值,一起传入
return putVal(hash(key), key, value, false, true);
}
方便讲解,直接给出结论。
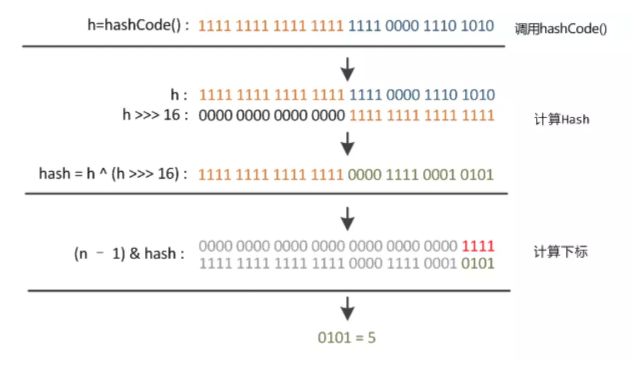
向HashMap中put、get、remove元素时,是根据节点的key的hash值来对哈希表进行操作的,那是如何通过hash值来进行索引的呢,先看看hash(key)的源码:
//由节点的key值计算
static final int hash(Object key) {
int h;
//若key为null,则hash值为0,所以在HashCode中key值可以为空;
// 否则,将key的hashcode值与hashcode的右移16位进行异或
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
------------------------------------------
//根据hash值取得对应的节点
tab[i = (n - 1) & hash]
计算过程如下:
了解了hash值的计算过程以及如何存取节点到数组中后,应该要知道为什么需要这样来建立索引?
因为数组索引是由hash值确定的,所以最重要的就是避免hash冲突,即以上的这些对hashCode的操作都是为了避免hash冲突,使节点在数组中分布均匀。
针对这个计算过程,提出三个问题(此处参考原PO)
1.为什么不直接采用经过hashCode()处理的哈希码作为存储数组table的下标位置?
2.为什么采用哈希码与运算(&)(数组长度-1)计算数组下标?
3.为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
第一个问题
因为直接算出来的hashCode值是2进制的32位数,要是直接使用这个数的话,就可能会出现hashCode的值远远大于数组实际元素个数,这样节点分布就会极不均匀,并且也浪费了大量的空间,所以,采用哈希码与运算(&)(数组长度-1)计算数组下标。
第二个问题
1.数组长度-1
数组长度=2的幂=(二进制表示)100…00的形式=首位为1、后面均为0。要是直接去&哈希码,会有如下几个后果。
(1)算出的下标值就会集中于某几位,这样增大了hash冲突的可能性。
(2)数组长度为偶数,最后一位0,&出结果肯定为偶数,这样浪费了一半空间,而且也增大了hash冲突的可能性。
(数组长度-1)=(二进制表示)011…11的形式=首位为0、后面均为1。
(1)这样&出的结果,就会由hash码的低位来决定,并且最后一位为1,&出的结果是奇数还是偶数,由hash码的最后以为决定。
2.&运算
hash码与运算数组长度 实际上=将hash值对数组长度取模,减小索引的值。为了提高效率,采用位运算&,只有但数组长度=2的幂次方时,h&(n-1)才等价与h%n。

这样做的结果,都是为了让&出的结果,由hash码来控制,能让结果更加的均匀。
第三个问题
因为一般数组长度只会对应hash码的后几位,这样求出的结果也会易造成hash冲突,经过移位运算,得到的hash码更加均匀,提高了数组索引的随机性和均匀性。