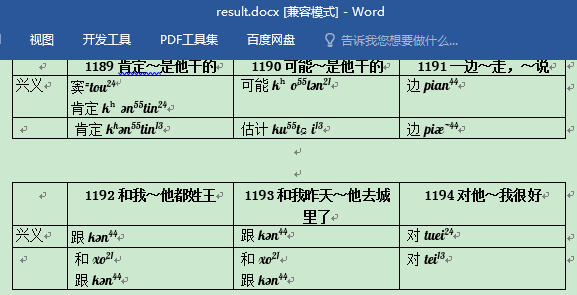
大家好,我是小小明,今天我要给大家分享的是两个word文档处理的案例,核心是读取excel的数据,按照指定的规则写入到word中。
之前们已经分享过一些pandas读写excel的例子,这次我们需要在此基础上还需读写word文档。
python-docx简介
利用python读写word文档的库是python-docx,安装:
pip install python-docx
python-docx 官方文档: https://python-docx.readthedocs.io/en/latest/
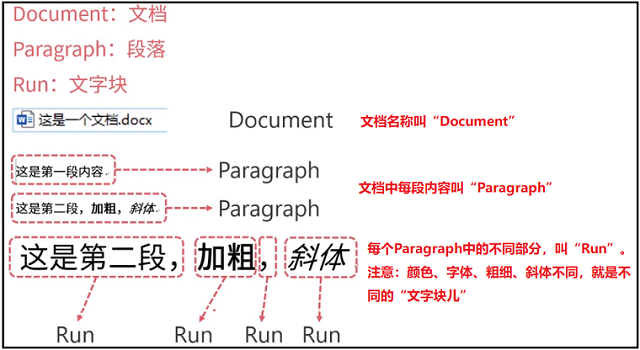
基本的对象关系:
单字字音分析处理
之前遇到一个需求:
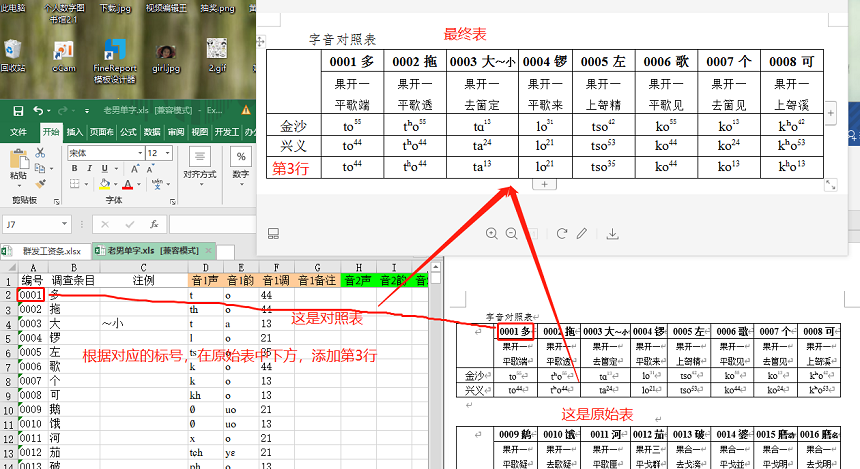
分析需求呢,会发现它要求在word文档中添加一行在excel对应的声韵调,若音1声超过1个字符还需将最后一个字符上标,音1韵不上标,音1调需整体上标。
为了解决这个问题,首先我们需要处理出我们需要的数据,每个单字对应的字音(音韵声)。
自然第一步是读取excel文件,最终产生以调查条目为键,声韵调作为值的字典,而音1声超过1个字符需将最后一个字符上标,所以音1声应该把不需上标和需要上标的分开存储,最终形成一个四元组。
看看代码吧:
数据读取
import pandas as pd
df = pd.read_excel("老男单字.xls", usecols=[0, 1, 3, 4, 5], dtype={
'编号': 'str'})
df.head()
| 编号 | 调查条目 | 音1声 | 音1韵 | 音1调 |
|---|---|---|---|---|
| 0001 | 多 | t | o | 44 |
| 0002 | 拖 | th | o | 44 |
| 0003 | 大 | t | a | 13 |
| 0004 | 锣 | l | o | 21 |
| 0005 | 左 | ts | o | 35 |
单字对应的字音字典生成
symbols = {
}
for row in df.values:
k = row[1]
a = row[2].strip()
if len(a) > 1:
v = (a[:-1], a[-1], row[3].strip(), str(row[4]))
else:
v = (a, "", row[3].strip(), str(row[4]))
symbols[k] = v
利用pandas查看生成结果:
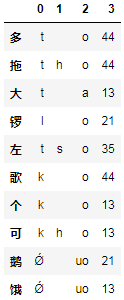
pd.DataFrame.from_dict(symbols, 'index').head(10)
测试数据匹配
好,接下来,我们尝试读取word文档的第一个表格,并匹配获取每个字音需要添加的音韵调:
from docx import Document
doc = Document(r"01老男单字字音对照表(兴义).docx")
header_cells = doc.tables[0].rows[0].cells[1:]
for cell in header_cells:
k = cell.text[5]
print(cell.text, symbols[k])
打印结果:
0001多 ('t', '', 'o', '44')
0002拖 ('t', 'h', 'o', '44')
0003大~小 ('t', '', 'a', '13')
0004锣 ('l', '', 'o', '21')
0005左 ('t', 's', 'o', '35')
0006歌 ('k', '', 'o', '44')
0007个 ('k', '', 'o', '13')
0008可 ('k', 'h', 'o', '13')
说明数据匹配暂时没有问题。
测试添加数据
然后尝试向第一个表格添加数据,并保存看看效果:
from docx.enum.text import WD_ALIGN_PARAGRAPH
doc = Document(r"01老男单字字音对照表(兴义).docx")
header_cells = doc.tables[0].rows[0].cells[1:]
row_cells = doc.tables[0].add_row().cells[1:]
for header_cell, row_cell in zip(header_cells, row_cells):
k = header_cell.text[4]
a, b, c, d = symbols[k]
(p,) = row_cell.paragraphs
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
p.style.font.name = 'IPAPANNEW'
p.add_run(a)
p.add_run(b).font.superscript = True
p.add_run(c)
p.add_run(d).font.superscript = True
doc.save("tmp.docx")
结果:
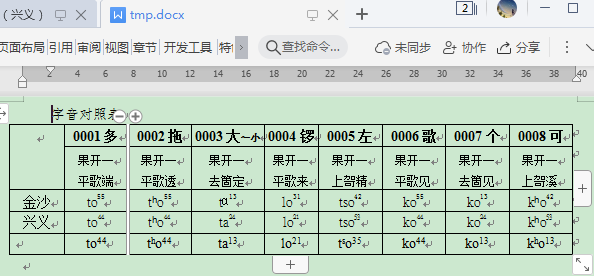
可以看到已经顺利添加进去,并没有什么问题。
最终测试
现在改下代码,添加所有单元格:
doc = Document(r"01老男单字字音对照表(兴义).docx")
for t in doc.tables:
header_cells = t.rows[0].cells[1:]
row_cells = t.add_row().cells[1:]
for header_cell, row_cell in zip(header_cells, row_cells):
k = header_cell.text[4]
a, b, c, d = symbols[k]
(p,) = row_cell.paragraphs
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
p.style.font.name = 'IPAPANNEW'
p.add_run(a)
p.add_run(b).font.superscript = True
p.add_run(c)
p.add_run(d).font.superscript = True
doc.save("result.docx")
结果:
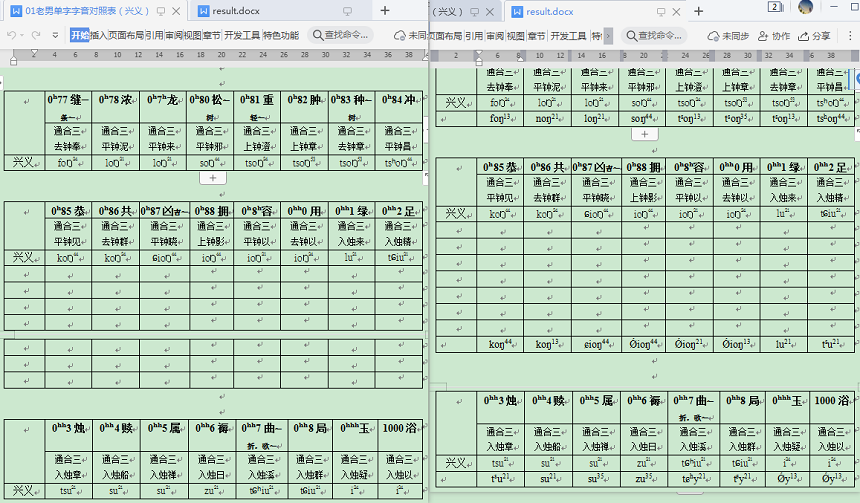
可以看到,都顺利添加了对应的字音,但有点不太满意,有部分整行都是空白单元格,应该删除更佳。
增加删除空行的代码:
doc = Document(r"01老男单字字音对照表(兴义).docx")
for t in doc.tables:
# 从第四行开始检查并去除表格的空白行
for row in t.rows[3:]:
if np.all([cell.text == "" for cell in row.cells]):
t._tbl.remove(row._tr)
# 取出第一行从第二个开始所有单元格
header_cells = t.rows[0].cells[1:]
# 取出新增一行从第二个开始所有单元格
row_cells = t.add_row().cells[1:]
for header_cell, row_cell in zip(header_cells, row_cells):
k = header_cell.text[4]
a, b, c, d = symbols[k]
(p,) = row_cell.paragraphs
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
p.style.font.name = 'IPAPANNEW'
p.add_run(a)
p.add_run(b).font.superscript = True
p.add_run(c)
p.add_run(d).font.superscript = True
doc.save("result.docx")
再次执行,office打开的结果:
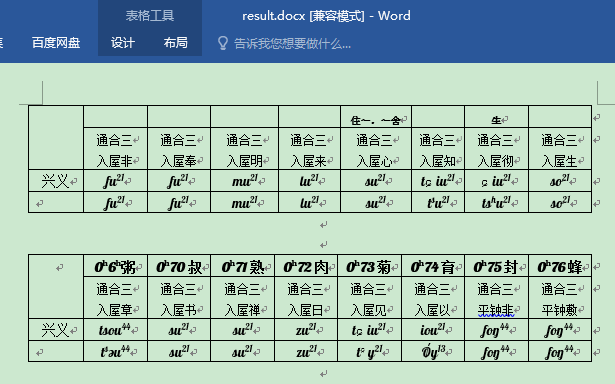
可以看到空行已经都顺利的被删除。
完整处理代码
整个过程已经完整测试通过,最终完整处理代码为:
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx import Document
import pandas as pd
import numpy as np
df = pd.read_excel("老男单字.xls", usecols=[1, 3, 4, 5])
symbols = {
}
for row in df.values:
k = row[0]
a = row[1].strip()
if len(a) > 1:
v = (a[:-1], a[-1], row[2].strip(), str(row[3]))
else:
v = (a, "", row[2].strip(), str(row[3]))
symbols[k] = v
doc = Document(r"01老男单字字音对照表(兴义).docx")
for t in doc.tables:
# 从第四行开始检查并去除表格的空白行
for row in t.rows[3:]:
if np.all([cell.text == "" for cell in row.cells]):
t._tbl.remove(row._tr)
# 取出第一行从第二个开始所有单元格
header_cells = t.rows[0].cells[1:]
# 取出新增一行从第二个开始所有单元格
row_cells = t.add_row().cells[1:]
for header_cell, row_cell in zip(header_cells, row_cells):
k = header_cell.text[4]
a, b, c, d = symbols[k]
(p,) = row_cell.paragraphs
p.alignment = WD_ALIGN_PARAGRAPH.CENTER
p.style.font.name = 'IPAPANNEW'
p.add_run(a)
p.add_run(b).font.superscript = True
p.add_run(c)
p.add_run(d).font.superscript = True
doc.save("result.docx")
词汇音分析处理
需求2:
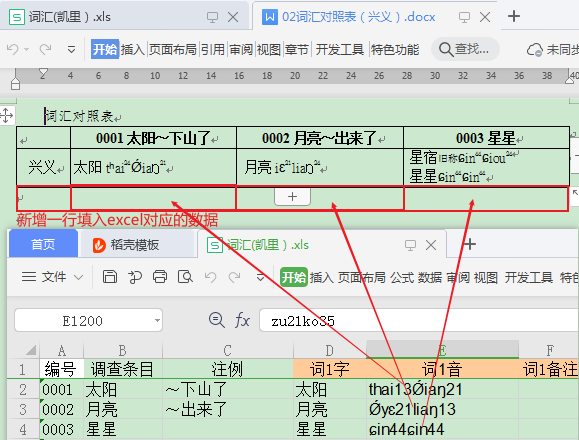
当然有部分词汇存在两个词就需要换行都写入:
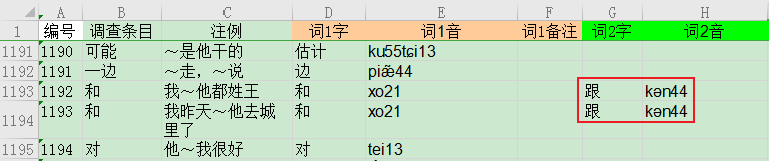
上标规则是所有的数字和h都上标,其他不用上标。
那同样的思路,先读取excel并解析出需要的数据:
数据读取并解析
import pandas as pd
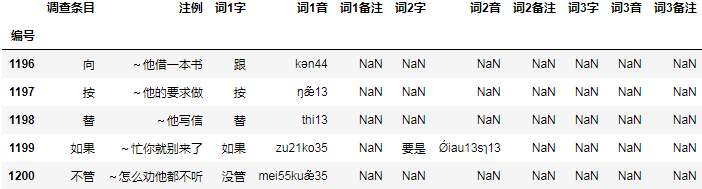
df = pd.read_excel("词汇(凯里).xls", index_col=0)
df.tail()
结果:
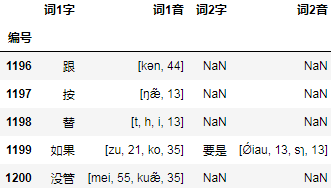
# 词音按照不是h而且不是数字,以及是h,和是数字 三种规则切分
df['词1音'] = df['词1音'].str.findall("[^h\d]+|h|\d+")
df['词2音'] = df['词2音'].str.findall("[^h\d]+|h|\d+")
df = df[["词1字", "词1音", "词2字", "词2音"]]
df.tail()
结果:
最终想得到的处理结果:
symbols = df.to_dict('index')
word文档编号转换测试
运行以下代码:
from docx import Document
doc = Document(r"02词汇对照表(兴义).docx")
i = 0
for t in doc.tables:
# 取出第一行从第二个开始所有单元格
header_cells = t.rows[0].cells[1:]
for header_cell in header_cells:
k = int(header_cell.text[:4].replace('ʰ', '9'))
未发现任何报错,说明对应编号获取成功,于是就可以通过将键k传入symbols获取需要写入的数据。
最终word生成代码
from docx import Document
doc = Document(r"02词汇对照表(兴义).docx")
for t in doc.tables:
# 取出第一行从第二个开始所有单元格
header_cells = t.rows[0].cells[1:]
# 取出新增一行从第二个开始所有单元格
row_cells = t.add_row().cells[1:]
for header_cell, row_cell in zip(header_cells, row_cells):
k = int(header_cell.text[:4].replace('ʰ', '9'))
symbol_dict = symbols[k]
if not pd.isna(symbol_dict['词2字']):
row_cell.add_paragraph()
for i, p in enumerate(row_cell.paragraphs, 1):
p.style.font.name = 'IPAPANNEW'
p.add_run(symbol_dict[f'词{i}字']).font.name = "宋体"
for n, e in enumerate(symbol_dict[f'词{i}音']):
run = p.add_run(e)
if n % 2 == 1:
run.font.superscript = True
doc.save("result.docx")
完整处理代码
from docx import Document
import pandas as pd
df = pd.read_excel("词汇(凯里).xls", index_col=0)
# 词音按照不是h而且不是数字,以及是h,和是数字 三种规则切分
df['词1音'] = df['词1音'].str.findall("[^h\d]+|h|\d+")
df['词2音'] = df['词2音'].str.findall("[^h\d]+|h|\d+")
df = df[["词1字", "词1音", "词2字", "词2音"]]
symbols = df.to_dict('index')
doc = Document(r"02词汇对照表(兴义).docx")
for t in doc.tables:
# 取出第一行从第二个开始所有单元格
header_cells = t.rows[0].cells[1:]
# 取出新增一行从第二个开始所有单元格
row_cells = t.add_row().cells[1:]
for header_cell, row_cell in zip(header_cells, row_cells):
k = int(header_cell.text[:4].replace('ʰ', '9'))
symbol_dict = symbols[k]
if not pd.isna(symbol_dict['词2字']):
row_cell.add_paragraph()
for i, p in enumerate(row_cell.paragraphs, 1):
p.style.font.name = 'IPAPANNEW'
p.add_run(symbol_dict[f'词{i}字']).font.name = "宋体"
for n, e in enumerate(symbol_dict[f'词{i}音']):
run = p.add_run(e)
if n % 2 == 1:
run.font.superscript = True
doc.save("result.docx")
最终结果: