自定义类型包括:结构体,枚举,联合体
结构是一些值的集合,这些值被称为成员变量.结构的每个成员可以是不同类型的变量.但反过来说结构体就是一个独立的变量,它是一个自定制类型.
结构体声明struct tag{member -list;}variable -list;
结构体内引用自身需要用到结构体指针
结构体一般定义方法举例typedef struct s1{int x;int y; }p1;
结构体变量的定义和初始化
struct point{int x;int y;}p1; //声明类型的同时定义变量p1struct point p2
//定义结构体变量p2
//初始化:定义变量的同时赋初值.struct point p3={x,y};
struct node
{data;struct point p;struct node* next;}
n1={10,{4,5},NULL};
//结构体嵌套初始化
结构体内存对齐第一个成员在与结构体变量偏移量为0的地址处2其他成员变量要对齐到某个数字(对其数)的整数倍的地址处对其数=编译器默认的一个对其数与该成员大小的较小值3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数) 的整数倍.为了加快数据存取的速度,编译器默认情况下会对结构体成员和结构体本身存储位置进行处理,使其存放的起始地址是一定字节数的倍数,而不是顺序存放,称为字节对齐.
分析例子B;struct B{char b;int a;short c;};
假 设B从地址空间0x0000开始排放。该例子中没有定义指定对齐值,在笔者环境下,该值默认为4。第一个成员变量b的自身对齐值是1,比指定或者默认指定 对齐值4小,所以其有效对齐值为1,所以其存放地址0x0000符合0x0000%1=0.第二个成员变量a,其自身对齐值为4,所以有效对齐值也为4, 所以只能存放在起始地址为0x0004到0x0007这四个连续的字节空间中,
复核0x0004%4=0,且紧靠第一个变量。第三个变量c在自身对齐值为 2,所以有效对齐值也是2,可以存放在0x0008到0x0009这两个字节空间中,符合0x0008%2=0。所以从0x0000到0x0009存放的 都是B内容。再看数据结构B的自身对齐值为其变量中最大对齐值(这里是b)所以就是4,所以结构体的有效对齐值也是4。根据结构体圆整的要求, 0x0009到0x0000=10字节(10+2)%4=0。所以0x0000A到0x000B也为结构体B所占用。故B从0x0000到0x000B 共有12个字节,sizeof(struct B)=12;
其实如果就这一个就来说它已将满足字节对齐了, 因为它的起始地址是0,因此肯定是对齐的,之所以在后面补充2个字节,是因为编译器为了实现结构数组的存取效率,试想如果我们定义了一个结构B的数组,那 么第一个结构起始地址是0没有问题,但是第二个结构呢?按照数组的定义,数组中所有元素都是紧挨着的,如果我们不把结构的大小补充为4的整数倍,那么下一 个结构的起始地址将是0x0000A,这显然不能满足结构的地址对齐了,因此我们要把结构补充成有效对齐大小的整数倍.
其实诸如:对于char型数据,其 自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,这些已有类型的自身对齐值也是基于数组考虑的,只 是因为这些类型的长度已知了,所以他们的自身对齐值也就已知了.
内存对齐在cpu层面的意义:https://blog.csdn.net/qq635075803/article/details/80300453
支持4字节的传输(单纯的假设,也就是cpu只能隔着4字节寻址),有8字节的内存依次存放着三个单字节字符、一个四字节整型和一字节空数据(char char char int32 0),那么你在用高级语言请求访问字符或者整型的时候CPU的总线操作就会相当复杂甚至出错,因为处理器不支持,但是如果事先用16个字节的空间进行内存对齐(char000 char000 char000 int32)那么就可以取出想要的数据,程序就可以正常运行。
总而言之,内存对齐规则在cpu和内存的层面上降低了时间的开销,但相应的增加了内存的空间,但 对于现在的计算机来说,存储是成本降低,我们主要考虑时间上的开销
在这里列出两种结构成员变量的声明方法struct agling
{char a;int b;char c;
}
struct agling2
{int b;char a;char b;
}2所包含的成员和前面那个结构一样,但它只占八个字节,节省了百分之三十三 两个字符可以紧挨着存储,
修改默认对齐数#pragma pack(8)
百度笔试题写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明
写出一个宏,求任意结构体成员相对于结构体首地址的偏移。#define _____________________
#define STRUCT_OFFSET(id, element) (( unsigned long ) &(( struct id*) 0 )->element)
因为是求偏移量 所以假设结构体的首地址是0开始,把他转换成结构体指针类型,在用-》取得他的成员,前面加了一个& 就是取得这个成员的地址,最后在强制转换成unsigned long,这样就得到了偏移量。
-我的理解,关键操=操作是吧0强转成结构体指针,也就是从0地址定义了个结构体,那么偏移地址也就是成员变量的地址
位段的内存分配位段成员 int unsigned int signed int 或者是char位段设计很多不确定因素,位段不跨平台原因在下 int位段被当做有符号数还是无符号数位段中的最大数目.许多编译器把位段成员的长度限制在一个整形值的长度之内,所以一个能够运行于32位整数的机器上的位段可能在16位整数机器上无法运行位段中成员在内存中是从左向右分配的还是从右 向左分配的.当一个声明指定了两个位段,第二个位段比较大,无法容纳第一个位段剩余的位时,编译器有可能把第二个位段放在内存的下一个字,也可能直接放在第一个位段后边,从而在两个内存位置的边界上形成重叠
在位段中 存在着一种分配方使得大端字节序机器和小端字节序机器两种情况所对应的成员变量的值所不同
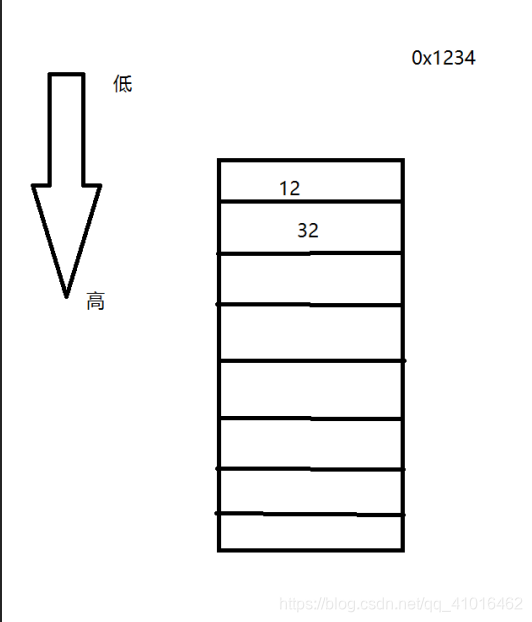
既然提到大小端字节序,我们不妨研究一下大小端字节序的规则及其规则设定的原因大端字节序:低地址存放高位,高地址存放低位(和人正常的写作习惯相同)小端字节序:高地址存放高位,低地址存放高位;(一般的机器内存方式)
大端字节序
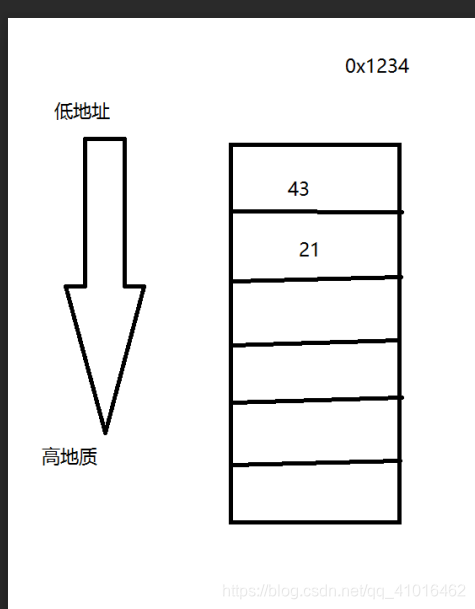
 小端字节序
小端字节序
 这里简单的概述下机器使用小段字节序的原因,因为计算机的计算通常是由低位指向高位的,也就是说一旦数据参与运算,低位先进行运算 再对高位进行运算,这时小端字节序就得到应用。但是,人类还是习惯读写大端字节序。所以,除了计算器的内部处理,其他的场合几乎都是大端口=字节序,比如网络传输和文件存储
这里简单的概述下机器使用小段字节序的原因,因为计算机的计算通常是由低位指向高位的,也就是说一旦数据参与运算,低位先进行运算 再对高位进行运算,这时小端字节序就得到应用。但是,人类还是习惯读写大端字节序。所以,除了计算器的内部处理,其他的场合几乎都是大端口=字节序,比如网络传输和文件存储
回归正题,机器的大小端对位段的成员变量的影响因为位段成员变量的内存分配在计算机中从低地址到高地址,无论是小段字节序还是大段字节序,都是如此规则。我们举个例子
#include<stdio.h>
#include<stdio.h>
int main(){
typedef unsigned int uint16_t;
struct myst
{
uint16_t a:3;
uint16_t b : 8;
uint16_t c : 5;
};
struct myst *p;
int t = 0x2041;
p = ((struct myst *)&t);
printf("%d", p->c);
system("pause");
return 0;
0x2041在大端中内存为 0010 0000 0100 00010×2041
在小端内存中为1000 0010 0000 0100
所以在小端中a为001 b为00001000 c为00100(按照电脑的思想从低地址向高地址走思考 )
所以在大端中a为001 b为00000010 c为00001(按照人的思想走)