基本概念:
主机字节序:
就是自己的主机内部,内存中数据的处理方式,可以分为两种:
大端字节序(big-endian):按照内存的增长方向,高位数据存储于低位内存中
小端字节序(little-endian):按照内存的增长方向,高位数据存储于高位内存中
网络序是大端的
深层次讨论
说起来很抽象,看图:
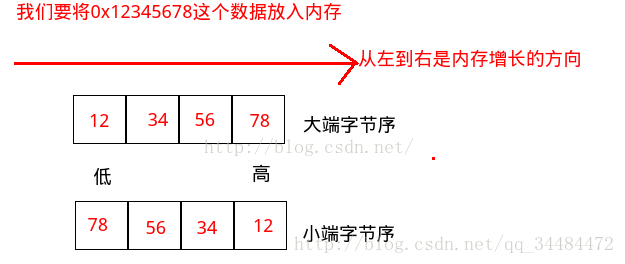
0X12345678这个数哪里是高位哪里是低位呢?显然12是高位,78是低位。一般的电脑本地都是小端模式(上图中的下半部分),这种模式显然很符合计算机的逻辑——将低位的数据放在低地址。但人习惯从左往右看数据,在这里人们首先看到的是12,最后才看到78.
数据在网络中传输是符合人的感觉的——先传送的是数据高位(在这里是12),再传送数据低位(78),这表明网络序是大端的。
这样就存在一个问题,当我从一台A主机发送到B主机时,0X12345678在A主机上存放的顺序是上图下半部分小端字节序,而我发送的时候显然是从低字节往高字节读取,那么顺序应该是78 56 34 12,但是我们说网络序是大端的,那么网络中的顺序应该是12 34 56 78 ,这两个顺序居然是反的!!!因此在发送时我们显然需要对数据进行某种处理——hston()函数能帮我做这件事,帮我们从主机序转换到网络序。
当B主机收到A主机通过网络发送过来的0X12345678这个数据时,我们刚说通过网络传输后,先发送的是高位(12),后发送的是低位(78)。先发送的B显然是先收到,他会把先收到的12放到自己的内存低位,依次放入3456,最后在收到78时放到内存的最高位。这样,在B主机内存中的数据排列顺序应该是:

如果此时B主机是小端的话,它会读成0X78563412(想想为什么?),这显然与我们期望的不同!这时候我们需要一个ntohs()帮我们从网络序转换到主机序。转换完后,我们得到的顺序应该是:

这样读出来的就是我们想要的0X12345678!
总结:
1.主机序包括大端和小端模式,网络序是大端的。
2.我们需要hston() ntohs()帮我们完成主机序和网络序之间的切换,否则顺序会乱。
3.hston() ntohs()的功能是一样的,可以混用(当时为了目的更明确,我建议不要这样),他们都是判断主机序是大端还是小端后决定是否更换顺序(网络序是大端的这是肯定的,但主机序是不确定的,虽然上述例子是将主机试做小端),更换字节顺序显然两个函数内部实现是一样的。