请你再讲一遍,关于那天,抱着盒子的姑娘和擦汗的男人
vector
使用方法
- 在使用之前啊大家一定要记住引入头文件 #include< vector>
创建
| 指定容器的元素个数 | 不指定容器的个数 | 给指定容器的附初始值 |
|---|---|---|
| vector< int> v(10); | vector< double> v; | vector < char> v(10,‘c’); |
扩张
扩张分为两种形式,一种是尾部元素扩张,我们需要用到的函数是 push_back();另外一种可以 理解为插入我们需要用到的函数是insert();使用方式如下
| 尾部扩张 | 插入 |
|---|---|
| vector< int>v; v.push_back(3); | vector< int> v(3);v.insert(v.begin()+2,8); |
访问
- 1.迭代器
- 我们在遍历的时候需要使用一个东西叫做迭代器,这个东西的作用就是通过使用它来对不同的容器进行各种各样的操作,定义一个迭代器的方法也很简单。
*使用迭代器主要是为了统一格式,用迭代器可以很大程度上隔离容器底层实现,使用时只需依赖迭代器相对统一的方法/接口。
对于vector这个容器来说定义的方法是这样的。
vector< int> :: iterator it;
常见的初始化方法是这样的。
it = v.begin();
这个地方的迭代器还真有点类似指针,甚至包括取值的方法,都是在前面加入一个*进行取址。
- 我们在遍历的时候需要使用一个东西叫做迭代器,这个东西的作用就是通过使用它来对不同的容器进行各种各样的操作,定义一个迭代器的方法也很简单。
- 2.下标
- vector的中文释义叫做不定长数组,当然可以直接使用下标进行访问了,但是这里同样也要注意不要数组越界。
- 常见的遍历方式
vector< int> v(10,3);
vecteor<int>:: itertor it;
for(it = v.begin();it!= v.end();it++)
{
cout<<*it;
}
删除
- erase()
- 使用它可以删除一个或者一段元素。使用方法如下:
vector<int > v(10,3); v.erase(v.begin()+2); //删掉第三个元素 v.erase(v.begin(),v.begin+2); //删掉从开始到第二个元素 - clear()
- 全删…就是这么简单。
v.clear();
大小
| size() | empty() |
|---|---|
| 返回数组的元素个数 | 如果向量为空,那么返回1,如果不是返回0. |
| v.size() | v.empty() |
排序算法
*这两个函数都位于#incldue< algorithm>中,小可爱们别忘了呀。
| sort() | reverse() |
|---|---|
| 默认是升序,可以通过传入不同的cmp()函数进行自定义调节 | 反转函数。 |
| sort(v.begin(),v.end(),cmp) | reverse(v.begin(),v.end()) |
- cmp函数实例:降序
bool cmp(const int &a,const int &b){
return a>b;
}
还可以自定义很多哦,返回的顺序就是你希望的排序哦。
小坑
- 在日常的使用中,经常犯得低级失误有
1.迭代器的使用,这一点新手总是容易犯错误,这里一定要注意定义迭代器时,一定要保证拼写正确,vector< int>::iterator it;
2.搞不清楚各个函数传入的参数,从而导致输入错误,这个就需要大家好好记忆一下了。
2.25第一次更新
string
使用方法
创建
- 对于string来说,这个数据类型可以理解为一种特殊的基本数据类型,包括它的很多用法也和基本数据有很多相似之处,不过值得一提的是,大家首先需要引入头文件#include< string>才能够使用它。
string s;
赋值
- 由于它是一个字符串,我们赋值的方式有两种,一种是直接输入字符串
string s;
cin>>s;
不过还有一种更加常见的赋值方式,就是把一个字符指针赋给一个字符串对象,这样做有一个好处,就是可以加快输入速度,这在一些平台上可能会卡一下。
char ss[5000];
string s ;
scanf("%s",&ss);
s=ss;
运算符号
对于string 来说,只有两个。
| + | - |
|---|---|
| 用于在末尾追加字符或字符串 | 只能针对string对象中的元素使用 |
| string s="hello "; s+=s; |
string s= “hello”; cout<<s[0]-‘h’<<endl; |
除去+号之外,还有append()函数可以直接在末尾追加一段字符。
**所有的没有属于这个对象的操作函数都是对象.f() 这样使用。但是像sort或者reserve这样的函数,使用方法则类似于f(对象) 这样使用。
遍历
- 值得一提的是string对象同样有迭代器,所有的STL都有迭代器,具体定义方式如下
** string ::iterator it;**
我们可以使用*it对他进行遍历,使用方法上文已经介绍,此处不再赘述。- 插入函数需要借助迭代器:s.insert(it+1,‘a’);
除去迭代器我们同样可以使用下标进行遍历。
- 插入函数需要借助迭代器:s.insert(it+1,‘a’);
删除
删除一个字符串我们可以直接赋空 即 s="";
我们同样可以使用erase函数对某一段赋空
长度
与vector不同,我们需要使用的函数是**length()**这个地方一定要区分.
同样可以使用的是函数empty()空返回1 非空返回0.
搜索
使用函数find()可以查找字串和某个特定字符,找到之后返回下标值(从零开始)。
如果查找不到将会返回2^32,这是一个完美的欧拉数,在计算机中往往表示无符号整数的最大值,意义经常为反应错误,溢出堆栈等。
反转
reverse()函数的返回值是void 因此写成 string s = reverse(ss.begin(),ss.end());是不对的。这个地方需要额外注意一下,它依赖于#include< algroithm>这个头文件
替换
replace()重载比较多这里举一个例子
string s = "hello ";
s.replace(3,4,"text");
这个地方代表s这个字符串从第下标为3开始连续4个字母替换成text
小结与补充
- string 同样可以使用push_back();进行字符的添加
- insert() reverse()要求传入的都是迭代器。
- string可以作为vector的一种数据类型 此时访问的方式可以使用vector[][]进行vector的string元素的元素访问
- 比较函数返回的三种情况 s.compare(ss)
| 1 | 0 | -1 |
|---|---|---|
| s的字典序比较大 | 两者相同 | s的字典序比较小 |
- 要想使用printf输出string 需要使用到c_str()函数。printf(s.c_str())
- string对象与sscanf()函数
sscanf()函数类似于正则表达式具体使用方式如下
string s1,s2,s3;
char sa[500],sb[500],sc[500];
sscanf("abcd 12kj dksjf","%s %s %s",sa,sb,sc);
s1 = sa;
s2 = sb;
s3 = sc;
- 数值转化
to_string(int/double/…)可以把其他类型转化为字符串
stoi() stof() stod() stol()等可以转换为不同的类型
2.26第二次更新
现在听的歌是周深的大鱼,嗯很喜欢
怕你飞远去 怕你离我远去 更怕你永远停留在这里
好的,今天的内容是:
set&multiset
创建与介绍
- 介绍
set是集合容器实现了红黑树的平衡二叉检索树的数据结构,并且set是不含重复元素的,一般使用set集合的主要用处是快速检索。
对它进行中序遍历之后我们可以得到一个从小到大排列的序列 - 创建集合的方式
| set | mulitset |
|---|---|
| set< int> s ; | multiset<int> s; |
这里有个值得一提的地方就是set集合默认是从小到大插入元素集合但是我们可以自定义比较函数,对插入的顺序做出规定。
例如 从大到小插入
#include<set>
#include<iostream>
using namespace std;
struct mycmp{
bool operator ()(const int &a,const int &b){
return a>b;
}
};
int main(){
set<int,mycmp> s;
s.insert(3);
s.insert(4);
s.insert(5);
set<int,mycmp> :: iterator it;
it = s.begin();
for(;it!=s.end();it++)
cout<<*it<<" ";
cout<<endl;
return 0;
}

插入与删除
| insert() | erase() | clear() |
|---|---|---|
| s.insert(a) | s.erase(element); | s.clear() |
元素检索
s.find()返回的是个迭代器,而不是下标。但是如何获取下标呢,我们可以借助函数distance(S.first(),it);获得下标值(从零开始)。
比如说像这样
#include<set>
#include<iostream>
using namespace std;
struct mycmp{
bool operator ()(const int &a,const int &b){
return a>b;
}
};
int main(){
set<int,mycmp> s;
s.insert(3);
s.insert(4);
s.insert(5);
set<int,mycmp> :: iterator it;
it = s.find(3);
cout<<distance(s.begin(),it)<<endl;
}
反向遍历与集合大小
reverse_iterator
反向遍历我们可以使用反向迭代器对数组进行反向遍历。如下
set<int> s;
s.insert(3);
s.insert(5);
s.insert(4);
set<int> :: reverse_iterator rit;
rit = s.rbegin();
for(;rit!=s.rend();rit++)
cout<<*rit;
| s.size() | 获取集合的大小 |
|---|
##特别提醒
如果传入的参数是一个结构体,则可以通过重载<操作符的方式,改变插入方式,具体实现如下
#include<set>
#include<iostream>
using namespace std;
struct info
{
info(string a,double b){
this->name = a;
this->score = b;
}
string name;
double score;
bool operator < (const info& a)const{
return a.score<score;
}
};
int main(){
set<info> s;
struct info a("jack1",58);
struct info b("jack2",68);
struct info c("jack3",59);
s.insert(a);
s.insert(b);
s.insert(c);
set<info>::iterator it;
for (it= s.begin();it!=s.end() ;it++ )
{
cout<<(*it).name<<" : "<<(*it).score<<endl;
}
}
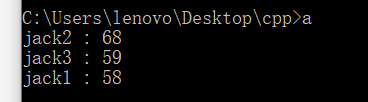
大概就是这个样子
multiset与set的联系和区别
multiset是可以存在有重的集合,他的很多性质与set几乎完全相同,这里简单说明一下。
函数erase()在multiset中返回的是被删除元素个数,find函数返回的是第一个元素的迭代器位置位置。
2月28日第三次更新
???写了一个多小时的map与multimap忘保存了???
行吧,哪怕一无所有,我也不缺从头再来的勇气。
map&multimap
创建 插入 删除与遍历和检索、结构体与应用,
全部整到一块了,有时间回来写注释。
因为是已经写了一遍的过程,所以就高度耦合一下,然后用一个例子来说明这一切
#include<map>
#include<iostream>
using namespace std;
typedef struct info
{
string name;
int score;
info(string name,int score){
this->name = name;
this->score = score;
}
bool operator<(const info& inf)const{
if (score!=inf.score)
{
return score>inf.score;
}
else {
return name<inf.name;
}
}
}nfo;
struct cmp
{
bool operator()(const char &c1,const char &c2){
return c1>c2;
}
};
typedef pair<info ,int> PAIR;
int main(int argc,char * argv[]){
map<char,int,cmp> mm;
map<char,int> m;
multimap<info,int> mp;
info a("xiaoming",84);
info a_copy("xiaomin",84);
info b("xiaogang",74);
mp.insert(PAIR(a,4));
mp.insert(PAIR(b,5));
mp.insert(PAIR(a_copy,4));
multimap<info,int>::iterator itt;
for (itt = mp.begin();itt != mp.end() ;itt++ )
{
cout<<(*itt).first.name<<" : "<<(*itt).first.score<<" : "<<endl<<"greade :"<<(*itt).second<<endl;
}
map<char,int>::iterator it;
for(int i = 0;i<10;i++){
m['0'+i] = i;
}
for (it = m.begin();it!=m.end();it++ )
{
cout<<(*it).first<<" : "<<(*it).second<<endl;
}
cout<<"-----------------------------"<<endl;
for(int i = 0;i<10;i++){
mm['0'+i] = i;
}
for (it = mm.begin();it!=mm.end();it++ )
{
cout<<(*it).first<<" : "<<(*it).second<<endl;
}
cout<<"-----------------------------"<<endl;
map<char,int,cmp>::reverse_iterator rit ;
for (rit = mm.rbegin();rit!=mm.rend() ;rit++ )
{
cout<<(*rit).first<<" : "<<(*rit).second<<endl;
}
string s = "548432184318418484321848431";
int sum = 0;
for(int i = 0;i<s.length();i++)
sum+=m[s[i]];
cout<<"sum = "<<sum<<endl;
}
学生时代的爱情,走下去需要勇气
3.1日更新
我用情付诸流水 , 爱比不爱可贵
deque
deque是双向队列容器,采用线性表顺序存储结构,deque采用分块的线性存储结构来存储数据,所有的deque块,使用一个Map块进行管理,每个Map记录各个deque块的首地址,这样一来deque快在头部和尾部都可以插入或者删除元素,当考虑到容器内存分配策略和操作性能时,deque相对vector更有优势。
creat & insert
创建deque对象的方式主要有三种:
#include<deque>
#include<iostream>
using namespace std;
int main(){
deque <int>d;
deque<int> dd(10);
deque<int> ddd(10,8.5);
for (int i =0;i<ddd.size() ;i++ )
{
cout<<ddd[i]<<" " ;
}
}
deque dd(10);
deque ddd(10,8.5);
最后一个构造情况,代表创建一个长度为10,元素为8.5的双端队列容器,但是因为规定是int类型,8.5会自动变成8传入,同时还要了解的是,队列和数组不同,我们仍然可以通过push_back()去加长它。
| insert的方法 | push_back() | push_front() | insert() |
|---|---|---|---|
| 特点 | 可以在队尾不断的添加元素,扩充队列 | 会覆盖掉原来的元素,不会添加元素 | 插入元素,但是也是覆盖而不能扩展元素 |
| 示例 | d.push_back(8); | d.push_front(8) | d.insert(d.begin()+2,3); |
遍历与删除
遍历的三种形式
| 下标 | 正向迭代器 | 反向迭代器 |
|---|---|---|
| d[i] | deque< int>::iterator it; for(it=d.begin();it!=d.end();it++) cout<<*it<<endl; |
deque< int>::reverse_iterator it; for(it=d.rbegin();it!=d.rend();it++) cout<<*it<<endl; |
删除元素的四种方式
| pop_back() | pop_front() | erase() | clear() | |
|---|---|---|---|---|
| 用处 | 删除最后一个元素 | 删除第一个元素 | 从中间删除元素 | 删除所有元素 |
| 示例 | d.pop_back() | d.pop_front() | d.erase(d.begin()+1,d.end()) | d.clear() |
#list 双向链表容器
3.1日晚,更新
哇哇哇,已经两天没有更新了…
这两天去准备补考了,唉,挂科真的麻烦,立个FLAG吧,平均分90+
list
特点
list是双向链表容器,内部实现了双向链表,因此对链表任意位置的元素进行从插入删除和查找都是极快的,list的每个节点,都有三个域,数据域,前驱元素指针域,后继元素指针域,他的头结点的前去元素指针域保存的是链表中,尾元素的首地址。
缺点
由于list对象的节点不是连续的数据域,因此导致,我们无发通过使用迭代器+3得这样的方式进行访问,但是可以使用++,–对相邻的数据域进行访问。
创建和插入
创建一个list的方法大概有两种
list <int>l;
list <int> ll (10);
插入主要有三种方式
| push_front | push_back | insert |
|---|---|---|
| 在最前面插入一个元素,自动扩张 | 在最后面插入一个元素,自动扩张 | 在制定位置插入一个元素,链表自动扩张 |
| l.push_back(8) | l.push_front(8) | l.insert(l.begin(),20) |
遍历与排序
#include<iostream>
#include<list>
using namespace std;
bool cmp(const int&a,const int&b){
return a>b;
}
int main(){
list<int> l;
for (int i = 0;i<10 ;i++ )
{
if (i%2==0)
{
l.push_back(i);
}
else
l.push_front(i);
}
list<int>::iterator it;
it = l.begin();
for (;it!=l.end() ;it++ )
{
cout<<*it<<" ";
}
cout<<endl;
l.sort(cmp);
it = l.begin();
for (;it!=l.end() ;it++ )
{
cout<<*it<<" ";
}
cout<<endl;
}
你执着的等待却不曾离开
舍不得分开在每一次醒来
不用再徘徊你就是我最美的期待
这里值得一提的是, 随机迭代器,我们注意到此处的sort和其他的STL的sort函数不同 ,主要原因,在于此处的sort来源于库文件#include< list> ,因为这个地方的迭代器不是随机迭代器,因此我们么有办法,通过使用algorithm库中的sort函数对它进行排序
**ps: 随机迭代器就是可以通过it+n进行访问的这样的迭代器。**
元素的删除与查找
| method | remove | pop_back() | pop_front() | erase() | clear | unique() |
|---|---|---|---|---|---|---|
| feature | 会删除掉所有与想要删除元素相同的元素 | 删掉队尾元素 | 删掉队列的首元素 | 删掉某个区间的元素,默认是从零开始 | 清除掉 所有的元素 | 清除所有重复的元素 |
查找函数是 find
it= find(l.begin(),l.end(),5);
此处的find函数依赖于库algorithm存在,如果没有找到返回最后的元素地址
3.5日早更新
3.6日 今天重度感冒 濒临死亡
今日更新一道算法题目
统计数字
题目如下
一本书的页码从自然数1开始顺序编码直到自然数n。书的页码按照通常的习惯编排,每个页码都不含多余的前导数字0。例如第6页用6表示而不是06或006。数字统计问题要求对给定书的总页码,计算出书的全部页码中分别用到多少次数字0,1,2,3,…9。
通过这个题目我感觉到我可能就不适合学计算机…除了暴力,咋啥都不会呢…
不管了,从这里给大家讲解一下分治法,求