Linux 是宏内核或者单内核,windows是微内核,最大的区别是所有的内核功能都被整体编译在一起,形成一个单独的内核镜像文件。 优点是效率非常的高。
Makefile:
Ifeq…else…endif
- Depmod: 更新模块的依赖信息
- Modprobe : 自动加载模块到内核 modprobe ver 不加.ko
- Modinfo lsmod dmsg -C /-c
- Mknod /dev/vers0 c 256 0
- Ls -li /dev/vers0
- 模块被卸载的前提是引用计数为0
Static : 1. 避免因为重名而带来的重复定义的问题,函数可以加载static 关键字修饰。修饰后为函数的链接属性为内部。
__init: 是把标记的函数放到ELF文件的特定代码段,在模块加载这些段的时会单独分配内存。这些函数调用成功后,模块的加载程序会释放这部分内存空间。
__exit: 修饰清除函数
Extern: EXPORT_SYMBOL(XXXX);
EXPORT_SYMBOL 目的是为了动态加载的模块提供printk的地址信息,
EXPORT_SYMBOL_GPL(XXX);
File命令和nm命令: file ver.ko nm ver.ko
查看模块目标文件的 符号信息。t 是函数,u 是未决符号。
- 字符设备驱动: 按照字节流的形式进行,2.没有页高速缓存。3.不支随机(串口,键盘)也支持随机(帧缓存设备)
- 块设备驱动: 1对数据是按照若干个块进行的,每次读写至少4096字节,支持随机访问,为了提高效率。 一般之前从硬盘上得到的数据放在一个叫做页高速缓存中。
- 网络设备驱动:
为了下一次能够快速打开一个文件,内核在第一次打开一个文件或目录的时候,都会创建一个dentry目录项,它保存了文件名和所对应的inode信息,所有的dentry使用散列值的方式存储在目录项高速缓存中。
内核在打开文件时会先打开这个高速缓存中查找dentry, 如果找到则可以立即获取文件所对应的inode,否则就会在磁盘上获取。
首先根据inode中的设备号找到cdev,然后根据cdev找到关联的操作方法集合,从而调动驱动所提供的操作方法来完成对设备的具体操作。
File 在磁盘, inode在内存,--------目录项页高速缓存中
Task_struct 中有files 它的类型是 files_struct
Files_struct 中包含了fd(文件描述符)
文件描述符中包含了f_op( file_operations)
File_operations 中有 open, read, write, release
Dentry目录项页高速缓存中 有d_name, d_inode
D_inode中包含了inode信息
Inode信息中包含i_cdev,f_op
I_cdev 是和cdev_map中的cdev是相关联的(一致)
F_op(file_operations) 中内核实现了open函数 如下:
Chrdev_open(){
Inode->i_cdev = p =new;
Fops = fops_get(p->ops);
Replace_fops(filep, fops);
Filp->f-_op->open(); //就用了驱动中的操作函数
}
Cdev_map 结构体中 kobj_map,
Kobj_map中有probe , 是一个链表 (probe里面包含了range, data)
Data存放的就是cdev
- 字符设备驱动框架
要实现一个驱动,最重要的事就是构造一个cdev结构对象,并让cdev同设备号和设备的操作方法集合像关联,然后将cdev结构体对象添加到内核的cdev_map散列表中(函数 cdev_add())。
MAJOR(dev) MINOR(dev) MKDEV(ma, mi)
Static int ver_open(…………)
Switch( MINOR(inode->i_cdev)){
Case 0:
Case 1:
}
以上方式不好 最好用 container_of( inode->i_cdev, struct vser_vdev, cdev);
Vsdev[i].fifo = I == 0 ? (struct kfifo *)&vsfifo0 : (struct kfifo *)&vsfifo1;
Ioctl 系统调用
对应的是 unlocked_ioctl 和 compat_ioctl,
Compat_ioctl 是为了处理32位和64位兼容的一个函数接口。
#define _IO(type, nr)
内核为什么没有用memcpy函数,而是用copy_from_user, copy_to_user
这两个函数都返回未复制成功的字节数,复制 成功返回0.
该函数使用了access_ok来验证用户空间的内存是否真实可读可写,避免了内核中的缺页故障带来的一些问题。
这两个函数可能会使进程休眠。
如果只是简单的复制数据,可以用get_user, put_user.
Proc是为文件系统,不存在磁盘上,是在内存上。
对硬件来说,取而代之的是sysfs文件系统。
- Vsdev.pdir = Proc_mkdir(“vser”, NULL);
- Proc_create_data(“info”, 0 , vsdev.pdir, &prov_ops, &vsdev); // 私有数据
File_operations prov_ops = {
.open = proc_open,
}
Int proc_open(…….)
Return single_open(file, data_show, PDE_DATA(inode);
Int data_show(struct seq_file *m, void *v)
Struct vser_dev *dev = m->private;
Seq_printf(m, xxxxxx);
Remove_provc_entry();
Remove_prove_entry()
几种I/O模型总结
阻塞 非阻塞
同步 阻塞I/O 非阻塞I/O
异步 I/O多路复用 异步I/O
阻塞I/O: 在资源不可用的时,进程阻塞,阻塞发生在驱动中。 阻塞期间不占用cpu,最常用的方式。
如果资源不可用,进程阻塞,也就是进程休眠。自己设置自己位TASK_UNINTERRUPTIBLE 或 TASK_INTERRUPTIBLE , 然后将自己加入一个驱动所维护的等待队列中。最后调用SCHEDULE主动放弃cpu.
DECLARE_WAIT_QUEUE_HEAD(name)
Init_waitqueue_head(q)
Wait_event(wq, condition)// 不成立的情况下,将当前进程放入到等待队列并休眠的基本操作。
Wait_event_timeout(wq, condition, timeout)
Wait_event_interruptible(wq, condition)
Wait_event_interruptible_timeout(wq, condition,timeout)
Wait_event_interruptible_exclusive(wq, condition) // exclusive 表示该进程具有排他性。
Wait_up(x)
Wait_event_interruptible_locked(wq, condition) // locked要求在调用前先获得等待队列的内部的锁
Wait_event_interruptible_locked_irq(wq, condition) //irq表示上锁的同时禁止中断。
Wait_event_interruptible_exclusive_locked(wq, condition)
Wait_event_interruptible_exclusive_locked_irq(wq, condition)
Wake_up_locked(x)
非阻塞I/O:调用立即返回。
应用层添加 O_NONBLOCK标志位
驱动判断是否添加了。(但是判断之前需要判断是否kfifo是空,还是满的判断)
如果是空的时候,读就没有意义,直接返回
如果是满的话,写就没有意义,直接返回。
相比与非阻塞IO, 最大的优点是,资源不可用的时候,不占用CPU的时间,而非阻塞IO必须要定期尝试(这个是应用层的代码决定的),看看资源是否可以获得。这对于键盘和鼠标这类设备来讲,效率是非常低的。
但是阻塞IO也有一个明显的缺点,就是进程在休眠期间再也不能做其他的事情了。
IO多路复用: 同时监听多个设备的状态。如果被监听的所有设备都没有关心的事件发生,那么系统调用被阻塞。当被监听的的任何一个设备有对应的关心的事件发生,将会唤醒系统调用,将再次遍历所监听的设备。之后对设备发起非阻塞的读或写的操作。
Int ver_poll (xxxxx)
Int mask = 0;
Poll_wait(filp, &vsdev.rwqh, p); //读的等待队列
Poll_wait(filp, &vsdev.wwqh, p); 写的等待对垒
If (!kfifo_is_empty(&vsfifo))
Mask |= POLLIN | POLLRDNORM;
If (!kfifo_is_full(&vsfifo))
Mask |= POLLOUT | POLLWRNORM;
Return mask;
Pollà sys_pollà do_sys_pollà 有一个for循环,构造一个Poll_list ,其主要作用就是把用户层传递过来的struct pollfd复制到 poll_list 中,并记录监听文件的个数。
Do_sys_poll
For(;;)
poll_initwait(&table); //构造一个poll_wqueues结构体,初始化成员
init_poll_funcptr(&pwq->pt, __pollwait); // pwq->pt->_qprov = __pollwait
do_poll(head, &table, end_time);
- do_pollfd
mask = f.file->f_op->poll
否则:
- if (!poll_schedule_timeout(wait, TASK_INTERRUPTIBLE, to, slack))
驱动中的poll接口函数是不会休眠的,休眠发生在poll系统调用上。 Do_pollfd
异步IO:调用者只是发起IO操作,然后立即返回,程序可以去做其他的事情,具体的IO会在驱动中完成。当驱动IO操作完成之后,由内核通知调用者,而不是驱动本身。
异步通知:当设备资源可获得时,由驱动主动通知应用程序,再由应用程序发起访问。
Fcntl: 是调用了do_fcntl来完成具体的操作。 F_SETFL则调用setfl函数,setfl会调用驱动代码中的fasync接口函数,并传递FASYNC的标志是否被设置。驱动中的fasync接口函数会调用fasync_helper函数。
通过kill_fasync函数发送信号,该函数会遍历struct fasync_struct 链表,从而找到所有接收信号的进程,并调用send_sigio依次发送信号。
Mmap设备文件操作
Unsigned long addr:
Addr = __get_free_page(GFP_KERNEL);
Vfbdev.buf = (unsigned char *)addr;
Memset(vfbdef.buf, 0, PAGE_SIZE);
Remap_pfn_range(
Vma,
Vma->vm_start,
Virt_to_phys(vfbdev.buf) >> PAGE_SHIFT, //是页帧号,
Vma->vm_end – vma->vm_start,
Vma->vm_page_prot
);
- 第一个参数 vma是用来描述一片映射区域的结构指针,一个进程有很多片映射的区域,每一个区域都有这样对应的一个结构,这些结构通过链表和红黑树组织在一起,该结构描述了该片映射区域的虚拟起始地址,结束地址和访问权限。
- 第二个参数addr是用户指定的映射之后的虚拟起始地址,如果用户填的是null,那么由内核来指定该地址。
- 第三个参数是物理内存所对应的页框号,就是将物理地址/页大小得到的值。
- 第四个参数是要映射的空间的大小。
- 最后一个参数是,内存区域的访问权限。
-
addr = mmap(NULL, BUF_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_LOCKED, fd, OFFSET);
static int remap_pfn_mmap(struct file *file, struct vm_area_struct *vma)
{
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
unsigned long pfn_start = (virt_to_phys(kbuff) >> PAGE_SHIFT) + vma->vm_pgoff;
unsigned long virt_start = (unsigned long)kbuff + offset;
unsigned long size = vma->vm_end - vma->vm_start;
int ret = 0;
printk("phy: 0x%lx, offset: 0x%lx, size: 0x%lx\n", pfn_start << PAGE_SHIFT, offset, size);
ret = remap_pfn_range(vma, vma->vm_start, pfn_start, size, vma->vm_page_prot);
if (ret)
printk("%s: remap_pfn_range failed at [0x%lx 0x%lx]\n",
__func__, vma->vm_start, vma->vm_end);
else
printk("%s: map 0x%lx to 0x%lx, size: 0x%lx\n", __func__, virt_start,
vma->vm_start, size);
return ret;
}
第3行的vma_pgoff表示的是该vma表示的区间在缓冲区中的偏移地址,单位是页。这个值是用户调用mmap时传入的最后一个参数,不过用户空间的offset的单位是字节(当然必须是页对齐),进入内核后,内核会将该值右移PAGE_SHIFT(12),也就是转换为以页为单位。因为要在第9行打印这个编译地址,所以这里将其再左移PAGE_SHIFT,然后赋值给offset。
第4行计算内核缓冲区中将被映射到用户空间的地址对应的物理页帧号。virt_to_phys接受的虚拟地址必须在低端内存范围内,用于将虚拟地址转换为物理地址,而vmaloc返回的虚拟地址不在低端内存范围内,所以需要用专门的函数。
第5行计算内核缓冲区中将被映射到用户空间的地址对应的虚拟地址
第6行计算该vma表示的内存区间的大小
第11行调用remap_pfn_range将物理页帧号pfn_start对应的物理内存映射到用户空间的vm->vm_start处,映射长度为该虚拟内存区的长度。由于这里的内核缓冲区是用kzalloc分配的,保证了物理地址的连续性,所以会将物理页帧号从pfn_start开始的(size >> PAGE_SHIFT)个连续的物理页帧依次按序映射到用户空间。
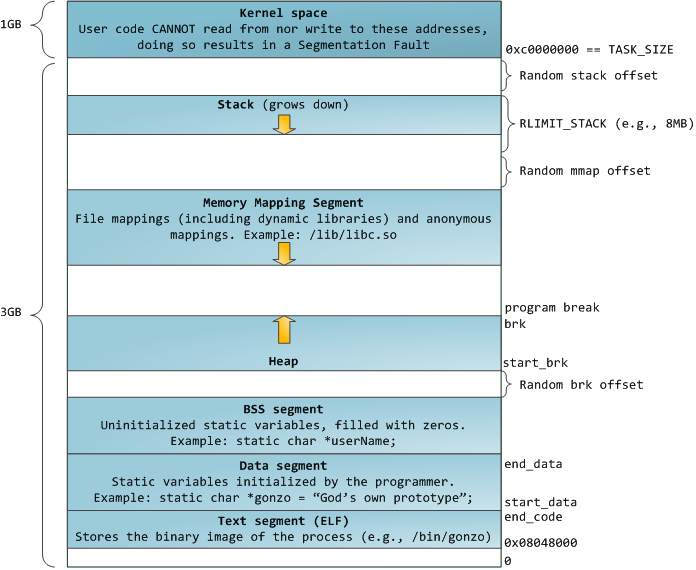
这里需要注意的是:
当调用malloc分配内存的时候,如果传给malloc的参数小于128KB时,系统会在heap区分配内存,分配的方式是向高地址调整brk指针的位置。当传给malloc的参数大于128KB时,系统会在mmap区分配,即分配一块新的vma,其中可能会涉及到vma的合并扩展等操作。
可以参考:Linux进程分配内存的两种方式--brk() 和mmap()
中断进入过程
soc中的中断控制器称为GIC, 将一个特定的中断分发给一个特定的ARM核。
__vectors_start 是异常向量表的起始地址。
Struct irq_desc : 对系统中的单个中断的抽象, 系统由多少个中断源就应该至少由多少个这样的对象int generic_handle_irq(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
generic_handle_irq_desc(desc);
return 0;
}
EXPORT_SYMBOL_GPL(generic_handle_irq);
/*
* Architectures call this to let the generic IRQ layer
* handle an interrupt.
*/
static inline void generic_handle_irq_desc(struct irq_desc *desc)
desc->handle_irq(desc);
struct irq_desc {
irq_flow_handler_t handle_irq; // @handle_irq: highlevel irq-events handler。
根据中断触发类型是 边沿触发还是电平触发,被调用的函数由 handle_edge_irq, handle_level_irq, (/kernel/irq/chip.c)
他们都会调用handle_irq_event(desc);来处理中断。
irqreturn_t handle_irq_event(struct irq_desc *desc)
{
ret = handle_irq_event_percpu(desc);
}
irqreturn_t __handle_irq_event_percpu(struct irq_desc *desc, unsigned int *flags)
for_each_action_of_desc(desc, action) {
res = action->handler(irq, action->dev_id);
cat /proc/interrupts
return IRQ_HANDLED 表示中断处理正常
中断底板部
顶半部: 完成紧急但能很快完成的事情,底半部:完成不紧急但比较耗时的工作。例如网卡。
TASKLET_SOFTIRQ 相应的中断处理函数是 tasklet_action
static __latent_entropy void tasklet_action(struct softirq_action *a) (/kernel/softirq.c)
list = __this_cpu_read(tasklet_vec.head);
while (list) {
t->func(t->data);
首先得到本cpu的一个struct tasklet_struct 对象的链表,然后遍历链表,调用其中的func成员所指向的函数。
DECLARE_TASKLET(name, func, data);
DECLARE_TASKLET_DISABLED(name, func, data)
Void tasklet_init(…..)
Void tasklet_schedule(…..) // 一般中断中会调用 底半部。
- tasklet 是一个特定的软中断, 处于中断的上下文
- tasklet_schedule函数被调用后,对应的下半部会保证被至少执行一次。
- 如果一个tasklet 已经被调度,但是还没有被执行,那么新的调度将被忽略。
工作队列
内核再启动的时候创建一个或多个内核工作线程,工作线程中取出工作队列中的每一个工作,然后执行,当队列中没有工作时,工作线程睡眠。
当驱动想要延迟执行某一个工作时,构造一个工作队列节点对象,然后加入到相应的工作队列,并唤醒工作线程,工作线程又取出队列的节点完成工作,所有工作完成后又休眠。
因为是运行再进程上下文,所以工作是可以调用调度器。
struct work_struct {
unsigned long data;
struct list_head entry; // 构成工作队列的链表节点对象。
work_func_t func; // 工作函数,工作线程取出工作队列节点后执行
};
DECLARE_WORK(n, f);
DECLARE_DELAYED_WORK(n, f);
INIT_WORK(_work, _func);
Bool schedule_work(…..);
Bool schedule_delayed_work(….);
- 工作队列主要运行在进程上下文,可以调度调度器。
- 如果上一个工作还没有完成,又重新调度下一个工作,那么新的工作将不会被调度。
延时控制
内核在启动过程中会计算一个全局变量loops_per_jiffy 的值,该值反映了一段循环延时的代码要循环多少次才能延时一个jiffy 的时间。
Ndelay,udelay,mdelay, 这些都是忙等待浪费CPU时间。
休眠延时
Msleep, ssleep,只能等到休眠时间到了才会返回。
msleep_interrutible, 可以被信号打断。
定时操作。
Init_timer
Add_timer
Mod_timer
Del_timer
内核是在定时器中断的软中断下半部来处理这些定时器,内核将会遍历链表中的定时器,如果当前的jiffies的值和定时器中的expires的值相等,那么定时器函数就会被执行,
定时器函数是在中断上下文中执行的。
一个HZ 是1s, 如果 hz=200 那么 jiffy的时间就是5毫秒,定时器的精度就5毫秒。
高分辨率定时器
Union ktime
Ktime_t t = ktime_set();
Struct hrtimer {}
Hrtimer_init
Hrtimer_start
Hrtimer_forward_now 修改到期时间为从现在开始之后的 interval时间
Hrtimer_forward_now(timer, ktime_set(1,1000));
Hrtimer_cancel
互斥和同步
内核中有哪些并发的情况?
- 硬件中断
- 软中断和tasklet
- 抢占内核的多进程环境
- 普通多进程环境
- 多处理或多核CPU
共享资源又叫临界资源,访问共享资源的这段代码又叫临界代码段或临界区。
- 中断屏蔽
- Local_irq_save
- Local_irq_restore
- 原子变量 // 开销小
- Atomic_read
- Atomic_set
- Atomic_add
- Atomic_sub
- 自旋锁//忙等锁
- Spin_lock_init