版权声明:fromZjy QQ1045152332 https://blog.csdn.net/qq_36762677/article/details/88381574
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
download :https://www.elastic.co/cn/downloads/elasticsearch
全文搜索
结构化数据------>关系型数据库存储,查找
非结构化数据—>1.顺序扫描法(从头到尾) 2. 全文搜索(建立文本库,创建索引搜索)
全文搜索实现 ElasticSearch
- 基于java语言,Lucene引擎
- 高度可扩展的开源全文搜索和分析引擎
- 快速,近实时的对大数据的存储和搜索、分析
- 异步写入
- 自身带有分布式,solr需要依赖zookeeper ,solr支持xml,json等格式
数据存储在安装目录data下
搜索原理
插入这些数据到Elasticsearch的同时,Elasticsearch还为数据的每个字段建立索引–倒排索引
连接springboot
application.properties

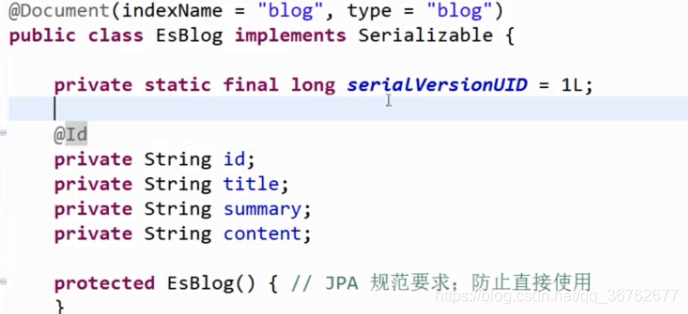
实体类
测试ES启动成功 http://localhost:9200/?pretty
集群配置
ES集群中的节点有三种不同的类型:
- 主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
- 数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
- 协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
配置文件存放在config/elasticsearch.yml
节点A:
cluster.name:elasticsearch-cluster-203
node.name:es-node-1
bootstrap.mlockall:true
network.host:172.16.203.1
discovery.zen.ping.unicast.hosts:["172.16.203.2"]
节点B:
cluster.name:elasticsearch-cluster-203
node.name:es-node-2
bootstrap.mlockall:true
network.host:172.16.203.2
discovery.zen.ping.unicast.hosts:["172.16.203.1"]
Es调优
第一
vim/etc/profile增加环境变量
ES_HEAP_SIZE
jvm堆内存设为当前内存的一半。
ES_HEAP_SIZE=4096m
export ES_HEAP_SIZE
第二
elasticsearch.yml配置文件
bootstrap.mlockall:true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap