预写日志(Write-ahead log,WAL)
最重要的作用是灾难恢复,一旦服务器崩溃,通过重放log,我们可以恢复崩溃之前的数据。如果写入WAL失败,整个操作也将认为失败。
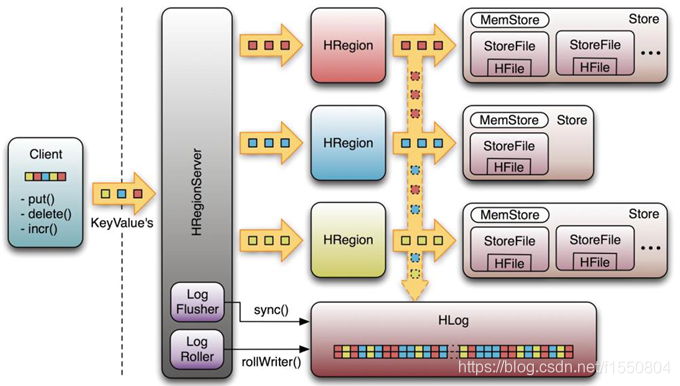
从上图看:
1 客户端对数据执行一个修改操作,如put(),delete(),incr()等。
2 每一个修改被封装到一个KeyValue对象实例,并通过RPC调用发送出来。
3 上述调用成批地发送给含有匹配region的HRegionServer。
4 数据先被写入到WAL,然后被放放到实际拥有记录的存储文件的MemStore中。
5 当MemStore达到一定的大小或经历一个特定时间之后,数据会异步地连续写入到文件系统中。
由于实际的日志存储在HDFS上,所以即使在服务器完全崩溃的情况下,WAL也能保证数据不会丢失。其他服务器可以打开日志文件然后回放这些修改。
为什么要一个RegionServer 对应于一个HLog。为什么不是一个region对应于一个log file?
引用BigTable中的一段话:
如果我们每一个“tablet”(对应于HBase的region)都提交一个日志文件,会需要并发写入大量的文件到GFS,这样,根据每个GFS
server所依赖的文件系统,写入不同的日志文件会造成大量的磁盘操作。
HBase依照这样的原则。在日志被回滚和安全删除之前,将会有大量的文件。如果改成一个region对应于一个文件,将会不好扩展,迟早会引发问题。
延迟(异步)同步写入WAL
WAL在默认情况下时开启的,当然,我们也可以手动关闭。调用{Mutation.setDurability(Durability.SKIP_WAL)}方法来关闭,这样做的确可以使得数据操作快一点,但并不建议这样做,一旦服务器宕机,数据就会丢失。
延迟(异步)同步写入WAL。调用setDurability(Durability.ASYNC_WAL),这样通过设置时间间隔来延迟将操作写入WAL。
时间间隔:HBase间隔多久会将操作从内存写入到WAL,默认值为1s。 这种方法也可以相对应地提高性能。
WAL几个重要的类
1、HLog
HLog是实现WAL的类。一个HRegionServer对应一个HLog实例。当HRegion初始化时,HLog将作为一个参数传给HRegion的构造函数。
HLog最核心的是调用doWrite的append()方法,前面提到的可能对数据改动的操作都就将首先调用这个方法。出于性能的考虑,put(), delete()和incrementColumnValue()有一个开关函数setWriteToWAL(boolean) ,
设为false将禁用WAL。这是为什么上图中向下的箭头是虚线的原因。默认时候当然需要WAL,但是假如你运行一个数据导入的MapReduceJob,你可以通过关闭WAL获得性能上的提升。
2、HLogKey类
1、当前的WAL使用的是hadoop的sequencefile格式,其key是HLogKey实例。HLogKey中记录了写入数据的归属信息,,除了table和region名字外,同时还包括sequencenumber和timestamp,timestamp是“写入时间“,sequencenumber的起始值为0,或者是最近一次存入文件系统中sequence number
2、HLog sequenceFile的value是HBase的KeyValue对象,即对应HFile中的KeyValue
3、WALEdit类
客户端发送的每个修改都会封装成WALEdit类,一个WALEdit类包含了多个更新操作,可以说一个WALEdit就是一个原子操作,包含若干个操作的集合
4、LogSyncer类
Table在创建的时候,有一个参数可以设置,是否每次写Log日志都需要往集群里的其他机器同步一次,默认是每次都同步,同步的开销是比较大的,但不及时同步又可能因为机器宕而丢日志。
同步的操作现在是通过Pipeline的方式来实现的,Pipeline是指datanode接收数据后,再传给另外一台datanode,是一种串行的方式;
n-Way Writes是指多datanode同时接收数据,最慢的一台结束就是整个结束。
差别在于一个延迟大,一个并发高,hdfs现在正在开发中,以便可以选择是按Pipeline还是n-Way Writes来实现写操作。Table如果设置每次不同步,则写操作会被RegionServe缓存,并启动一个LogSyncer线程来定时同步日志,定时时间默认是1秒,也可由hbase.regionserver.optionallogflushinterval设置。
5、LogRoller类
日志写入的大小是有限制的。LogRoller类会作为一个后台线程运行,在特定的时间间隔内滚动日志。通过hbase.regionserver.logroll.period属性控制,默认1小时。
WAL滚动
就是上文提到的LogRoller类。
通过wal日志切换,这样可以避免产生单独的过大的wal日志文件,这样可以方便后续的日志清理(可以将过期日志文件直接删除)另外如果需要使用日志进行恢复时,也可以同时解析多个小的日志文件,缩短恢复所需时间。
触发滚动的条件:
1.SyncRunner线程在处理日志同步后, 检查当前在写的wal的日志大小是否超过配置{hbase.regionserver.hlog.blocksize默认为hdfs目录块大小}*{hbase.regionserver.logroll.multiplier默认0.95},超过后同样调用requestLogRoll发起日志滚动请求
2.SyncRunner线程在处理日志同步后,如果有异常发生,就会调用requestLogRoll发起日志滚动请求
WAL归档和删除
归档:WAL创建出来的文件都会放在/hbase/.log下,在WAL文件被定为归档时,文件会被移动到/hbase/.oldlogs下
删除:1.判断:是否此WAL文件不再需要,是否没有被其他引用指向这个WAL文件
会引用此文件的服务:
(1)TTL进程:该进程会保证WAL文件一直存活直到达到hbase.master.logcleaner.ttl定义的超时时间(默认10分钟)为止
(2)(2)备份(replication)机制:如果你开启了HBase的备份机制,那么HBase要保证备份集群已经完全不需要这个WAL文件了,才会删除这个WAL文件。这里提到的replication不是文件的备份数,而是0.90版本加入的特性,这个特性用于把一个集群的数据实时备份到另外一个集群。如果你的手头就一个集群,可以不用考虑这个因素。
2.删除
Write-Ahead-Log(WAL)保证数据的高可用性。
如果没有 WAL,当RegionServer宕掉的时候,MemStore 还没有写入到HFile,或者StoreFile还没有保存,数据就会丢失。
HBase中的HLog机制是WAL的一种实现,每个RegionServer中都会有一个HLog的实例,RegionServer会将更新操作(如 Put,Delete)先记录到 WAL(也就是HLog)中,然后将其写入到Store的MemStore,最终MemStore会将数据写入到持久化的HFile中(MemStore 到达配置的内存阀值)。这样就保证了HBase的高可用性。
下一章:HBase安装部署