转自:https://zhuanlan.zhihu.com/p/56700862
前戏
最近目标检测方向,出了很多paper,CVer也立即跟进报道(点击可访问):
- TridentNet 处理目标检测中尺度变化新思路
- One-stage目标检测最强算法 ExtremeNet
- 目标检测最新方向:推翻固有设置,不再一成不变Anchor
- SimpleDet:简单通用的目标检测与物体识别框架
本文介绍一篇很棒的目标检测训练技巧论文。该论文是由Amazon Web Services 提出,其中作者团队中就有李沐等大神 。之前Amazon还提出图像分类的Tricks论文,详见 亚马逊:用CNN进行图像分类的Tricks
简介
《Bag of Freebies for Training Object Detection Neural Networks》

arXiv: https://arxiv.org/abs/1902.04103
github: https://github.com/dmlc/gluon-cv
作者团队:Amazon Web Services
注:2019年02月11日刚出炉的paper
Abstract:目标检测训练与图像分类模型的研究相比,相对缺少普遍性。由于网络结构和优化目标明显更加复杂,因此针对某些检测算法而不是其他检测算法专门设计了各种训练策略和 pipelines。在这项工作中,我们探索了有助于将最先进的目标检测模型的性能提升到一个新水平而不牺牲推理(inference)速度的通用调整。我们的实验表明,这些训练秘籍(freebies)可以在精度上增加5%,因此每个人都应该考虑在一定程度上将这些训练秘籍应用于目标检测训练中。

正文
主要贡献
1)我们是第一个系统地评估各种目标检测 pipelines 中应用的各种训练启发式方法,为未来的研究提供了有价值的实践指导。
2)我们提出了一种用于训练目标检测网络的 visually coherent image mixup 方法,该方法被证明在提高模型通用能力方面非常有效。
3)在不改变网络结构和损失函数的情况下,基于现有模型,我们 achieved up to 5% out of 30% absolute average precision。
4)我们扩展了目标检测数据增广领域的研究深度,显著增强了模型泛化能力,有助于减少过度拟合问题。实验还揭示了可以在不同网络结构中一致地提高目标检测性能的良好技术。
所有相关代码都是开源的,模型的预训练权重可在 GluonCV 工具包中获得。
GluonCV: https://github.com/dmlc/gluon-cv
具体创新点
1. Visually Coherent Image Mixup for Object Detection
这个创新点是受前段时间很出名的用于图像分类的数据增广论文:《mixup: Beyond empirical risk minimization》(ICLR 2018) 启发。用于图像分类的mixup方法如下:

用于目标检测的方法如下:

注意mixup中最重要的超参数就是α 和 β ,不同的值对结果(mAP)会有很大影响,结果如下所示:

Effect of various mix-up approaches
2. Classification Head Label Smoothing
这个创新点是受《Rethinking the inception architecture for computer vision》论文启发。
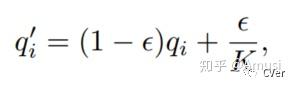
3. Data Pre-processing
- 随机几何变换。包括随机裁剪(带约束),随机扩展,随机水平翻转和随机缩放(随机插值)。
- 随机颜色抖动(jittering),包括亮度,色调,饱和度和对比度。
4. Training Scheduler Revamping
- the step schedule
- cosine learning rate adjustment
- Warm up learning rate

Visualization of learning rate scheduling with warm-upenabled for YOLOv3 training on Pascal VOC
5. Synchronized Batch Normalization
论文做了大量实验,调研 Synchronized Batch Normalization 对 YOLOv3的实验影响
注:有卡任性,哈哈
6. Random shapes training for single-stage object detection networks
为了适应内存限制并允许更简单的批处理,许多 single-stage 目标检测网络采用固定形状进行训练。本论文中,将一小批N个训练图像的大小调整为Nx3xHxW,其中H和W是D = randint(1; k)的multipliers。例如,使用H = W ∈ {320; 352; 384; 416; 448; 480; 512; 544; 576; 608} 用于YOLOv3训练。
实验结果
论文中使用 YOLOv3 和 Faster R-CNN 作为实验的目标检测框架。
YOLOv3 改进实验结果(在VOC数据集上)

Training Refinements on YOLOv3, evaluated at 416×416 on Pascal VOC 2007 test set
Faster R-CNN 改进实验结果(在VOC数据集上)

Training Refinements on Faster-RCNN, evaluated at 600 × 1000 on Pascal VOC 2007 test set