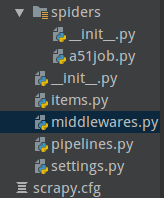
a51job.py,是爬虫,主要是进行请求,把请求发送给中间件middlewares.py,
middlewares.py通过
class JobMiddleware(object):
def init(self):
#接受到来自a51job.py中的Request请求,模拟的浏览器自动打开
self.browser = webdriver.Chrome(executable_path="/cdrom/chromedriver")
def process_request(self,request, spider):
#因为详情页中不需要Selenium模拟,所以直接请求就可以了(因为没有ajax)用源信息进行请求就可以了
if request.meta.get("message"):
return None
#浏览器get请求当中的url
self.browser.get(request.url)
# time.sleep(10)
#返回给爬虫一个response
return HtmlResponse(url=self.browser.current_url,body=self.browser.page_source,encoding="utf-8",request=request)
items:主要是做数据清洗(抓取字段根据需求进行处理)
pipelines.py:是最后一道工序,就是进行数据库的存储或者输出数据