1.1机器学习在20世纪下半叶演变为人工智能(AI)的一个分支,它涉及从数据中通过自我学习获得算法以进行预测。
1.2三种类型的机器学习:
有监督,无监督,强化

1.2.1用有监督学习预测
有监督学习:从有标签的训练数据中学习模型,以便对未知或未来的数据做出预测。“监督”一词指的是已经知道样本所需要的输出信号或标签。总之,有监督学习以带标签的训练数据训练模型,进一步将新数据加上标签。
带有离散分类标签的有监督学习——分类任务。
结果是连续的值——回归
分类是有监督学习的一个分支,根据已知的观测结果来观测新的样本分类标签。这些分类标签是离散的无序值。
回归分析是对连续结果的预测。回归分析包括一些预测变量和一个连续响应变量,试图寻找能够预测结果与变量之间的关系,比如在一个二维坐标系中,预测变量x,相应变量y,对出现的数据进行拟合(谋求样本点和拟合线平均距离最小)。
1.2.2用强化学习解决交互问题
强化学习的目标是开发系统或代理,通过它们与环境的交互来提高预测性能 在本书强化学习不是重点
1.2.3用无监督学习发现隐藏结构
在有监督学习中,事先知道正确的答案;在强化学习中,定义了代理对特定动作的奖励,然而无监督学习处理的是无标签的未知数据。用无监督学习技术,可以在没有已知结果变量或奖励函数的指导下,探索数据结构以提取有用信息。
1.2.3.1寻找聚类的子集
聚类是探索性的数据分析技术,可以在事先不了解组员的情况下,将信息分成有意义的族群。为在分析过程中出现的每个群定义一组对象,它们之间都有一定的相似性,但与其他群中对象的差异更大。
1.2.3.2通过降维压缩数据
无监督降维是特征处理中数据去噪的一种常用方法,它也降低了某些算法对预测性能的要求,在保留大部分信息的同时将数据压缩到较小的维数空间上。
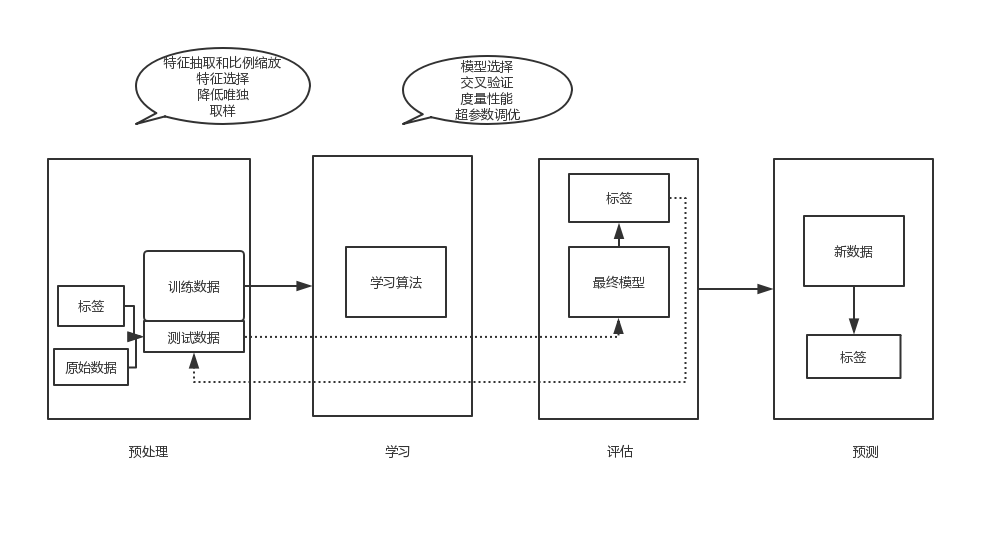
1.3相关约定
用矩阵表示数据集时,每一行代表一个样本,每一列代表一个特征。 一个150*4的矩阵代表了150个样本,每个样本有4个标签
1.4构建机器学习系统的路线图