一、什么是Zookeeper
Zookeeper是一个高可用的分布式管理与协调框架,基于ZAB算法(原子消息广播协议)实现。ZK能够很好的保证分布式环境下的数据一致性,这一特性使得ZK是处理分布式一致性问题的利器。可以基于它实现发布订阅、负载均衡、命名服务、协调通知、集群管理、master选举、分布式锁和分布式队列的特性
1.1 原理
ZooKeeper是以Fast Paxos算法为基础的,Paxos 算法存在活锁的问题,即当有多个proposer交错提交时,有可能互相排斥导致没有一个proposer能提交成功,而Fast Paxos作了一些优化,通过选举产生一个leader (领导者),只有leader才能提交proposer。
1.2 特性
-
可靠性:一旦Zookeeper成功的应用了一个事务,并完成对client的响应,那么Zookeeper内部集群的所有服务器的状态都会是一致的保留下来。
-
单一视图:由于上面可靠性的保证,使得无论client连接的是ZK集群中的哪个服务器,所看到的数据都是一致的。
-
顺序一致性:从一个client发起的请求,最终会严格的按照发起的顺序被应用到Zookeeper中去。【实质上,ZK会对每一个client的每一个请求,进行编号,说白了,就是分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序。】
-
实时性:通常意义下的实时性是指一旦事务被成功应用,那么client会立刻从服务器端获取到变更后的新数据。ZK仅仅能够保证在一定时间内,client最终一定会能从服务器上获取到最新的数据。
-
高可用:在ZK集群内部,会有一个Leader,多个Follower。一旦Leader挂掉,那么ZK会通过Paxos算法选举出新的Leader,只要ZK集群内部的服务器有一半以上正常工作,那么ZK就能对外正常提供服务!
-
简单的数据结构:类似于Linux文件系统的树形结构,简单,实用!(树形层次空间)
-
高性能:性能有多高呢,举个栗子,比如我们经常通过创建临时节点来处理分布式锁,要知道临时节点是存储在内存中的,在读场景压力测试下,QPS高达10W+!也就是说ZK在读场景下,性能非常突出!
1.3 zookeeper的数据模型
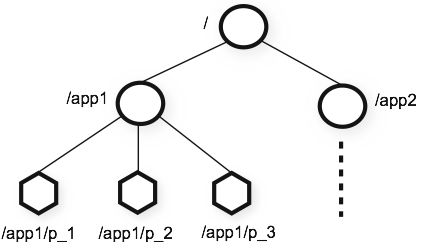
- 每一个节点被称为
znode,znode可以有子节点目录,并且每个znode可以存储数据(特别需要注意的是临时节点不可以有子节点) - znode如果是临时节点,意味着创建这个znode的client一旦与ZK集群失去联系,这个临时的znode将被自动删除。(事实上,client与ZK通信是采用长连接方式,并通过心跳的方式保持连接,这种状态就是session,一旦session失效,就是连接断开,临时节点会被删除掉)
- znode是可以被监控的,不论是znode本身的数据变化,还是该znode下的子节点的变化,都可以进行监控,这也是ZK的核心特性。
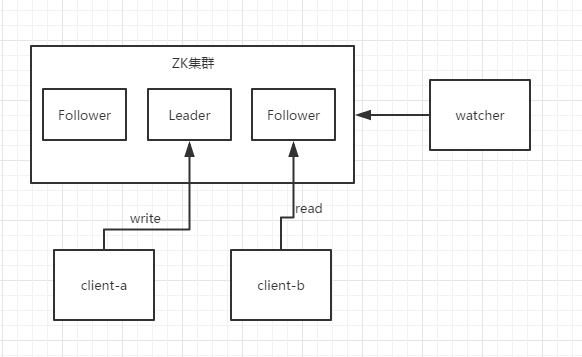
1.4 Zookeeper的组成
- Leader:负责客户端的write类型的请求
- Follower:负责客户端的read类型请求,并可以参与Leader的选举
- Observer/watcher: 特殊的Follower,与Follower统称为Learner
1.5 应用场景
配置管理
- 集群管理
- 发布与订阅
- 数据库切换
- 分布式日志收集
- 分布式锁、队列管理等
- ……
更多详细>>
1.6 其他
- ZAB算法(原子消息广播协议)
- Paxos 算法