词袋模型
此模型下,一段文本(比如一个句子或是一个文档)可以用一个装着这些词的袋子来表示,这种表示方式不考虑文法以及词的顺序,例如下面两个句子:
(1) John likes to watch movies. Mary likes movies too.
(2) John also likes to watch football games.
基于以上两个文件,可以建构出下列清单:
[
"John",
"likes",
"to",
"watch",
"movies",
"also",
"football",
"games",
"Mary",
"too"
]
此处有10个不同的词,那么两个句子就可以使用清单的索引表示长度为10的向量:
(1) [1, 2, 1, 1, 2, 0, 0, 0, 1, 1] (2) [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
每个向量的索引内容对应到清单中词出现的次数。
举例来说,第一个向量(文件一)前两个内容索引是1和2,第一个索引内容是"John"对应到清单第一个词并且该值设定为1,因为"John"出现一次。
TF-IDF
每篇文章可以表示成一个长向量,向量中的每一维代表一个单词,而该维对应的权重则反映了这个词在原文章中的重要程度。常用TF-IDF来计算权重,公式为
TF-IDF(t,d)=TF(t,d)×IDF(t)
其中TF(t,d)为单词t在文档d中出现的频率,IDF(t)是逆文档频率,用来衡量单词t对
表达语义所起的重要性,表示为

直观的解释是,如果一个单词在非常多的文章里面都出现,那么它可能是一个比
较通用的词汇,对于区分某篇文章特殊语义的贡献较小,因此对权重做一定惩
罚。
N-gram
将文章进行单词级别的划分有时候并不是一种好的做法,比如英文中的natural language processing(自然语言处理)一词,如果将natural,language,processing这3个词拆分开来,所表达的含义与三个词连续出现时大相径庭。通常,可以将连续
出现的n个词(n≤N)组成的词组(N-gram)也作为一个单独的特征放到向量表示
中去,构成N-gram模型。另外,同一个词可能有多种词性变化,却具有相似的含
义。在实际应用中,一般会对单词进行词干抽取(Word Stemming)处理,即将不
同词性的单词统一成为同一词干的形式。
上面的几种方法,都是单纯的统计字频,并没有很清晰的表示出词之间的关联,比如出现了一个词,那么他周围的词最有可能是什么;
在后来的研究中人们发现,一个词总是在一个语境出现,所以我们是不是可以采用周围的词来表示中间的词呢?后来证实这种想法是很有效,并且效果比之前的词袋模型或者TF-IDF效果都要好。
但是在介绍Word2Vecz之前我先介绍一下共现矩阵;
共现矩阵
什么是共现矩阵,顾名思义是两个词一起出现的频数构成的矩阵,直接上例子:
1. I enjoy flying.
2. I like NLP.
3. I like deep learning.
根据这三句话我们可以构造如下的共现矩阵:
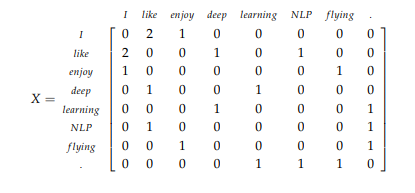
在是先共现矩阵我们要设置一个窗口,并且统计这个窗口中共同出现的词的频数如上图我们把窗口设置成1。即在中心词左右窗口各为1,如以‘I‘为中心词在窗口内like出现了两次,enjoy出现一次,以此类推。
我们可以观察可以得出like和enjoy的向量表示非常相似所以我们可以认为这两个词表达的意思相似。
共现矩阵基于用语境表示词的观念创造性的给出了一个词的表示。
但是共现矩阵有了很大的缺点
- 这是一个大的稀疏矩阵,极大的浪费了内存空间。
- 对了没有出现的词主要修改矩阵,非常麻烦。
- 针对稀疏矩阵我们可以用SVD的方法解决,但是计算量很大。
word2vec
词向量模型也是认为如果两个词相似,那么他们周围的词很有可能也是相似的,或者如果中心词的周围词相似那么这个中心词可能也是相似的。
有两种模型一种CBOW,一种是Skip-gram
CBOW
CBOW的目标是根据上下文出现的词语来预测当前词的生成概率,模型图如下:
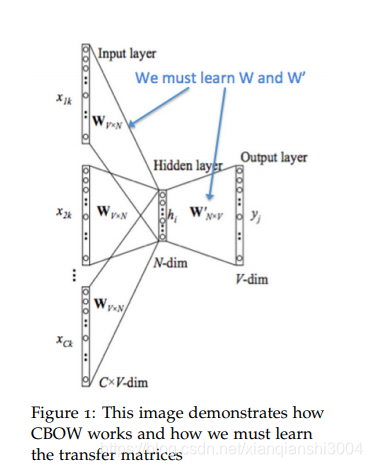
如图我们先设置一个窗口k,先去中心词周围2k个词作为输入(每一个词采用one-hot编码,长度是|V|—所有单词去重的个数。)然后这2k个向量叠加在一起,然后输入隐藏层,隐层矩阵就是我们最后要得到的词向量矩阵,是NxV大小的,其中N是词向量的大小,最后输出层采用softmax函数。
具体的提到过程可以参考CS224N的课程笔记。
skip-gram
Skip-gram是根据当前词来预测上下文中各词的生成概率。
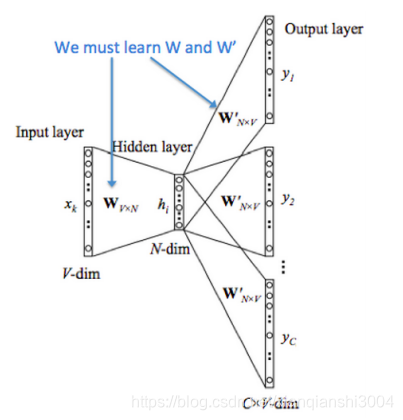
从上图我们可以看出实际上是CBOW模型翻转了过来,根据中心词来预测周围词。隐层矩阵同样是表示词向量矩阵。
关于两个矩阵我们在计算时可以采用一些策略进行优化比如哈夫曼树,还有负采样。 具体的实现策略可以参考CS224n笔记。
Glove
简单的提一下这个模型,这个模型应该是word2vec和共现矩阵的结合,详细可以参见这个博客。