ndarray介绍
NumPy provides an N-dimensional array type, the ndarray, which describes a collection of “items” of the same type.
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
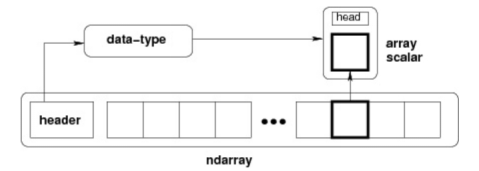
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
创建ndarray
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数描述:
- object 数组或嵌套的数列
- dtype 数组元素的数据类型,可选
- copy 对象是否需要复制,可选
- order 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
- subok 默认返回一个与基类类型一致的数组
- ndmin 指定生成数组的最小维度
import numpy as np
a = np.array([1, 2, 3], dtype = complex)
print (a)
输出结果如下:
[ 1.+0.j, 2.+0.j, 3.+0.j]
ndarray 对象由计算机内存的连续一维部分组成,并结合索引模式,将每个元素映射到内存块中的一个位置。内存块以行顺序(C样式)或列顺序(FORTRAN或MatLab风格,即前述的F样式)来保存元素

用ndarray进行存储:

import numpy as np
# 创建ndarray
score = np.array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
score
返回结果:
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])

使用Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组,那么为什么还需要使用Numpy的ndarray呢?
ndarray与Python原生list运算效率对比
在这里我们通过一段带运行来体会到ndarray的好处
import random
import time
import numpy as np
a = []
for i in range(10000000):
a.append(random.random())
t1 = time.time()
sum1=sum(a)
t2=time.time()
b=np.array(a)
t4=time.time()
sum3=np.sum(b)
t5=time.time()
print(t2-t1, t5-t4)
t2-t1为使用python自带的求和函数消耗的时间,t5-t4为使用numpy求和消耗的时间,结果为:
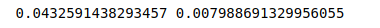
类似的
从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。

Numpy专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,Numpy的优势就越明显。
思考:ndarray为什么可以这么快?
ndarray的优势
1 内存块风格
ndarray到底跟原生python列表有什么不同呢,请看一张图:

从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生lis就t只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
2 ndarray支持并行化运算(向量化运算)
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
3 Numpy底层使用C语言编写
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。
用C语言实现,是机器码,本身就比解释型的字节码快,同时机器码也可以不受GIL限制
N维数组-ndarray
ndarray的属性
NumPy 数组的维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
数组属性反映了数组本身固有的信息。



ndarray的形状
首先创建一些数组。
# 创建不同形状的数组
a = np.array([[1,2,3],[4,5,6]])
b = np.array([1,2,3,4])
c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
分别打印出形状

如何理解数组的形状?
二维数组:
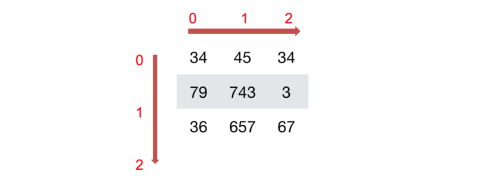
三维数组:

3.2.3 ndarray的类型

type(score.dtype)
输出
<type 'numpy.dtype'>
dtype是numpy.dtype类型,先看看对于数组来说都有哪些类型


数据类型对象 (dtype)
数据类型对象是用来描述与数组对应的内存区域如何使用,这依赖如下几个方面:
- 数据的类型(整数,浮点数或者 Python 对象)
- 数据的大小(例如, 整数使用多少个字节存储)
- 数据的字节顺序(小端法或大端法)
- 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,它的形状和数据类型
字节顺序是通过对数据类型预先设定"<“或”>“来决定的。”<“意味着小端法(最小值存储在最小的地址,即低位组放在最前面)。”>"意味着大端法(最重要的字节存储在最小的地址,即高位组放在最前面)。
dtype 对象是使用以下语法构造的:
numpy.dtype(object, align, copy)
参数描述:
- object - 要转换为的数据类型对象
- align - 如果为 true,填充字段使其类似 C 的结构体。
- copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
创建数组的时候指定类型
a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
a.dtype
输出 dtype('float32')
arr = np.array(['python', 'tensorflow', 'scikit-learn', 'numpy'], dtype = np.string_)
arr
输出 array([b'python', b'tensorflow', b'scikit-learn', b'numpy'], dtype='|S12')
- 注意:若不指定,整数默认int64,小数默认float64
- 混合类型默认类型如下:
