LRU(Least recently used)算法,顾名思义:最近最少使用。
-
LRU-1算法
算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。最常见的实现是使用一个链表保存缓存数据,如下图所示:
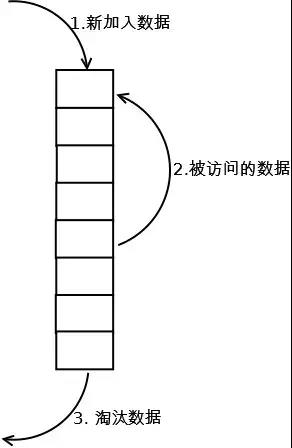
这个链表即是我们的缓存结构,缓存处理步骤为:1)、初始化一个定长的链表,用于表示缓存数据组成;
2)、当请求进来时,进行缓存,并按请求的先后顺序,加入到链表中,先加入的在底部,后加入的在顶部,重复的请求从链表尾部升至顶部;(最新被访问的数据相对其他数据来说可能是热点数据,具有保留时间更久的意义)
3)、当链表数据放满时,仍有新请求进来,且没有命中缓存,则先将底部的数据淘汰,也就是清除不常访问的数据,再将新数据缓存,加入到链表顶部。
-
LRU-K算法
其实上面的算法只是LRU算法中的特例情况即LRU-1,其中存在较多不合理性,在实际应用过程中会对该算法进行改进,例如偶然的数据影响会造成命中率较低,比如某个数据即将到达底部即将被淘汰,但由于一次请求又放入了头部,此后再无该数据的请求,那么该数据的继续存在其实是不合理的。针对这类情况,LRU-K算法拥有更好的解决措施。结构图如下所示:
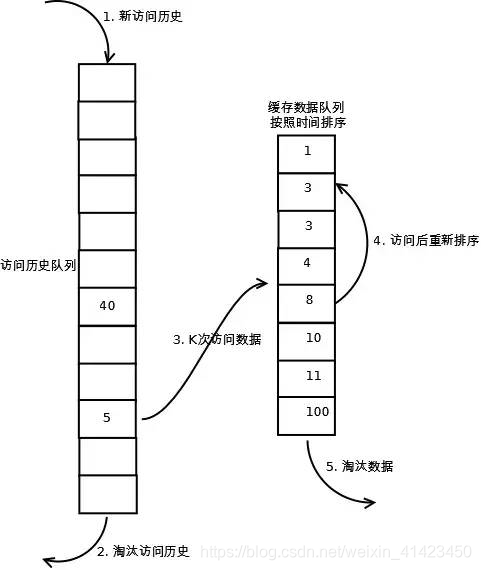
LRU-K需要多维护一个队列或者更多,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。1)、历史访问队列
将最新请求的数据放在历史访问队列头部,该队列遵循先进先出原则。(队列长度根据系统QPS来定)
每次有数据加入到队列中时,若队列已满,则从尾部淘汰数据,未满,则直接加在队列头部。再统计当前队列中当前数据在队列中出现的次数,若达到K次,则将它加入到接下来的2级(具体需要几级结构也同样结合系统分析)链表中,按照最新访问时间顺序在2级链表中排列。2)、2级链表
同上LRU-1算法,链表中的数据如果再次被访问,则移到头部,链表满时,底部数据淘汰。相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史,所以需要更多的内存空间来用来构建缓存,但优点也很明显,较好的降低了数据的污染率提高了缓存的命中率,对于系统来说可以用一定的硬件成本来换取系统性能也不失为一种办法。
-
折衷方案
针对LRU-1和LRU-K有一种折衷的方案,引入权重来实现在有限资源情况下的合理缓存。
1)、初始化一个队列,用于表示缓存数据组成;
2)、当新请求(未命中缓存)进来时,进行缓存,设定权重为当前队列中所有数据权重的中位数,并对队列进行重新排序;当请求进来(命中缓存时),对该数据权重+n,并对队列进行重新排序。
3)、当队列达到指定长度时,仍有新请求进来,且没有命中缓存,则先将底部的数据淘汰,也就是清除不常访问的数据,再执行第2步。
该方案的重点在于合理设置重新访问的权重n。