HashMap实现详解 基于JDK1.8
1.数据结构
散列表:是一种根据关键码值(Key value)而直接进行访问的数据结构。采用链地址法处理冲突。
HashMap采用Node<K,V>数组作为散列表来存储数据。源码声明如下:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;Node<K,V>节点的源码如下,可见Node<K,V>有四个成员。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 其余方法省略
}散列函数:HashMap的散列函数很简单,i = (n - 1) & hash,将hash值与Node<K,V>数组的大小n通过&运算即得到在Node<K,V>数组中的位置i。
2.关键变量
有几个关键的变量需要事先理解,源码定义如下:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 这一步位移运算,得到结果16,作为Node<K,V>数组的初始大小,每次扩容都为原先的2倍。
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 又称负载因子,定义了扩容的时机,默认为存储元素达到了16*75%时就要进行扩容。
static final int TREEIFY_THRESHOLD = 8;
// 因为采用链地址法处理冲突,当链表过长时,HashMap性能会下降,因此当链表的长度超过8时,会将链表转换为红黑树进行优化。
static final int UNTREEIFY_THRESHOLD = 6;
// 在哈希表扩容时,如果发现链表长度小于 6,则会由树重新退化为链表。
static final int MIN_TREEIFY_CAPACITY = 64;
// 只有存储数量大于 64 才会发生转换。这是为了避免在哈希表建立初期,多个键值对恰好被放入了同一个链表中而导致不必要的转化。3.put方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 判断散列表是否为空,若是,则进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 判断散列表位置是否冲突,若否,直接存储
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 处理冲突
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}put流程图
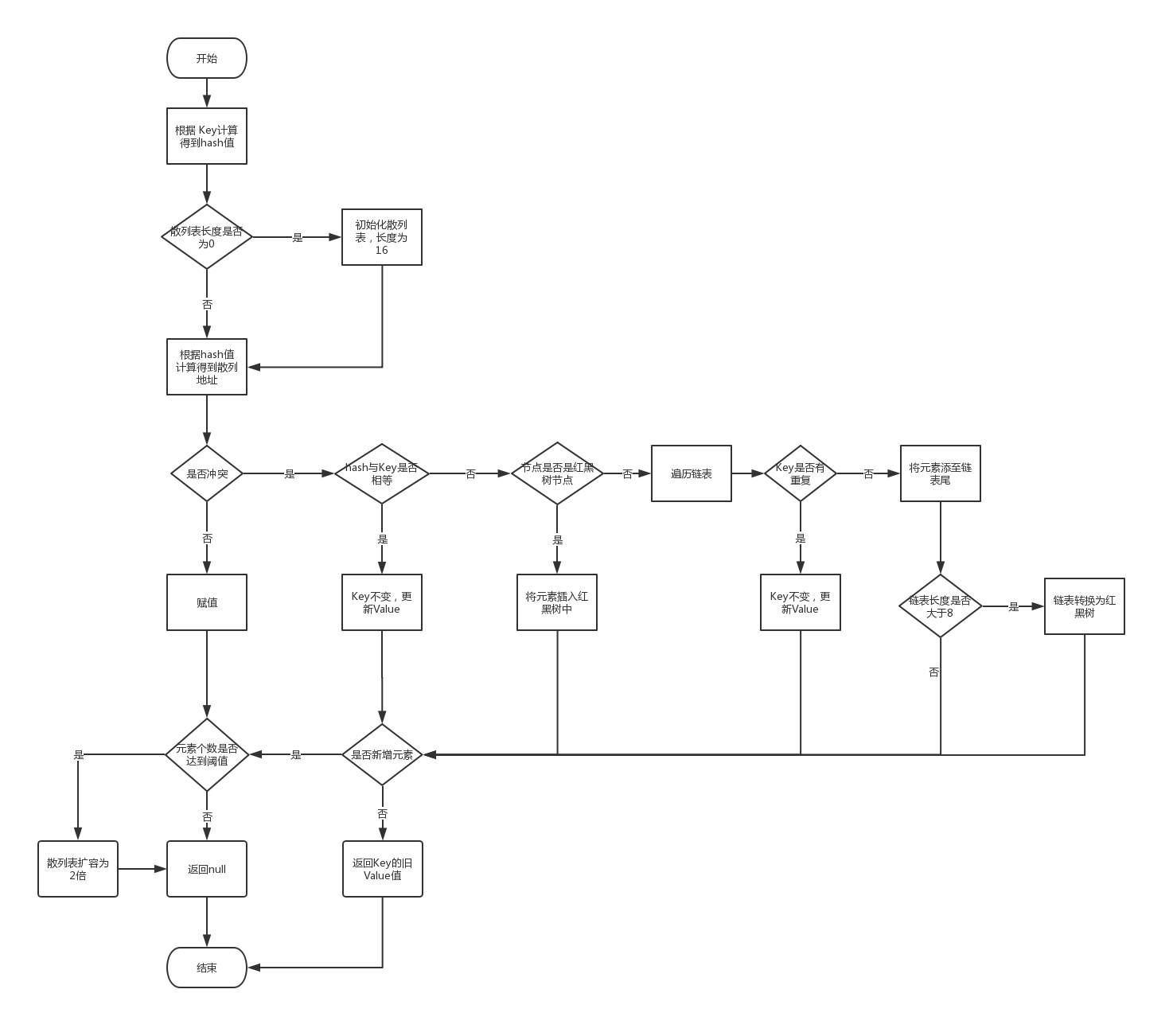
put流程总结:
1.根据Key计算hash,得到散列地址
2.若散列表大小为0,则初始化大小为16
3.若散列地址无冲突,则直接存储。若有冲突,则将元素存入链表或红黑树
4.当链表长度大于8,且总元素个数大于64时,将链表转换为红黑树
5.当总元素个数达到Capacity的75%时,将散列表扩容为2倍