什么是数据仓库
传统数据库(DataBase,DB)是长期存储在计算机内的、有组织的、可共享的数据集合。数据仓库(Data Warehouse,DW)是一个面向主题的、集成的、相对稳定的(不可修改的)、反映历史变化的(随时间变化的),支持管理决策的数据集合。数据仓库是一种特殊的数据库。
- 面向主题的
主题你想要的某种统计数据,例如住宾馆的时候需要登记个人信息,入住时间,入住天数等,就可以从中提炼出“宾馆入住”主题。
- 数据仓库的数据是集成的
数据仓库的数据主要用于分析决策,所以我们要掌握尽可能全面的数据。所谓数据集成,就是根据决策分析的主题需要,把原先分散的事物数据库、数据文件、Excel文件、XML文件等多个异种数据源中的数据,收集并汇总起来形成一个统一并且一致的数据集合的过程。
- 数据仓库是不可修改的
数据仓库的数据都是从数据源中抽取出来的历史数据,这些数据反映的是过去相当长一段时间内的状况,记录历史点上发生的事情。其数据处理主要是数据查询和统计分析,不涉及业务上的增删改查,所以不涉及数据的修改操作。
- 数据仓库的数据是随时间变化的
数据仓库需要随时间不断增加新的内容用于实时的统计分析。数据仓库随时间不断删除旧的数据,数据仓库的存储期限一般是(5~10)年,过期数据将会删除,这种方式是为了满足趋势性决策分析。数据仓库中的数据往往用于综合分析与按照时间段进行抽样分析。
ETL(数据仓库技术)
数据仓库的每一个主题所对应的数据源存放在各自分散的数据库或数据文件中,不仅数据格式不统一,而且还可能存在许多重复数据。此外,数据不可能直接从数据源中取到,因此,数据进入数据仓库之前,还必须应用数据清理、转换等数据预处理技术。这一步处理称为数据的ETL(Extract-Transform-Load,抽取-转换-加载)。
ETL工具kettle
kettle是基于java的ETL工具,kettle学习网站:http://www.kettle.net.cn/category/install
Kettle家族目前包括4个产品:Spoon、Pan、CHEF、Kitchen。
- SPOON 允许你通过图形界面来设计ETL转换过程(Transformation)。
- PAN 允许你批量运行由Spoon设计的ETL转换 (例如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面。
- CHEF 允许你创建任务(Job)。 任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了。
- KITCHEN 允许你批量使用由Chef设计的任务 (例如使用一个时间调度器)。KITCHEN也是一个后台运行的程序。
Hadoop框架
Hadoop是一个能够对大量数据进行分布式处理的软件框架。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行大量数据的高速运算和存储。Hadoop的框架最核心的设计就是:HDFS(分布式文件存储)和MapReduce(分布式计算框架)。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
- Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它有多个工作数据副本,确保能够对失败的节点重新分布处理。
- Hadoop 是高效的,因为它通过MapReduce并行处理,极大的加快数据的处理速度。
- Hadoop 还是可伸缩的,能够处理 PB 级数据。
HDFS
HDFS是Hadoop的分布式文件系统,它的作用是将超大的数据集存储到多台普通计算机上,并且可以提供高可靠性和高吞吐量的服务。它会将目标数据库的数据通过file的形式,进行分布式存储,读取数据时多服务器并行运行来提高读取效率。并且HDFS集群可以通过添加节点的方式进行扩容。一个HDFS群集由一个运行于master上的Namenode和多个运行于slave上的Datanode组成。
- 对存储大文件支持很好,不适用于存储大量小文件
- 通过流式访问数据,保证高吞吐量而不是低延时的用户响应
- 简单一致性,使用场景应为一次写入多次读取,不支持多用户写入,不支持任意修改文件
- 冗余备份机制,空间换可靠性(Hadoop3中引入纠删码机制,纠删码需通过计算恢复数据,实为通过时间换空间,有兴趣的可以查看RAID的实现)
- 移动计算优于移动数据,为支持大数据处理主张移动计算优于移动数据,提供相关接口。
- HDFS通过数据复制产生副本存储在集群的不同机器中,从而提高可靠性。
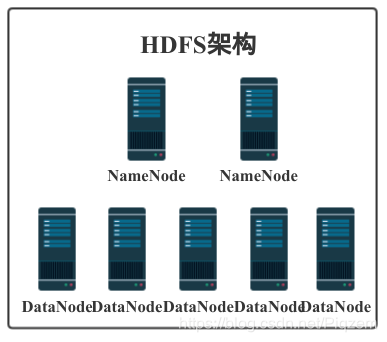
HDFS文件通常以文件块(block)的方式存储,块大小是可以在HDFS中读取或写入的最小数据量。块能将运行中的非常大的文件拆分并将其分发到许多计算机上。来自同一文件的不同块将被存储在不同的计算机上,以提供更高效的分布式处理。此外块将跨DataNode复制。默认情况下,块将被复制三份,但也可以在运行时配置。因此,每个块都将分布在三台计算机和三块磁盘上。即使两个节点都发生故障,数据也不会丢失。所以这也同时意味着集群中的潜在数据存储容量仅为可用磁盘空间的三分之一。
HDFS集群有两类节点,并以管理者-工作者(主从)模式运行,即一个NameNode(管理者)和多个DataNode(工作者)。一个HDFS cluster包含一个NameNode和若干的DataNode。
主从设备模式(Master-Slave)用于并行计算。
-
Namenode
NameNode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。NameNode也记录着每个文件中各个block(块)所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息在系统启动时由DataNode上报。
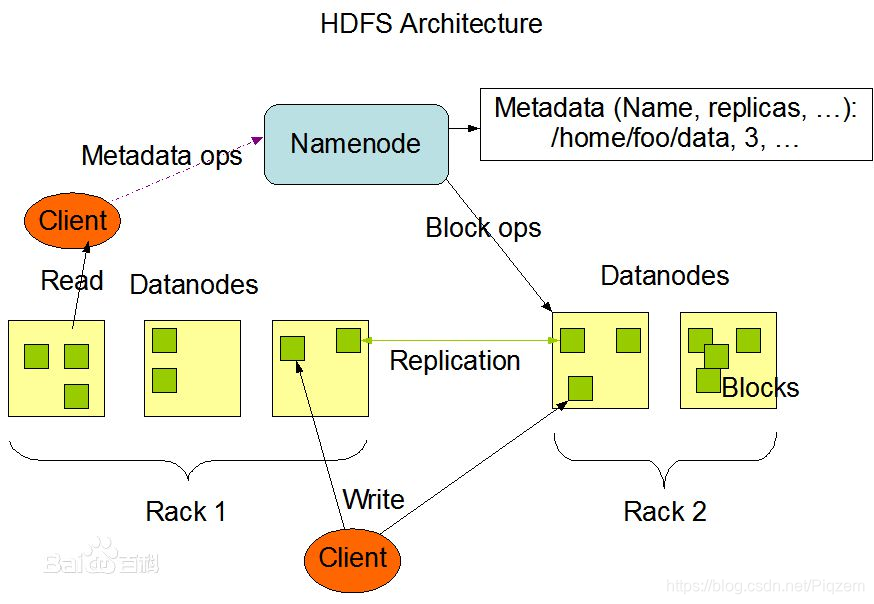
NameNode作为master,主要负责管理hdfs文件系统,具体地包括namespace管理(其实就是目录结构),block管理(其中包括 filename->block,block->datanode list的对应关系)。NameNode会保存文件系统的具体信息,包括文件信息、文件被分割成具体block的信息、以及每一个block块归属的DataNode的信息。 -
DataNode
DataNode就是数据节点,它负责存储数据,为客户端提供数据块的读写服务。通常每一个DataNode都对应于一个物理节点。DataNode负责管理节点上它们拥有的存储,它将存储划分为多个block块,管理block块信息,同时周期性的将其所有的block块信息发送给NameNode。
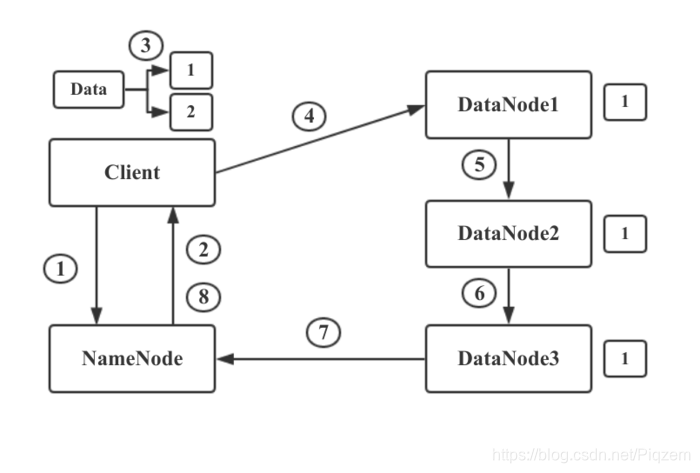
1.首先,HDFS Client和NameNode建立连接,告诉NameNode要存储一个文件。NameNode维护着DataNode的列表,知道哪些DataNode上面还有空间可以进行存储。
2.NameNode通过查看存储的元数据信息,发现DataNode1,2,3上可以进行存储。于是他将此信息返回给HDFS Client。
3.HDFS Client接受到NameNode的返回的DataNode列表后,Client会与距离最近DataNode1建立连接,让其准备好接收数据。然后将文件进行分块,将数据块1和NameNode返回的DataNode列表信息一起发送给DataNode1.
4.DataNode1通过列表信息得知要发送给DataNode2.所以DataNode1将数据与列表信息发送给DataNode2.DataNode2又发送给DataNode3,此时数据块1已经存储完成并备份了三份。
5.当DataNode1,2,3都接收并存储数据块1后,会向NameNode发送信息,告知已经接收到了数据块1.并把数据块1相关信息发送给NameNode,NameNode更新元数据信息并 与Client通信告知数据块1已经存储完毕。然后Client开始进行数据块2的存储。
还有一个重要的节点:Secondary NameNode,该部分主要是定时对NameNode进行数据快照,进行备份,这样尽量降低NameNode崩溃之后,导致数据的丢失,其实所作的工作就是从NameNode获得fsimage文件(快照)和edits文件(保存了所有对hdfs中文件的操作信息)把二者重新合并然后发给NameNode,这样,既能减轻NameNode的负担又能保险地备份。
MapReduce
MapReduce是一种编程模型,是面向大数据并行处理的计算模型、框架和平台,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
Sqoop
Sqoop是Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。

yarn
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
大数据任务调度框架
大数据架构图:
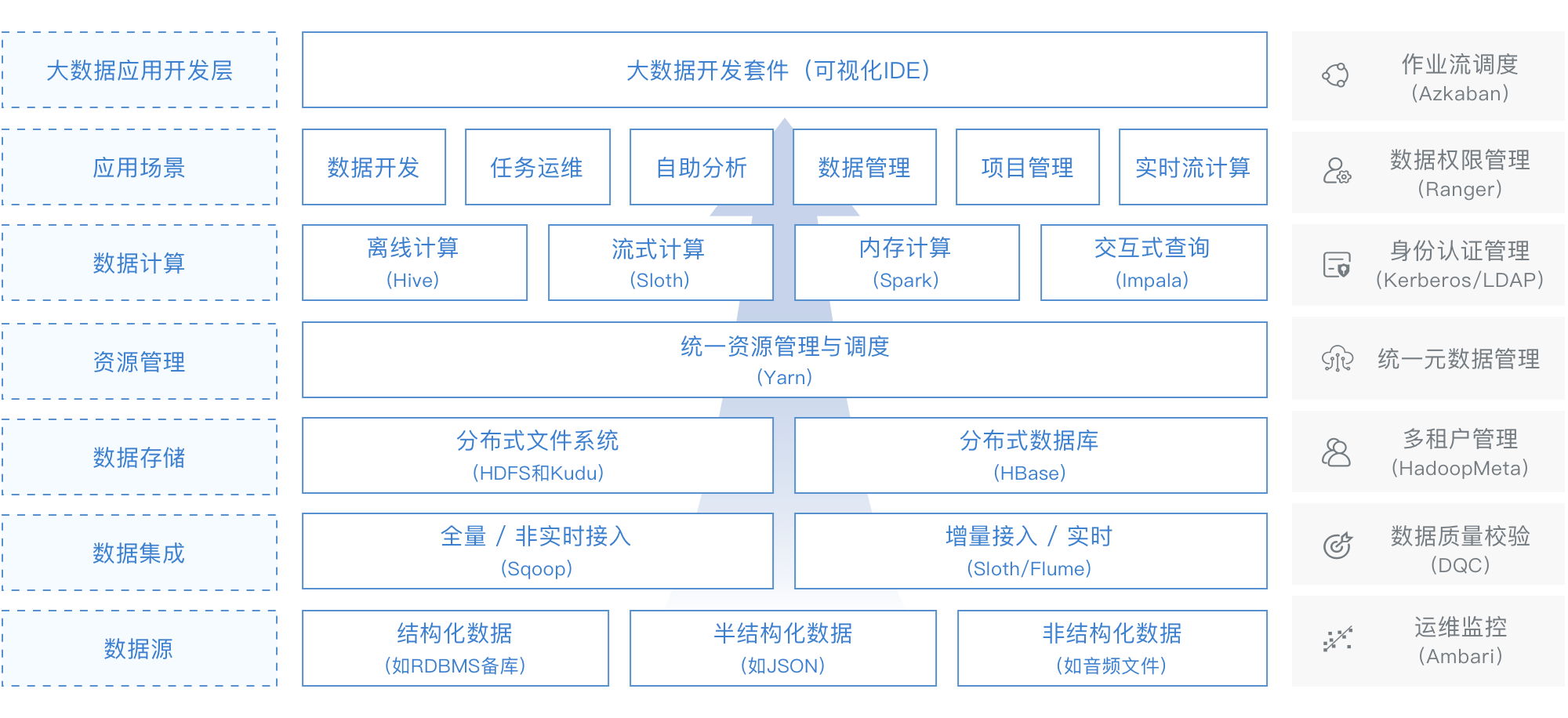
任务调度在大数据平台中所扮演的角色主要有:1.任务编排;2.任务调度执行3.运维功能
详情参考:https://blog.csdn.net/hxcaifly/article/details/84675149
目前主流的任务调度框架有:1.xxl job;2.Azkaban;3.elastic Job;4.Apache Oozie
Oozie
Oozie 是 Hadoop 任务调度框架。提供对Hadoop MapReduce和Pig Jobs的任务调度,。因为内部的web框架用到了Tomcat,所以需要部署到Java Servlet容器中运行。主要用于定时调度任务,多任务可以按照执行的逻辑顺序调度。
功能模块:
1.Workflow
顺序执行流程节点,支持 fork(分支多个节点),join(合并多个节点为一个)
2.Coordinator
定时触发 workflow
3.Bundle Job
绑定多个 Coordinator
节点:
1.控制流节点(Control Flow Nodes)
控制流节点定义了流程的开始和结束,以及控制流程的执行路径(Execution Path),如decision、fork、join等。
2.动作节点(Action Nodes)
动作节点包括Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、eMail和Oozie子流程。
详情参考:https://blog.csdn.net/qq_16095837/article/details/79827014
https://blog.csdn.net/Abysscarry/article/details/81784179
参考链接
https://www.aliyun.com/jiaocheng/128200.html?spm=5176.100033.2.12.147750b8gWkfaT
http://www.sohu.com/a/249595258_100123073
https://www.cnblogs.com/dmego/p/9068734.html
https://www.cnblogs.com/qingyunzong/p/8807252.html
https://blog.csdn.net/hxcaifly/article/details/84675149
https://blog.csdn.net/Forever_ck/article/details/85240348