什么是Sphinx?
Sphinx是Sql Phrase Index (查询词组索引)的缩写,Sphinx是一个基于Sql的全文检索引擎
Sphinx 全文检索引擎
Coreseek 支持中文的全文检索引擎
全文检索分两个过程
索引创建(Indexing)和搜索索引(Search)
索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程
搜索索引:得到用户的查询请求,搜索创建的索引,然后返回结果的过程
索引里面存些什么?(Index)
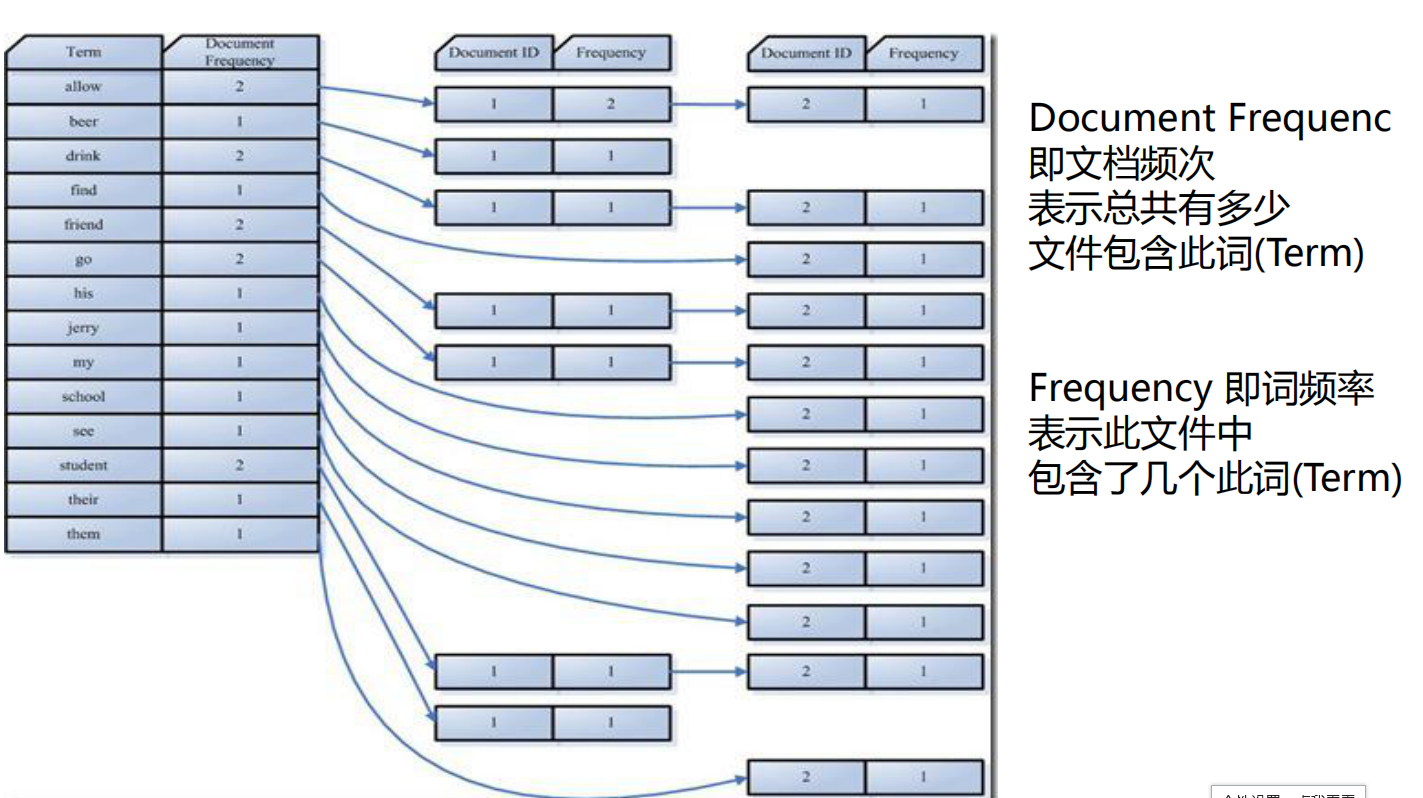
词典:保存的是一系列的字符串
倒排表:指向包含字符串的文档链表
如何创建索引?(Indexing)
全文检索的索引创建过程一般有以下几步:
1.一些需要创建索引的文档(Documents)。
2.将原文档传给分词组件(Tokenizer)。
分词组件(Tokenizer)会做以下事情(此过程称为Tokenize):
a、将文档分成一个一个单独的单词
b、去掉标点符号
c、去掉停词(stop word)【停词是语言中最普通的一些单词:英语中的“the”、“a”、“this”等;中文的“是”、“的”、“这个”等】
对于每一种语言的分词组件(Tokenizer),都有一个停词(stop word)的集合。
d、经过分词(Tokeninzer)后得到的结果称为词元(Token)。
3.将得到的词元(Token)传给语言处理组件(Linguistic Processor)
语言处理组件主要是对得到的词元做一些同语言相关的处理:
对英语,语言处理主件一般做以下几点:
a、变小写(Lowercase)
b、将单词缩减为词根形式 如“cars”->car (称为stemming)
c、将单词转化为词根形式,如“drove”->drive (称为lemmatization)
4.将得到的词(Term)传给索引组件(Indexer)
索引主件主要做以下事情
a、利用得到的词(term)穿件一个字典。
b、对字典按字母顺序进行排序
c、合并相同的词(Term)成为文档倒排(Posting List)链表
如何对索引进行搜索?(Search)
搜索主要是以下几步
a、用户输入查询语句
b、对查询语句进行词法分析,语法分析,以及语言处理
c、搜索索引,得到符合语法树的文档
d、根据得到的文档和查询语句的相关性,对结果进行排序
对创建索引和搜索做一个总结:
1. 索引过程:
a) 有一系列被索引文件
b) 被索引文件经过语法分析和语言处理形成一系列词(Term)。
c) 经过索引创建形成词典和反向索引表。
d) 通过索引存储将索引写入硬盘。
2. 搜索过程:
a) 用户输入查询语句。
b) 对查询语句经过语法分析和语言分析得到一系列词(Term)。
c) 通过语法分析得到一个查询树。
d) 通过索引存储将索引读入到内存。
e) 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
f) 将搜索到的结果文档对查询的相关性进行排序。
g) 返回查询结果给用户。