注:笔者主要用来做二分类,另笔者的环境是windows,linux可以参考步骤但代码不能完全照搬,网上出现的一系列问题都是因为环境不一样。
一.数据集准备
1.自己数据集标注
首先看一下标准数据格式
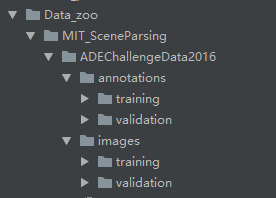
annotation文件夹放的是train和valid的label文件,具体形式是图片(png),image文件夹放的是原照片(jpg),两个文件夹的内容除了图片格式有区别外,文件名等必须一一对应。ok,所以我们的第一步应该是制作自己数据的label,第一步下载labelme标注软件labelme地址,使用很简单教程自己百度,运行labelme打开取名标注即可,点击Save后会生成改图片对应的json文件
2.标注生成的json文件转化成png标注图片(以一张图片为例)
第一步json文件转化
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
json_file = 'F:/Graduate//'#记得改成自己地址
list = os.listdir(json_file)#返回指定文件夹包含文件列表
for i in range(0, len(list)):
path = os.path.join(json_file, list[i])
filename = list[i][:-5] #(生成.json)
if os.path.isfile(path):
data = json.load(open(path))
img = utils.img_b64_to_arr(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
# 返回最后文件名bo_json
out_dir = osp.basename(list[i]).replace('.', '_')
out_dir = osp.join( json_file,out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)#自动创建目录
PIL.Image.fromarray(img).save(osp.join(out_dir, '{}.png'.format(filename)))
PIL.Image.fromarray(lbl).save(osp.join(out_dir, '{}_gt.png'.format(filename)))
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, '{}_viz.png'.format(filename)))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
# 转化后会生成五个文件,我们需要的是_gt.png,可能是全黑的,不过没关系,按操作来就好
第二步将生成的16位图片(_gt.png)转化成8位
from PIL import Image
import numpy as np
import math
import os
path = 'F:/Graduate/cocoon_image/cocoon_seg/daichuli/batch_png/'
newpath = 'F:/Graduate/cocoon_image/cocoon_seg/daichuli/batch_png/'
def toeight():
filelist = os.listdir(path) # 该文件夹下所有的文件(包括文件夹)
for file in filelist:
whole_path = os.path.join(path, file)
img = Image.open(whole_path) # 打开图片img = Image.open(dir)#打开图片
img = np.array(img)
# img = Image.fromarray(np.uint8(img / float(math.pow(2, 16) - 1) * 255))
img = Image.fromarray(np.uint8(img))
img.save(newpath + file)
toeight()
至此label的png图片就准备好了,全部放进annotation文件对应位置就好,在整理数量较大的label你还需要这样的代码,即从大量json文件转化的文件里把需要的16位png全部拿出来(批量转化8位)
# 批量获取label.png文件
#只需将GT_from_PATH设置为所有json文件夹所在根目录即可
import os
import random
import shutil
import re
GT_from_PATH = "F:/Graduate/"
GT_to_PATH = "F:/Graduate/"
def copy_file(from_dir, to_dir, Name_list):
if not os.path.isdir(to_dir):
os.mkdir(to_dir)
for name in Name_list:
try:
# print(name)
if not os.path.isfile(os.path.join(from_dir, name)):
print("{} is not existed".format(os.path.join(from_dir, name)))
shutil.copy(os.path.join(from_dir, name), os.path.join(to_dir, name))
# print("{} has copied to {}".format(os.path.join(from_dir, name), os.path.join(to_dir, name)))
except:
# print("failed to move {}".format(from_dir + name))
pass
# shutil.copyfile(fileDir+name, tarDir+name)
print("{} has copied to {}".format(from_dir, to_dir))
if __name__ == '__main__':
filepath_list = os.listdir(GT_from_PATH)
# print(name_list)
for i, file_path in enumerate(filepath_list):
gt_path = "{}/{}_gt.png".format(os.path.join(GT_from_PATH, filepath_list[i]), file_path[:-5])
print("copy {} to ...".format(gt_path))
gt_name = ["{}_gt.png".format(file_path[:-5])]
gt_file_path = os.path.join(GT_from_PATH, file_path)
copy_file(gt_file_path, GT_to_PATH, gt_name)
至于准备数据集过程中,还需要批量重命名的同学可以下载一个2345看图王,至此数据集准备结束,记住最后的标签图片一定要是8位,不放心的鼠标右键看一下图片深度,即代表几位
二.开始训练自己数据
给出我的github地址,觉得不错的同学麻烦给个star哈
https://github.com/ferryer/FCN-tensorflow-hzp
1.然后下载VGG网络的权重参数,下载好后的文件路径为./Model_zoo/imagenet-vgg-verydeep-19.mat.地址
2.把自己数据集放入,代替./Data_zoo/MIT_SceneParsing/ADEChallengeData2016文件
3.训练时把FCN.py中的全局变量mode改为“train”,运行该文件,测试时修改测试函数里的图片地址,并把mode改为“test”运行即可
注:代码看不懂的可看我另一篇博客FCN-tensorflow代码超详解