所有章节:
- 1、计算机基础
- 2、面向对象
- 3、代码风格
- 4、走进JVM
- 5、异常与日志
- 6、数据结构与集合
- 7、并发与多线程
- 8、单元测试
- 9、代码规约
只记录重点知识,粗略读了一下,适合初级向中级晋升的一种学习路线手册。以及想补充一下,其实阿里用他的行为,以及走过的路做了下经验汇总,为了避免未来程序猿走同样的坑。某种意义上,如果想进入阿里的话,这本书是值得看的。如果不想进入阿里,想对于一个手册也是值得看的。由于书的内容都是浅尝辄止,就是你看书实际上只是了解,知识并不深入,想要深入,那我们还是看源码,而这个看源码,到目前为止,我还没找到好的方式。网上的例子也是只是拿书模仿的很多,想要进阶,还是得找到属于自己的路。摸索…
1、计算机基础
带着问题读书:
1、位移运算可以快速地实现乘除运算,那位移需要注意什么?
2、浮点数的存储与计算为什么总会产生微小的误差?
3、乱码产生的根源是什么?
4、代码执行时,CPU是如何与内存配合完成程序使命?
5、网络连接资源耗尽的问题本质是什么?
6、黑客攻击的通常套路是什么?如何有效防止?
0&1的考察点:
二进制:逢2进1.
二进制与十进制的转变
1=1–》2^0=1;
10=2–》2^1=2;
补码,原码,反码
正数的补码与原码、反码是一样的,而负数的补码是反码加1的结果
35+(-35)
从整数来表示,2^8=256,也就是我们常说的-128~127是我们int整数的范围
补充知识(之前的笔记):
https://note.youdao.com/ynoteshare1/index.html?id=460e97abd59f6cf9e5e44aa0ebe1e3cc&type=note#/
https://note.youdao.com/ynoteshare1/index.html?id=e51f9e4f9a7f06398708a33b6c8e66a6&type=note#/
https://note.youdao.com/ynoteshare1/index.html?id=c3f8f98f09a26b5b755d99e09cb591f4&type=note#/
位移运算(>> <<)
0标识正数、1代表负数
右移1位近似表示除以2,对于奇数并非除以2,只有负数往右移动高位补1,其他均在空位补0
红色字体是原有数据位,绿色是标记识别移动方向
无符号位移运算(>>> <<<)
无符号意味着,不会存在正数和负数以及其他特殊场景。通通按照普通方式处理,左移或者右移
备注:位移运算常用于整型(32)和长整型(64),所以无论是否带符号位以及移动方向,均为本身。


引申:位运算中的短路问题
&& 与 &的区别。|| 与|的区别。
举例说明:
boolean a=true;
boolean b= true;
boolean c =(a =(12)) && (b=(12))
结果a为false,b为true,但是&的情况下则ab都为false。
异或运算没有短路功能,对应位不一致则为1,一致则为0
true^true=true ,true^false=false
浮点数的双刃剑
科学计数法:计算机用来表示小数的一种数据类型
表示方法:
标准:IEEE754
4种类型:单精度、双精度、延伸单精度、延伸双精度
因为浮点数无法表示0值,所以取值范围分为2个区间:正数区间和负数区间
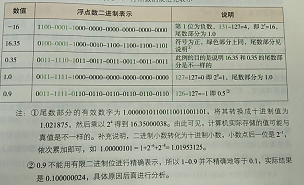
如上图32位单精度,
红色部分为符号位,正数0,负数1
绿色部分为阶码位,存储的是指数对应的移码而不是指数的原码或者补码。移码是将一个真值在数轴上正向平移一个偏移量得到的。移码的几何意义是把真值映射到一个正数域,其特点是可以直观反映两个真值的大小即,移码大的真值也大。
黄色部分为尾数位,正指数和有效数字的最大值决定了32位存储空间能够表示浮点数的十进制最大值。
计算机规定:阶码全是0为机器0,全是1为无穷大。
浮点数的规格化表示
加减运算:
先将小数点对齐,然后同位数加减运算。
1、0值检测(0在浮点数是一种规定,阶码和尾数全是0)
2、对阶操作(比较阶码的大小判断小数点位置是否对齐。阶码不相等则表示当前两个浮点数的小数点位置没有对齐,需要移动尾数改变阶码的大小使其相等,这个过程叫做对阶)IEEE754规定对阶的移动方向为向右移动,阶码值加1。
3、尾数求和,按位相加(如果负数需要先转换成补码再进行运算)
4、结果规格化,如果结果不满足规格化,尾数位需要左移或者右移,专业叫法:左规,右规
5、结果舍入,最终结果由于左规和右规导致精度损失,所以为了减少精度损失,会将移出的数据保存起来,称为保护位。等到规格化以后根据保护位进行四舍五入。
所以使用浮点数,推荐使用双精度。
数据库精度要求比较高,推荐使用decimal类型,禁止使用float和double


字符集与乱码
系统的换行区别:
UNIX系统和新版macOS系统换行符“\n”,windows系统“\r\n”,旧版 macOS系统“\r”
字符集Unicode(utf-8/utf-16/utf-32/utf)还是GBK
utf-8是一种以字节为单位,针对Unicode的可变长度字符编码,用1~6个字节对Unicode字符进行编码压缩,目的是用较少的字节标识最常用的字符。可以有效降低数据存储和传输成本。
CPU与内存
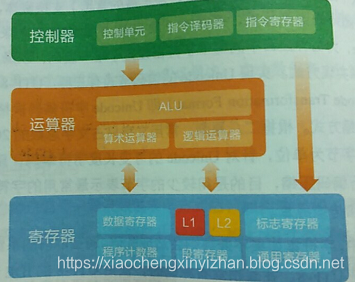
SPU的内部结构
控制器:控制单元,指令译码器,指令寄存器组成。控制单元是CPU的大脑,由时序控制和指令控制等组成。指令译码器是在控制单元的协调下完成指令读取,分析并交由运算器执行等操作。指令寄存器是存储指令集,当前流行的指令集包括X86/SSE/MMX等。控制器有点像一个编程语言的编译器,输入0和1的源码流,通过译码和控制单元对存储设备的数据进行读取,运算完成后,保存回寄存器,甚至是内存。
运算器:核心是算术逻辑运算单元ALU.被CPU控制。平时说的栈和堆都是CPU眼里的内存。
寄存器:高速缓存L1和L2.就是最最著名的寄存器。提升CPU性能可以是多核CPU(一块基板封装多个core),另外一个就是超线程,一个core可以执行多个线程。
计算机存储方式
TCP/IP协议
TCP/IP中文译为传输控制协议系/因特网互联协议
比如:http,https,ftp,smtp,udp,arp,ppp,IEEE802.x等
另外一个是ISO/OSI的七层传输协议。
应用层 Http/ftp/smtp
传输层 tcp/udp
网络层 ip/arp
链路层 IEEE802.x/PPP
程序在发送消息,应用层按照约定的协议打包数据,随后由传输层加上双方的端口号,由网络层加上双方的ip地址,链路层加上双方的mac地址,并将数据拆分数据帧,经过多个路由器和网关后,到达目标机器。
端口—》Ip地址—》mac地址。解包顺序反过来就可以。
IP协议
IP是面向无连接,无状态的,没有额外的机制保证发送的包是否有序到达。IP首先规定Ip地址格式,进行网段的划分,给每台计算机额外设置一个唯一的详细地址。虽然mac地址唯一,IP依然唯一是为了快速缩小范围,提升性能。IP地址属于网络层,主要功能在WLAN内进行路由寻址,选择最佳路由。
举个例子:手机上通过微信给PC端微信发送hello world,首先经过无线网的IEEE802.1x认证,转到光纤通信,然后进入内部企业网802.3,并最终到达PC电脑端。硬件的不同配置导致数据帧的长度不同,最大长度被称为最大传输单元,MTU。不同物理网之间需要对IP报文分片,这个工作是路由器完成的。
TCP建立连接
传输控制协议
http–80端口,HTTPS–443端口,ssh—22端口
重点面试常问的问题:
TCP的三次握手原理
TCP的FLAG位由6个bit组成。分别代表SYN,ACK,FIN,URG,PSH,RST。都为1的时候有效。
其中SYN(synchronize sequence number)建立连接时候的同步信号。ACK(Acknowledgement)用于对收到的数据进行确认,所确认的数据由确认序列号标识。FIN(finish)表示后面没有数据需要传送,通常意味所建立的链接需要关闭。
其他字段可以通过点击这里
1、A机器发送一个数据包并将SYN置为1,标识希望建立连接。序列号假设x
2、B机器收到A机器,通过SYN得知这是建立连接的请求,于是发送一个响应包,SYN和ACK都设置为1,假设响应包中序列号是y,这个确认序列号ACK就是x+1,表示收到了A机器发送过来的SYN。在tcp中,SYN被当做数据部分的一个字节。
3、A收到B的响应包后需要进行确认,确认包中将ACK设置为1,并将确认序列号设置为y+1,表示收到了来自B的SYN。
总结下就是,男:我喜欢你(SYN),我的座位号是x(seq)
微信闪了一下,咚咚有新的未读消息。
女:表白信息已经确认收到(ACK),我的座位号是y(seq) , 你要是愿意你去你旁边的座位以证明你爱我x+1(ack),发送过去(SYN)
咚咚,男生收到一条消息
男:确认收到(ACK),我现在在我旁边的座位号x+1(seq),我把好吃的零食放你旁边的座位y+1(ack)
为什么需要第三次握手?
信息对等和防止超时:
因为如果男生不回复的话,女生无法确认自己的信息发送给男生,以及男生愿意接受自己的要求
如果男生第一次发送信息请求超时,又重新发送了一次请求信息。那么这个时候超时请求也发送给女孩了,第二次请求也发送给女孩了,女孩误以为俩个人对她示好。
如果想要查看当前系统各个进程产生了多少句柄
lsof -n | awk ‘{print $2}’| sort | uniq -c | sort -nr |more
想要知道具体应用程序是谁根据PID
ps -ax | grep XXX(PID)
TCP的四次挥手:
男生:我们分手吧(FIN=1),家里的东西你收拾下(seq=u)。
女生:(强忍泪水)好的(ACK=1),我收拾自己东西(seq=v),收拾完了我告诉你(ack=u+1)(此时男生不能再要求女孩跟她拥抱和亲吻)(几个小时以后—男生等待女生回复的时间CLOSE_WAIT)
女生:我收拾好了(FIN=1),我们分手吧(ACK=1)(女孩也不能再有要求男生跟他逛街买东西),一刀两段(seq=w,ack=u+1)
男生:好的(ACK=1)。同意你的一刀两段(seq=u+1,ack=w+1)(约定为了缓存期,2个月以后再对外宣布,重新找对象----TIME_WAIT)
为什么这里需要2分钟(2个月)的报文等待期?不立马一刀两段?
1、男生负责任的表现,需要确保女生能够顺利进入单身(closed)状态。如果直接就一刀两段,对外界公布,然后女生如果没有走出来的话,可能会有危害(想不开,自杀等)。
2、防止失效请求。如果是一时的冲动和生气说出的话,但是已经后悔了失效了,这样就会发生混淆。
服务器上可以通过变更/etc/sysctl.conf文件来修改该省略值net.ipv4.tcp_fin_timeout=30(建议小于30s)
修改完执行/sbin/sysctl -p让参数生效
netstat -n | awk '/^tcp/ {++S [$NF]} END {for {a in S} print a,S[a]}'
连接池的引申
数据库层面的请求应答时间一般为0.1s以内。
处理方案:
高效而且合理的索引
排查连接资源未显示关闭的情形(threadLocal或流式计算中使用数据库连接的地方)
合并短的请求(合并请求减少连接的次数)
合理拆分多个表join的SQL,若是超过三个表则禁止join(多表关联,确保被关联的字段要有索引)
使用临时表(把中间结果保存到临时表,重建索引,再通过临时表进行后续的数据操作)
应用层优化(数据结构优化,并发多线程改造)
改用其他数据库(Cassandra,MongoDB)
信息与安全
DDos攻击、CSRF攻击、
攻击手段:病毒式、洪水式、系统漏洞式
CIA原则:保密性(Confidentiality)、完整性(Integrity)–MD5和数字签名、可用性(Availability)—使用控制和限流
XSS与CSRF
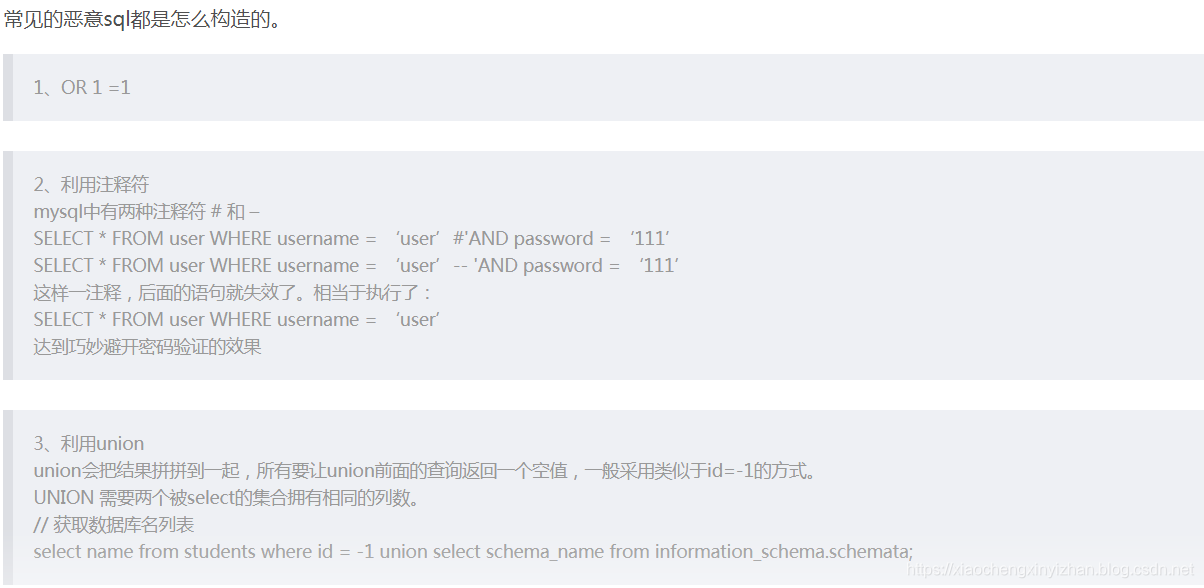
XSS跨站脚本攻击(html页面恶意代码)
反射型XSS/存储型XSS/DOM型XSS
如何防范:
Jsoup框架对用户输入字符串过滤,或者对Html进行转义,或者使用HtmlUtils
Self-XSS,用户恶意被诱导,目前没有防范机制。
CSRF跨站请求伪造(http接口没有防范)
防范方式:CSRF Token验证,利用浏览器的同源限制,在http接口执行前验证页面或者Cookie中设置的token,只有验证通过才继续执行请求。
人机交互,比如校验短信验证码,或者人工识别图片。点击图片的滑块等
Https
http+SSL协议的加密能力
对称加密
非对称加密
数字证书
计算机的基本结构
输入设备(键盘)----》存储器(内存中)—》控制器和运算器(逻辑运算和数据处理)—》输出设备(屏幕)
2、面向对象
OOP
抽象、封装、继承、多态
抽象:是后续的封装,继承,多态的基础
封装,是一种对象功能内聚的表现形式,使模块之间耦合度变低,更具有维护性
多态,使模块在复用性基础上更加有扩展性,使系统运行更有想象空间
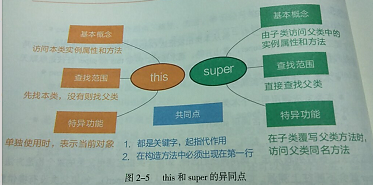
Object的getClass,toString,Object(),clone(),finalize()—jdk9+过时不使用.hashCode(),equals(),wait(),notify()—被同步信号,锁,阻塞集合替代
clone分为浅拷贝,深拷贝,彻底拷贝。
浅拷贝是指复制当前对象的所有基本数据类型,以及相应的引用变量,但没有复制引用变量指向的实际对象。
彻底拷贝是成功clone后,此对象与母对象在任何引用路径都不存在共享的实例对象,由于JVM底层对象可能是完全共享的,所以引用路径越深,则实现难度越大。
深拷贝:重写clone方法实现引用对象的深度遍历拷贝。
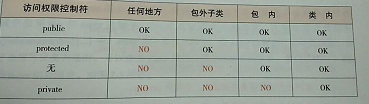
在无法确定应该是抽象类还是接口的时候,优先于接口,遵循接口隔离原则,可方便后续的扩展和重构

内部类(编译后的格式outClass$InnerClass.class):
静态内部类 static class StaticInnerClass{}:好处作用域不会扩散到包外,外部类.内部类直接访问,内部类可以访问外部类所有静态的属性和方法。
成员内部类 private class InstanceInnerClass{}
局部内部类(方法或者表达式内部)
匿名内部类(new Thread(){}).start()

序列化问题
Java原生序列化
java可以通过实现Serializable接口来实现该类对象的序列化,兼容性最好,但不支持跨语言。
实现接口以后如果不显示指定serialVersionUID,每次运行时候,编译器会根据类的内部实现,包括类名,接口名,方法和属性等来自动生成serialVersionUID,如果类的源代码有改动,则重新编译后的取值可能会变化,所以需要显示定义。
如果是兼容升级,请不要修改serialVersionUID,避免反序列化失败
如果是不兼容升级,需要修改serialVersionUID,避免反序列化混乱。
注意点:Java反序列化时候不会调用类的无参构造方法,而是调用native方法将成员变量赋值为对象类型的初始值。基于性能和兼容性,不推荐。
Hessian序列化
Hessian序列化是一种支持动态类型,跨语言,基于对象传输的网络协议。Java对象的序列化的二进制流可以被其他语言(C++,Python)序列化。Hessian协议如下:
自描述序列化类型。不依赖外部描述文件或接口定义,用一个字节表示常用基础类型,极大缩短二进制流。
语言无关,支持脚本语言。
协议简单,比java原生序列化高效
2.0版本增加了压缩编码,二进制流大小是java序列化的50%,耗时是30%,反序列化是20%。
Hessian会把复杂对象所有属性存储在一个Map中进行序列化,父类和子类存在同名成员变量的情况下,Hessian序列化会先序列化子类,然后序列化父类。因此反序列化会导致子类的同名成员变量被父类覆盖掉。
JSON序列化
轻量级的数据交换格式
JSON序列化是将数据对象转换为JSON字符串。敏感属性不需要序列化传输,可以加transient,避免把此属性信息转化为序列化的二进制流。
方法
方法签名—包括方法名称和参数列表,是JVM标识方法的唯一索引不包括返回值,更不包括访问权限控制符,异常类型等。
参数
形参和实参。
形参是方法定义阶段
实参是方法调用阶段。
可变参数
参数类型… args
构造方法
构造方法名称必须与类名相同
构造方法是没有返回类型的,void也不能有,他返回的对象的地址,并赋值给引用变量
构造方法不能被继承,不能被覆写,不能被直接调用,调用方式三种,new,反射机制,super
类定义时候提供了默认的无参构造方法
构造方法可以私有
静态代码块和构造方法的执行顺序
可以参考这里
方法的重写口诀
一大两小两同
一大:子类的方法访问权限控制符只能相同或变大
两小:抛出异常和返回值只能变小,能够转型成父类对象。子类的返回值、抛出异常类型必须与父类的返回值、抛出异常类型存在继承关系
两同:方法名和参数必须完全相同。
父子方法循环调用会导致JVM奔溃了,发生stackOverflowError
方法的重载(静态绑定—编译的时候已经知道调用哪种目标方法)
string.valueOf
规则:
精确匹配
如果是基本数据类型,自动转化为更大表示范围的基本类型
通过自动拆箱和装箱
通过子类向上转型继承路线一次匹配
通过可变参数匹配
泛型
本质是类型参数化,解决不确定具体对象类型的问题。
约定规则:
E代表Element,T代表the type of Object。K代表某个key,V代表某个value
类型擦除-----CHECKCAST会在运行时候检查对象实例的类型是否匹配,如果不匹配则抛出运行时候的异常ClassCastException。编译期的检查。
使用泛型的好处:
类型安全,不用担心会抛出类型转换异常
提升可读性,从编码阶段就知道泛型集合,泛型方法等处理的对象类型是什么》
代码重用,泛型合并了同类型的处理代码,代码重用性提高。
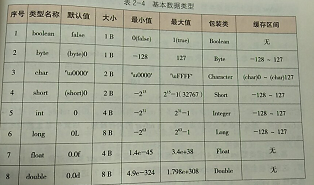
基本数据类型
如果说9种基本数据类型的话则还有一种refvar是面向对象世界中的引用变量,也叫引用句柄。
引用分为2种数据类型:引用变量本身refvar和引用指向的对象refobj。
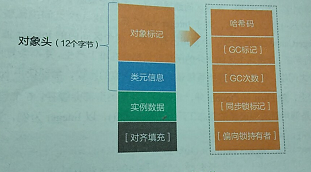
refvar是基本的数据类型,默认值是null,存储refobj的首地址,可以直接使用双等号进行等值判断。无论refobj多小的对象,最小占用的存储空间是12B(用于存储基本信息,称为对象头),但由于存储空间分配必须是8B的倍数,所以至少是16B初始的时候。而refvar均占4B空间。所以Integer可以推断占用16B(12Brefobj+4Bint)
对象头的内部结构:
对象头:
对象标记在64位jvm上占用8个字节,类元信息存储的是对象指向它的类元数据(Klass)的首地址,占用4个字节,与refvar一样
实例数据:
存储本类对象的实例成员变量和所有可见的父类成员变量。
对齐填充:
对象存储空间分配单位是8字节,如果一个占用大小16字节的对象增加一个byte类型,此时需要17个字节,但是也会分配24个字节进行对齐填充操作。
包装类型为什么推荐使用equal方法
包装类的存在解决了基本数据类型无法做到的事情:泛型类型参数、序列化、类型转换、高频区间数据缓存。Integer会缓存-128~127之间的值。对于Integer var=?在-128~127之间的赋值,Integer对象由IntegerCache.cache产生,会复用已有对象,这个区间Integer值可以直接使用IntegerCache.cache产生。会复用已有的对象,这个区间内的值可以使用==判断,但是不在该区间的所有数据都在堆上产生,并不会复用已有对象。所以推荐equals。
推荐使用包装类型还是基本数据类型
所有的POJO类属性必须使用包装数据类型
RPC方法的返回值和参数必须使用包装数据类型
所有的局部变量推荐使用基本数据类型
String与stringBuilder和StringBuffer的老掉牙问题
3、代码风格
- 符合语言特征
- 体现元素特征
- 命名望文知意
常量:全局或者类常量:字母全部大写,单词 之间加下划线,局部常量采用小驼峰就可以
可以使用枚举类来避免魔法值。
变量:不可变变量,可变变量
针对Boolean类型,命名不要加is前缀
代码展示风格
缩进,空格,空行
缩进–4个空格
空格–间距之间最好都有空格
空行–不同逻辑,不同语言,不同业务等等
换行与高度(单行字符数不超过120个字符)
方法行数限制(单个方法的总行数不超过80行)
控制语句(if,switch,三目运算,for,while,do-while)即使只有一句也要大括号
在条件表达式中不允许有赋值操作,也不允许判断表达式中出现复杂的逻辑组合
多层嵌套不能超过3层
避免使用取反逻辑运算符
代码注释
精简、易读,同步修改
注释格式:
Javadoc规范:文档注释,枚举类的删除修改标记位过时,不可直接删除属性,注释加上修改时间
简单注释:单行注释和多行注释
4、走进JVM
深入理解java虚拟机
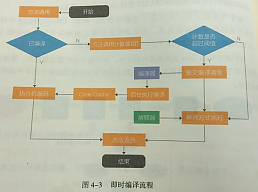
字节码有三种执行模式:解释执行、JIT编译执行、JIT编译与解释混合执行(主流JVM默认执行模式)
混合执行模式的优势在于解释器在启动时候先解释执行,省去编译时间。随着时间推荐,JVM通过热点代码统计分析,识别高频的方法调用,循环体,公共模块等,基于强大的JIT动态编译技术,将热点代码转换成机器码,直接交给CPU执行。JIT的作用是将java字节码动态的编译成可直接发送给处理器指令执行的机器码。
注意点:机器在热机状态下可以承受的负载要大于冷机状态(刚启动时候),如果以热机状态的流量进行切流,可能使处于冷机状态的服务器因为无法承载流量而假死。
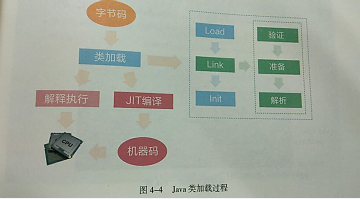
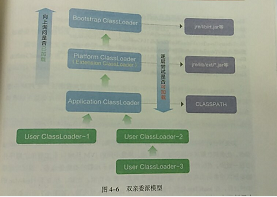
类加载过程:提前加载.class类文件到内存中,在加载的时候双亲委派模型,也叫做溯源委派加载模型
第一步:Load阶段读取类文件产生二进制流,并转化为特定的数据结构,初步校验cafe bable魔法数、常量池、文件长度、是否有父类等,然后创建对应类的java.lang.Class实例。
第二步:Link阶段包括验证,准备,解析三个步骤。验证是更详细的校验,比如final是否合规,类型是否正确,静态变量是否合理等。准备阶段是为静态变量分配内存,并设定默认值,解析类和方法确保类与类之间的相互引用正确性,完成内存结构布局。
第三步:Init阶段执行类构造器方法,如果赋值运算是通过其他类的静态方法来完成的,那么会马上解析另外一个类,在虚拟机栈中执行完毕后通过返回值进行赋值。
类加载就是一个将.class字节码文件实例化成Class对象并进行相关初始化的过程。
JVM中增加如下启动参数,则能通过Class.forName正常读取到指定类,说明此参数可以增加Boostrap的类加载路径
-Xbootclasspath/a:/Users/yangguanbao/book/easyCoding/bjJdk11/src
如果想在启动的时候观察加载了哪个jar包的哪个类,可以增加-XX:+TraceClassLoading
什么时候需要自定义类加载器?
隔离加载类:
某些框架内进行中间件与应用的模块隔离,把类加载到不同的环境
修改类加载方式
类的加载模型并非强制,除Boostrap外,其他的加载并非一定要引入,或者根据实际情况在某个时间点进行按需动态加载
扩展加载源
从数据库、网络、甚至是电视机顶盒加载
防止源码泄露
编译加密,所以加载器需要自定义,还原加密的字节码
简单实现自定义类加载:
继承ClassLoader,重写findClass方法,调用defineClass()方法
package test;
import java.io.FileNotFoundException;
/**
* @author xiaochengxinyizhan
* @create 2019-03-06 19:37
**/
public class CustomClassLoader extends ClassLoader {
/**
* Finds the class with the specified <a href="#name">binary name</a>.
* This method should be overridden by class loader implementations that
* follow the delegation model for loading classes, and will be invoked by
* the {@link #loadClass <tt>loadClass</tt>} method after checking the
* parent class loader for the requested class. The default implementation
* throws a <tt>ClassNotFoundException</tt>.
*
* @param name The <a href="#name">binary name</a> of the class
* @return The resulting <tt>Class</tt> object
* @throws ClassNotFoundException If the class could not be found
* @since 1.2
*/
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
try{
byte [] result=getClassFromCustomPath(name);
if (result == null) {
throw new FileNotFoundException();
}else {
return defineClass(name, result, 0, result.length);
}
}catch (Exception e){
e.printStackTrace();
}
throw new ClassNotFoundException(name);
}
private byte[] getClassFromCustomPath(String name){
//从自定义路径中加载指定类
return null;
}
public static void main(String args[]){
CustomClassLoader customClassLoader = new CustomClassLoader();
try{
Class<?> clazz = Class.forName("One", true, customClassLoader);
Object obj = clazz.newInstance();
System.err.println(obj.getClass().getClassLoader());
}catch (Exception e){
e.printStackTrace();
}
}
}
与之相匹配的是-XX:MaxTenuringThreshold参数能配置计数器的值到达某个阀值的时候,对象从新生代晋升至老年代,如果该参数配置为1,那么从新生代的Eden区直接移至老年代。默认值15,可以再survivor区交换14次之后,晋升至老年代。
与之相匹配的可以参考这里的文章
特殊的补充:
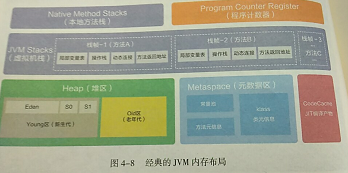
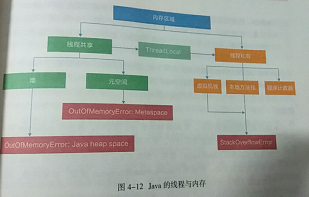
String,字符串常量移至堆内存,其他内容包括类元信息、字段、静态属性、方法、常量等都移动至元空间。常量池中的String实际对象是在堆内存
JVM栈
(1)局部变量表是存放参数和局部变量的区域。相对于类属性变量的准备阶段和初始化阶段来说,局部变量没有准备阶段,必须显示初始化。如果是非静态方法,则在index【0】位置上存储的是方法所属对象的实例引用,随后存储的是参数和局部变量。字节码指令中的STORE指令就是将操作栈中计算完成的局部变量写回局部变量表的存储空间内。
(2)操作栈
操作栈是一个初始状态为空的桶式结构栈。在方法执行过程中,会有各种指令往栈中写入和提取信息。JVM的执行引擎是基于栈的执行引擎,其中的栈指的就是操作栈。字节码指令集的定义都是基于栈类型的,栈的深度在方法元信息的stack属性中。
从字节码看i++和++i的区别;
(3)动态链接
每个栈帧中包含一个在常量池中对当前方法的引用,目的是支持方法调用过程的动态链接。
(4)方法返回地址
方法执行时候有两种退出情况,第一正常退出。正常执行到任何方法的返回字节码指令,如return,ireturn,areturn等。第二异常退出,方法退出的过程相当于弹出当前栈帧。
退出的三种方式:
返回值压入上层调用栈帧,异常信息抛给能够处理的栈帧,PC计数器指向方法调用后的下一条指令。

本地方法栈
本地方法栈是线程私有的,但是虚拟机栈“主内”而本地方法栈“主外”,这个“内外”是针对JVM来说的,本地方法栈为Native方法服务。线程开始调用本地方法时候,会进入一个不再受jvm约束的世界,本地方法可以通过JNI来访问虚拟机运行的数据区,甚至可以调用寄存器,具有和JVM相同的能力和权限,当大量本地方法出现时候,势必会削弱JVM对系统的控制力,因为出错信息比较黑盒不容易找到。内存不足,本地方法栈会抛出native heap OutOfMemory。JNI本地方法,比如System.currentTimeMillis();
程序计数寄存器
每个线程在创建后,都会产生自己的程序计数器和栈帧,程序计数器用来存放执行指令的偏移量和行号指示器等,线程执行或恢复都要依赖程序计数器。程序计数器在各个线程之间互不影响,此区域也不会发生内存溢出异常。
最后,从线程共享的角度来看,堆和元空间是所有线程共享的,而虚拟机栈和本地方法栈、程序计数器都是线程内部私有的
对象实例化
可以利用javap -verbose -p命令查看对象创建的字节码
假设代码为 Object ref =new Object();
stack =2,locals=1,args_size=0;
NEW java/lang/Object
DUP
INVOKESPECIAL java/lang/Object.<init> ()v
ASTORE_1
LocalVariableTable:
Start Length Slot Name Signature
8 1 0 ref Ljava/lang/Object
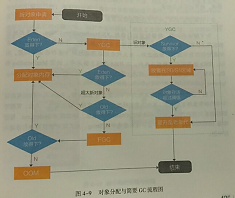
NEW:如果找不到Class对象,则进行类加载。加载成功后,则在堆内存分配内存,从Object开始到本类路径上的所有属性值都要分配内存。分配完毕,进行零值初始化。在分配过程中,注意引用是占据存储空间的,他是一个变量,占用4个字节。这个指令完毕后,将指向实例对象的引用变量压入虚拟机栈顶。
DUP:在栈顶复制该引用变量,这时的栈顶有两个指向堆内实例对象的引用变量。如果方法有参数,还需要把参数压入操作栈中,两个引用变量的目的不同,其中压至底下的引用用于赋值,或者保存到局部变量表,另一个栈顶的引用变量作为句柄调用相关方法。
INVOKESPECIAL:调用对象实例方法,通过栈顶的引用变量调用方法,是类初始化执行的方法而是对象初始化的执行的方法。
从执行步骤的角度来分析:
确认类元信息是否存在。当JVM接收到new指令时候首先在metaspace内检查需要创建的类元信息是否存在,若不存在,在双亲委派模式下,使用当前的类加载器以ClassLoader+包名+类名为key进行查找对应的.class文件。如果没有找到文件,则抛出ClassNotFoundException异常,如果找到则进行类加载,并生成对应地 Class对象。
分配对象内存。首先计算对象占用空间大小,如果实例成员变量是引用变量,仅分配引用变量空间即可,即4个字节大小,接着在堆中划分一块内存给新对象。在分配内存空间时候,需要进行同步操作,比如采用CAS失败重试,区域加锁等方式保证分配操作的原子性。
设定默认值,成员你变量值都需要设定为默认值,即各种不同的零值、
设置对象头,设置新对象的哈希码、GC信息、锁信息、对象所属的类元信息等,这个过程的具体设置方式取决于JVM实现。
执行init方法,初始化成员变量,执行实例化代码块,调用类的构造方法,并把堆内对象的首地址赋值给引用变量。
避免CMS碎片问题,-XX:+UseCMSCompactAtFullCollection
为了减少STW, -XX:+CMSFullGCsBeforeCompaction=n参数设置控制fullgc达到n次以后再执行空间碎片整理。
剩下的可以参考深入理解java虚拟机。
这里强调下zgc
可伸缩的低延迟垃圾收集器,宣称暂停时间不超过10毫秒。zgc会因为gc root的增大而增加暂停时间。与g1一样,区别是zgc中区域大小是不同的,有小型和中型和大型之分。目前只支持Linux系统,当生产环境需要考虑如何支持class unloading,功能性缺失问题。第二compressed ref和zgc是冲突的,开zgc一定不能有compressed ref。第三解决single generation问题。因为应用分配速率过高的话,gc可能跟不上。
5、异常与日志
处理异常
try catch finally throw 抛出具体异常的关键字,throws只是申明抛出的异常
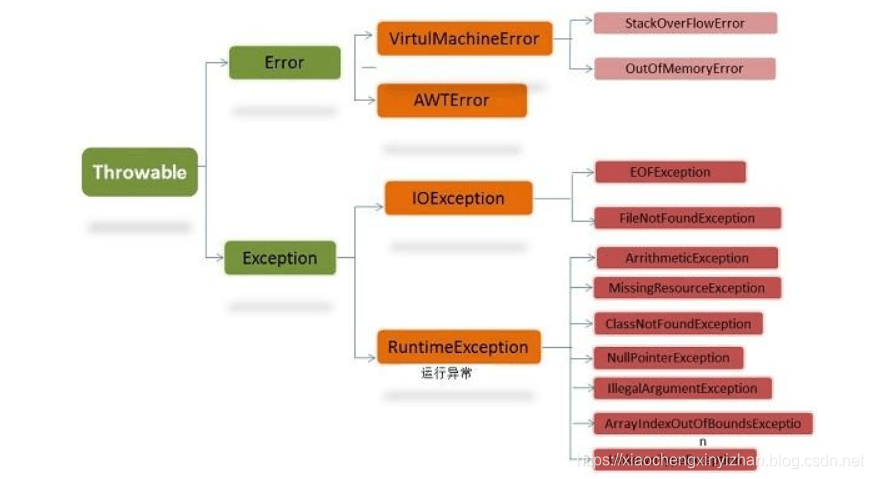
异常分类:
finally强调释放资源而不是返回值
日志:记录操作轨迹,监控系统运行状况,回溯系统故障,比如CPU使用率大于60%,四核服务器中的load大于4等等
日志:可以根据保存周期进行7天或者15天的保存。日志的6种级别。TRACE,DEBUG,INFO,WARN,ERROR,FATAL(严重错误事件)
使用条件判断式以及使用占位符形式
避免无效日志打印,避免重复打印additivity=fasle设置
日志区别开,并保证记录内容完整。----如果输出的是对象,确保重写toString方法。
6、数据结构与集合
数据结构的分类
如果完全不懂数据结构,很难写出优秀的代码,有缺陷的底层数据结构容易导致系统风险高,可扩展性差,所以需要认真的对待数据结构进行设计和评审。
线性结构:
0至1个直接前继和直接后继。当线性结构非空时候,有唯一的首元素和尾元素,除两者外,所有的元素都有唯一的直接前继和直接后继。线性结构包括顺序表,链表,栈表,队列等,其中栈和队列是访问受限的结构。栈是后进先出,LIFO,last-in,first-out,队列是先进先出FIFO.firtst-in,first-out
树结构:
0至1个直接前继和0至n个直接后继(n大于或等于2)。树是一种非常重要的有层次的非线性数据结构,像自然界的树一样,由于树结构比较稳定和均衡,在计算机领域中得到广泛使用。
图结构:
0至n个直接前继和直接后继(n大于或等于2)图结构包括简单图,多重图,有向图,和无向图等
哈希结构:
没有直接前继和直接后继,哈希结构通过某种特定的哈希函数将索引和存储的值关联起来,是一种查找效率非常快的数据结构。
如何选择数据结构取决于空间复杂度和时间复杂度。
集合的初始化,指定集合初始值大小,ArrayList默认10,HashMap默认值16.
数组为什么下标是从0开始而不是1开始,?如果从1开始,计算偏移量需要使用当前下标-1的操作。而加减法运算对CPU是一种双数运算,在数组下标使用频率极高的情况下,这种运算十分耗时。
数组与集合转换,
数组转集合的时候不能进行add和remove等操作,只能set修改。为什么呢?因为返回的arraylist并非是arraylist而是返回了一个InnerArrayList。而这个集合并没有继承抽象父类的那些方法。
集合转数组的时候,数组容量与集合大小相等时候运行最快。类型换需要保持一致。
<? extends T> 是get first,适用于消费集合元素为主的场景。<? super T>是put first 适用于 生产集合元素为主的场景。
元素的比较Comparable和Comparator
前者是自己和自己比。后者是第三方比较器。
TimSort----JDK7中使用取代了原来的归并排序
1、归并排序的分段不再从单个元素开始,而是每次先查找当前最大的排序好的数组片段run,然后对run进行扩展并利用二分排序。之后将该run与其他已经排序好的run进行归并。产生排序好的大run
2、引入二分排序,即binarySort。二分排序是对插入排序的优化,在插入排序中不再是从后向前逐个元素对比,而是引入了二分查找的思想,将一次查找新元素合适位置的时间复杂度由O(n)降低到O(logn)
HashCode和equals,两个方法协同工作可用来判断两个对象是否相等。
如果hashCode相同,则equals不一定相同,但是equals相同,则hashCode肯定相同。
而hashMap中也是利用此特性来进行防止hash碰撞,任何时候重写equals方法都必须同时重写hashCode方法。
NPE问题空指针异常,推荐使用JDK7引入的Objects的equals方法。JDK10引入的变量命名机制,一改Java是强类型语言的传统形象。所以如果用var定义变量尽量不要超过2个。
fail-fast机制
集合的一种错误检查机制,来源于集合中的计数比较器,expectedModCount,当多线程环境下,当前线程会维护该计数器,记录已经修改的次数,执行遍历前,会把实时修改次数modCount赋值给expectedModCount,如果这两个数据不相等,则抛出异常。java.util下的所有集合类都是fail-fast而concurrent包中的集合类都是fail-safe。
COW(copy-on-write)奶牛家族的使用建议:读多写少的场景。
第一尽量设置合理的容量初始值,它扩容的代价比较大;第二使用批量或删除方法。
Map类的特点:
Map类取代了旧的抽象类Dictionary,拥有更好的性能
没有重复的key,可以有多个重复的value
Value可以是List/Map/Set类等任意对象
KV是否允许为null,以实现类约束为准。
三个特有的方法:
返回所有的key-----keySet(),返回所有的Value----values(),返回所有的KV键值对-----entrySet()
7、并发与多线程
8、单元测试
9、代码规约
