版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/walkandthink/article/details/45392519
在上一节的基础上,我们试一下在循环中最常用的求和计算。这里我们计算的算例是一个余弦函数的积分,积分式如下:
∫π20cos(x)dx
它的解析解是1.0,可以很方便地对比我们的计算结果。
我们采取的是在将区间
[a,b]
分割成很小的小段,然后在每个小段
[ai,ai+1]
上用梯形公式
12(ai+1−ai)(cos(ai+1)+cos(ai))
,最后求和就可得到具体的积分值了。最后求积分的公式如下:
∫π20cos(x)dx=∑i=1steps12(xi+1−xi)(cos(xi+1)+cos(xi))
在传统串行方法中实现该计算的代码为:
res=0.d0
do i=1,steps
x=low+(i-1)*dx
res=res+(dcos(x)+dcos(x+dx))*dx/2.d0
enddo在并行中,由于每个线程都需要使用公共的变量res,以及每个线程内部使用x时,x在各个线程中的值应该是独立的,彼此不相干的,不然计算不出现不正确的结果。
这里就需要用到private(x)对x进行私有变量的声明,表明x在每个线程里面具有独立的备份,这样在进行并行计算时,各个线程之间就不会干扰到各自的x的值了。然后,这里因为res进行的累加的操作,我们这里就推荐用OpenMP自带的reduction声明来让其自动优化。reduction的声明如下:
reduction(operator:variables)其中variables是变量名,而operator是操作符,OpenMP提供了“+,-,*,/…”等基本的操作运算,这里,我们只需要累加的操作,所以操作符取为’+’就可以了,这里我们采用reduction(+:res)
具体代码如下:
res=0.d0
call SYSTEM_CLOCK(start)
!$OMP PARALLEL private(x) shared(dx)
!$OMP DO reduction(+:res)
do i=1,steps
x=low+(i-1)*dx
res=res+(dcos(x)+dcos(x+dx))*dx/2.d0
enddo
!$OMP END DO
!$OMP END PARALLEL
call SYSTEM_CLOCK(finish)其中call SYSTEM_CLOCK(int variables)函数返回的是微妙,1微妙=
1106
秒
全部的代码如下:
Program Ch2
!reduction,private的使用
!$ use omp_lib
implicit none
real(8)::low,up,pi
integer(8)::steps,i
real(8)::dx,x,res
integer(8)::start,finish
write(*,*) "线程数为:",omp_get_num_procs()
write(*,*) "请输入积分的段数:"
read(*,*) steps
write(*,*) "请输入积分的区间:"
read(*,*) low,up
pi=4.d0*datan(1.d0)
up=up*pi
dx=(up-low)/steps
call SYSTEM_CLOCK(start)
res=0.d0
do i=1,steps
x=low+(i-1)*dx
res=res+(dcos(x)+dcos(x+dx))*dx/2.d0
enddo
call SYSTEM_CLOCK(finish)
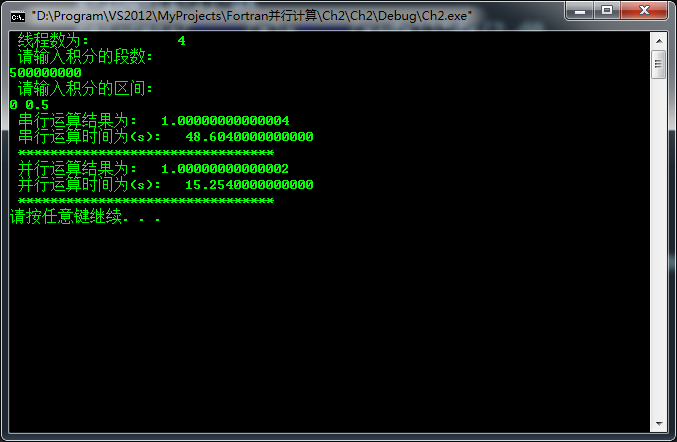
write(*,*) "串行运算结果为:",res
write(*,*) "串行运算时间为(s):",(finish-start)/1000000.d0
write(*,*) "********************************"
res=0.d0
call SYSTEM_CLOCK(start)
!$OMP PARALLEL private(x) shared(dx)
!$OMP DO reduction(+:res)
do i=1,steps
x=low+(i-1)*dx
res=res+(dcos(x)+dcos(x+dx))*dx/2.d0
enddo
!$OMP END DO
!$OMP END PARALLEL
call SYSTEM_CLOCK(finish)
write(*,*) "并行运算结果为:",res
write(*,*) "并行运算时间为(s):",(finish-start)/1000000.d0
write(*,*) "********************************"
stop
end