目录
在基于K-均值的app列表聚类分析中,初步完成用户app列表特征聚类。我们在评估中发现以下几个问题:
- 某些同类用户app列表出现大量相同的国民app(如支付宝、微信、QQ、腾讯视频等)和系统app(如日志和备份、相机等);
- 部分app属性对应有app类别,这部分信息没有利用起来;
针对以上问题,主要做了一下优化:
- 统计app名称词表,挑选top N作为过滤词表;
- 统计具有app类别占比,如果占比较高(60%以上),则将app名称和app类别均提取为稀疏向量,作为K-均值模型特征,否则还是以app名称作为输入特征;
一、过滤词表筛选
hive(odps/spark) sql统计app名称词表
SELECT t2.app_name
,t2.cnt
,t2.updated_client
FROM (
SELECT app_name
,COUNT(1) cnt
,t1.updated_client
FROM (
SELECT app_list_json
,updated_client
FROM user_app_list_all_parsed
WHERE dt = '${dt}'
) t1
LATERAL VIEW EXPLODE(SPLIT(t1.app_list_json, ';')) appTable AS app_name
GROUP BY app_name
,t1.updated_client
) t2
ORDER BY t2.cnt DESC
LIMIT 100
;筛选出app词表如下
| app名称 | count | system |
| alipays | 13370011 | ios |
| alipayshare | 13369783 | ios |
| 天气 | 12284068 | android |
| 微信 | 11062865 | android |
| 10659983 | android | |
| Pico TTS | 10636702 | android |
| 手机淘宝 | 10627003 | android |
| 支付宝 | 10596229 | android |
| 网络位置 | 10516984 | android |
| 指南针 | 10187484 | android |
| 相册 | 9516585 | android |
| tenvideo | 9307299 | ios |
| 腾讯视频 | 9204797 | android |
| 爱奇艺 | 9039991 | android |
| 抖音短视频 | 8957105 | android |
| 云服务 | 8838426 | android |
| ... | ... | ... |
二、模型更新
为了避免国民app和系统app导致用户趋于大同,需要对样本进行过滤处理,如下
import spark.implicits._
// 加载textFile
val df = spark.read.textFile(Constants.SAMPLE).map(row=>{
val rows = row.split(",")
AppList(rows(0).toLong,rows(1).split(";").filter(!Constants.APP_FILTER_VOCABULARY.split(",").contains(_)))
}).toDF("uid","app_list").repartition(numPartitions)其他过程保持不变。
重新迭代模型,得到ssd随k均值变化趋势,如下
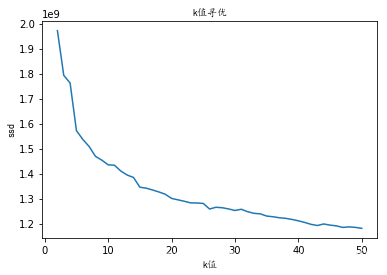
采用手肘法,选取最佳k=26。
三、app类型处理
1. 统计app类型占比
同样采用hive(odps/spark) sql统计app类型占比
SELECT COUNT(1) cnt
,COUNT(DISTINCT t3.app_name) cdnt
FROM (
SELECT t1.app_name
,t2.app_name app_name1
,t1.app_category
FROM (
SELECT *
FROM dw_user_app_list_android
WHERE dt = '${dt}'
) t1
LEFT OUTER JOIN (
SELECT *
FROM app_vocabulary
WHERE dt = '${dt}'
AND updated_client = 3
) t2
ON t1.app_name = t2.app_name
) t3
WHERE t3.app_name1 IS NOT NULL;发现,具有app类型占比仅有1/6,大量数据缺失,不太适合作为聚类特征。
2. 新增app类型特征
假如具有app类型占比在60%以上,可以新增app类型特征处理。如下
// app_list和app_category_list列转化为稀疏特征向量
val vectorizerWords = Array("app_list","app_category_list")
var flag = false
val cvm = if(!fs.exists(new Path(Constants.COUNTVECTOR))){
flag = true
val vectorizers = vectorizerWords.map(col=>{
new CountVectorizer().setInputCol(col).setOutputCol(col + "_cv").setMinDF(1).fit(df)
})
val cvms = new Pipeline().setStages(vectorizers)
cvms.fit(df)
}else{
CountVectorizerModel.load(Constants.COUNTVECTOR)
}
if(flag){
cvm.write.overwrite().save(Constants.COUNTVECTOR)
}
val result = cvm.transform(df).select("uid","app_list_cv","app_category_cv")
result.cache()
println("countVectorizer处理后分区数量:" + result.rdd.getNumPartitions)
result.show(10,false)
// result在Kmeans迭代寻优多次用到,因此加载内存
val map = new util.HashMap[Int,Double]()
// k-means聚类
val ks = Range(minSeq, maxSeq)
var minSsd = 0.0
ks.foreach(cluster => {
val ks = vectorizerWords.map(col=>{
new KMeans()
.setK(cluster)
.setMaxIter(maxIter)
.setFeaturesCol(col)
.setPredictionCol(col + "_cv")
})
val kmeans = new Pipeline().setStages(ks)
val kmm = kmeans.fit(result)参考资料