工作中,我们时常会遇到一些操作文件的操作,比如在线生成合同模板,上传/下载/解析Excel,doc文档转为pdf等操作。本文就已工作中遇到的在线生成合同为例,简要地介绍一种文档替换写法。
本文目的:给出源文件模板,通过程序操作后,替换模板中的指定内容,从而生成固定模板的文件。
使用场景:生成固定格式的合同信息。
原理:给一个文档模板,需要替换的内容以 $$包含,然后,在代码中给需要替换的字段赋值,生成新的文档。
工具包:poi-ooxml-3.10.jar 自己网上下载
代码:
1 package word2pdf; 2 3 import java.io.FileOutputStream; 4 import java.util.HashMap; 5 import java.util.Iterator; 6 import java.util.List; 7 import java.util.Map; 8 import java.util.Map.Entry; 9 import java.util.Set; 10 11 import org.apache.poi.POIXMLDocument; 12 import org.apache.poi.xwpf.usermodel.XWPFDocument; 13 import org.apache.poi.xwpf.usermodel.XWPFParagraph; 14 import org.apache.poi.xwpf.usermodel.XWPFRun; 15 import org.apache.poi.xwpf.usermodel.XWPFTable; 16 import org.apache.poi.xwpf.usermodel.XWPFTableCell; 17 import org.apache.poi.xwpf.usermodel.XWPFTableRow; 18 19 public class DocWriterTest { 20 21 public static void searchAndReplace(String srcPath, String destPath, Map<String, String> map) { 22 try { 23 XWPFDocument document = new XWPFDocument(POIXMLDocument.openPackage(srcPath)); 24 /** 25 * 替换段落中的指定文字 26 */ 27 Iterator<XWPFParagraph> itPara = document.getParagraphsIterator(); 28 while (itPara.hasNext()) { 29 XWPFParagraph paragraph = (XWPFParagraph) itPara.next(); 30 Set<String> set = map.keySet(); 31 Iterator<String> iterator = set.iterator(); 32 while (iterator.hasNext()) { 33 String key = iterator.next().trim(); 34 List<XWPFRun> run = paragraph.getRuns(); 35 int runSize = run.size(); 36 for (int i = 0; i < runSize; i++) { 37 String text = run.get(i).getText(0); 38 System.out.println("++++++text++++++:" + text); 39 for (Entry<String, String> e : map.entrySet()) { 40 if (text != null && text.contains(e.getKey())) { 41 text = text.replace(e.getKey(), e.getValue()); 42 System.out.println("++++++text222222222++++++:" + text); 43 run.get(i).setText(text, 0); 44 } 45 } 46 } 47 } 48 } 49 50 /** 51 * 替换表格中的指定文字 52 */ 53 Iterator<XWPFTable> itTable = document.getTablesIterator(); 54 while (itTable.hasNext()) { 55 XWPFTable table = (XWPFTable) itTable.next(); 56 int count = table.getNumberOfRows(); 57 for (int i = 0; i < count; i++) { 58 XWPFTableRow row = table.getRow(i); 59 List<XWPFTableCell> cells = row.getTableCells(); 60 for (XWPFTableCell cell : cells) { 61 for (XWPFParagraph p : cell.getParagraphs()) { 62 for (XWPFRun r : p.getRuns()) { 63 String text = r.getText(0); 64 for (Entry<String, String> e : map.entrySet()) { 65 if (text != null && text.contains(e.getKey())) { 66 text = text.replace(e.getKey(), e.getValue()); 67 r.setText(text, 0); 68 } 69 } 70 } 71 } 72 73 } 74 } 75 } 76 FileOutputStream outStream = null; 77 outStream = new FileOutputStream(destPath); 78 document.write(outStream); 79 outStream.close(); 80 } catch (Exception e) { 81 e.printStackTrace(); 82 } 83 84 } 85 86 public static void main(String[] args) throws Exception { 87 Map<String, String> map = new HashMap<String, String>(); 88 map.put("$name$", "coco"); 89 map.put("$sex$", "女"); 90 map.put("work", "Java开发"); 91 String srcPath = "E:\\cocoxu\\test_mode\\sourcefile.docx"; 92 String destPath = "E:\\cocoxu\\test_mode\\destfile.docx"; 93 searchAndReplace(srcPath, destPath, map); 94 } 95 }
调试时遇到的报错:
1.
java.lang.IllegalStateException: Zip File is closed
at org.apache.poi.openxml4j.util.ZipFileZipEntrySource.getEntries(ZipFileZipEntrySource.java:45)
at org.apache.poi.openxml4j.opc.ZipPackage.getPartsImpl(ZipPackage.java:182)
at org.apache.poi.openxml4j.opc.OPCPackage.getParts(OPCPackage.java:665)
at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:226)
at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:186)
at org.apache.poi.POIXMLDocument.openPackage(POIXMLDocument.java:67)
at word2pdf.DocWriterTest.searchAndReplace(DocWriterTest.java:23)
at word2pdf.DocWriterTest.main(DocWriterTest.java:93)
此类错看似是zip文件被关闭,其实不然。其实是由于文档路径写错,找不到文件导致的。

String srcPath = "E:\\cocoxu\\\test_mode\\sourcefile.docx";
2、没有生产想要的文件:
sourcefile.docx内容:
目的是用代码中的内容,替换文档中的内容,但是我们第一次得到的确实这样的: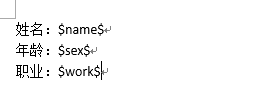
在代码中打印日志,可以看到,word文档中的$name$被跨行分开了:
本来是一行的东西,为什么代码执行操作的时候会被分成三行呢?这个就是doc文档操作的问题啦 ,
方法一:操作源文档,对文档中所有拼写语法不合规范的都忽略
方法二:创建一个新文档,在纯英文格式下拼写字段,然后复制带源文件中,即可。
最终得到的目的问题内容:

至此,我们用java操作文档的案例就结束了,实际工作中也可以模仿此类代码去生成哦。