也是初次学习,以后还会继续增补
推荐系统是一种在电商、广告、内容等互联网平台发挥着巨大价值的数据挖掘产品形态。它可以提高用户粘性、提高用户商业转化行为,一款好的推荐系统乐意明显有效的提升平台的经济效益。
协同过滤算法:
协同过滤算法是一款经典的推荐算法,也是推荐系统入门最好的机器学习算法。协同过滤算法主要可以分为两类:基于用户相似性的UserCF算法以及基于物品相似性的ItemC算法。这两类算法的基本思想是:
(1)如果user1和user2的相似度高,那么user1买了一款物品item,就可以把这款物品推荐给user2,这是UserCF的基本思想。
(2)如果item1与item2相似度高,用户user买了item1,就可以推荐他再买item2.这也是ItemCF的基本思想。
知乎内容的根基在于它由一棵几万个甚至更多的话题组成的有向无环图的话题网络,每一个问题都可以映射到几个话题标签上。如果单标签的角度入手,考虑基于这些标签内在的层级联系,根据标签的相似度来计算标签组的相似度以此来衡量问题间的相似度,这样的实现过于复杂。而协同过滤算法的强大之处在于:不用考虑问题间的层级联系(内在联系),只要基于大量用户的行为数据,就可以衡量这些问题在大量用户中被倾向的相似度。
何为协同过滤:百度百科上解释为——利用兴趣相投、拥有共同经验的群体的喜好 来推荐用户感兴趣的信息。通过合作的机制给予信息相当程度的回应,并记录下来已达到过滤的目的进而帮助他人筛选信息。
通过百度百科上面的释义,我们不难理解协同过滤算法为什么不需要考虑问题之间的层级联系,用为大量的用户行为数据中就隐藏着对信息规律的倾向性,我们只要充分分析用户的数据行为,就可以过滤出相似度较高的某一类用户或某一类数据。
ItemCF算法计算过程
以”用户关注“为例(因为知乎中用户的行为唯度较多,比如提问、收藏等等)
(1)计算问题之间的相似度
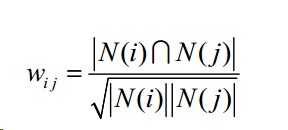 问题i与问题j之间的相似度定义:同时关注问题i与关注问题j的人数/关注问题i人数关注问题j人数的平方根。
问题i与问题j之间的相似度定义:同时关注问题i与关注问题j的人数/关注问题i人数关注问题j人数的平方根。
所以我们计算n个问题两两之间的相似度就可以转化为一个对角线为0的对称邻接矩阵,最少需要计算n(n-1)/2次