转载地址:https://blog.csdn.net/qq_28882043/article/details/80885240
算法的主要函数调用关系如下:
1、初始化模块
//设置特征提取参数
set_feature_extraction_parameters()
//特征参数提取
FeatureParameterExtraction()
//初始化状态
WebRtcNs_InitCore()
//改变噪声抑制方法的激增性
WebRtcNs_set_policy_core()
2、分析模块
//噪声抑制分析模块
WebRtcNs_AnalyzeCore()
//更新数据缓冲
UpdateBuffer()
//计算缓冲区的能量
Energy()
//窗缓冲区
Windowing()
//将信号从时域变换到频域
FFT()
//噪声估计
NoiseEstimation()
//计算信噪比
ComputeSnr()
//特征值更新(主要是谱差和平坦度)
FeatureUpdate()
//计算谱平坦度
ComputeSpectralFlatness()
//计算谱差异
ComputeSpectralDifference()
//计算语音/噪声概率
SpeechNoiseProb()
//更新噪声估计
UpdateNoiseEstimate()
//计算缓冲区的能量
Energy()
//窗缓冲区
Windowing()
3、处理模块
//噪声抑制处理模块
WebRtcNs_ProcessCore()
//更新数据缓冲
UpdateBuffer()
//计算缓冲区的能量
Energy()
/ /窗缓冲区
Windowing()
//将信号从时域变换到频域
FFT()
//估计先验信噪比判决定向和计算基于DD的维纳滤波器
ComputeDdBasedWienerFilter()
//将信号从频率变换到时域
IFFT()
//窗缓冲区
Windowing()
//更新数据缓冲
UpdateBuffer()
算法的核心思想是采用谱减法计算噪声估计和运用维纳滤波器抑制估计出来的噪声。谱减法是最常用的一种噪声抑制方法,它基于一个简单的原理:假设噪声为加性噪声,通过从带噪语音谱中减去对噪声谱的估计,就可以得到纯净的信号谱。在不存在语音信号的期间,可以对噪声谱进行估计和更新。做出这一假设是基于噪声的平稳性,或者是一种慢变的过程,这样噪声的频谱在每次更新之间不会有大的改变。增强信号通过计算估计信号谱的逆离散傅里叶变换得到,其相位仍然使用带噪信号的相位。在计算上这种算法比较简单,因为其只包含一次傅里叶变换和反变换。

1、WebrtcAnalyzeCore模块
在噪声抑制模块WebrtcAnalyzeCore中,输入信号经过时频变换后分成三路信号,分别对这三路信号进行计算频谱平坦度、计算信噪比、计算频谱差异。最后将这三个相应的特征值输入到语音/噪声概率更新模板中。该模块具体的流程图以及功能介绍如下:
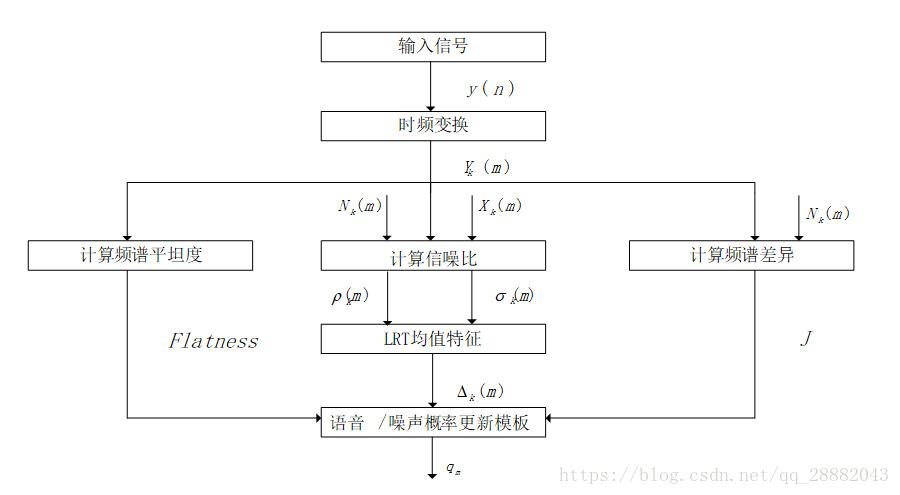
输入信号:指在输入信号中从麦克风采集到的信号,其表达式为

时频变换:将输入信号进行时频变换,线性模型在语音状态下的表达式是

计算频谱平坦度:语音频往往会在基频和谐波中出现峰值,用于区分语音和噪声。其计算公式是
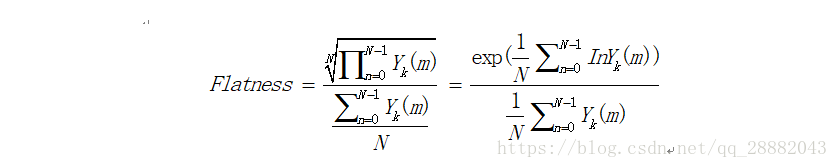
其中N表示STFT后频率点数,每个频带包括大量的频率点。
计算信噪比:根据分位数噪声估计计算先后信噪比。先验信噪比是与噪声功率相关的纯净信号功率的期望值,其计算公式为
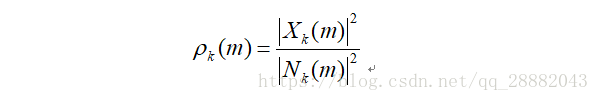
而后验信噪比是指观测到的能量与噪声功率相关的输入功率相比的瞬态信噪比,其表达式是
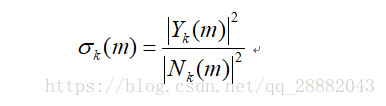
计算频谱偏差:用于测量输入频谱与噪声频谱的偏差。其公式为
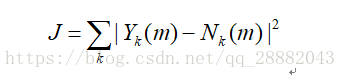
LRT均值特征:经过时间处理的LR因子的计算公式如下:
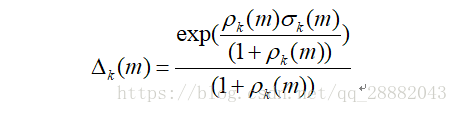
经过时间平滑处理的似然比(LR)因子的几何平均数是语音/噪声状态的可靠指标:
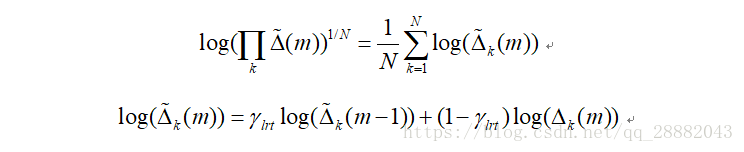

语音/噪声概率更新模板:在语音/噪声概率计算时,使用高斯假设作为语音PDF模型,从而获得似然比。在其它模型中,概率密度PDF模型也可以用作测量似然比的基础,包括拉普拉斯算子,伽马,超高斯。举个例子,当高斯假设可合理表示噪声时,该假设并不一定适用于语音,尤其是在较短的时帧中(如~10ms)。在这种情况下,可以使用另一种语音PDF模型,但这很可能会增加复杂性。


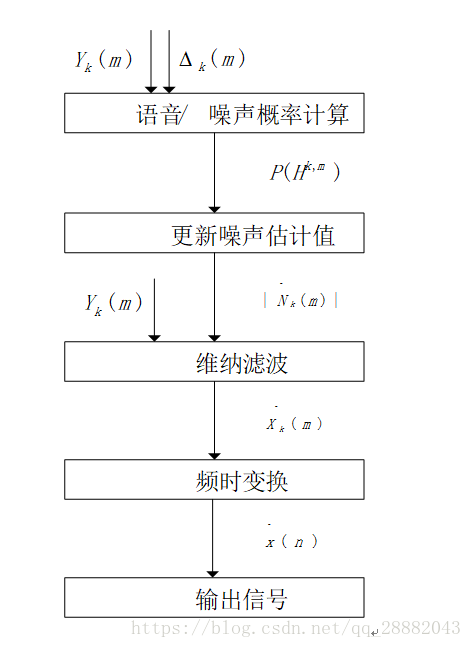
2、WebrtcProcesCore模块
在噪声抑制模块WebrtcProcesCore中,技术方案是采用维纳滤波抑制估计出来的噪声。其抑制过程为根据计算出的先后信噪比计算出语音/噪声的概率,根据计算出的语音概率,更新每帧中的初始噪声估计。将计算出的噪声估计进行维纳滤波得到估计的语音信号,再进行频时变换即输出信号为所求信号。该模块具体的流程图以及功能介绍如下: