版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/87956052
1 Spark SQL作为计算引擎去操作hive的注意事项
- 要配置
hive.metastore.uris,
启动 metastore 服务
1. hive --service metastore -p 9083 &
2. hive --service metastore
3. hive --service metastore &
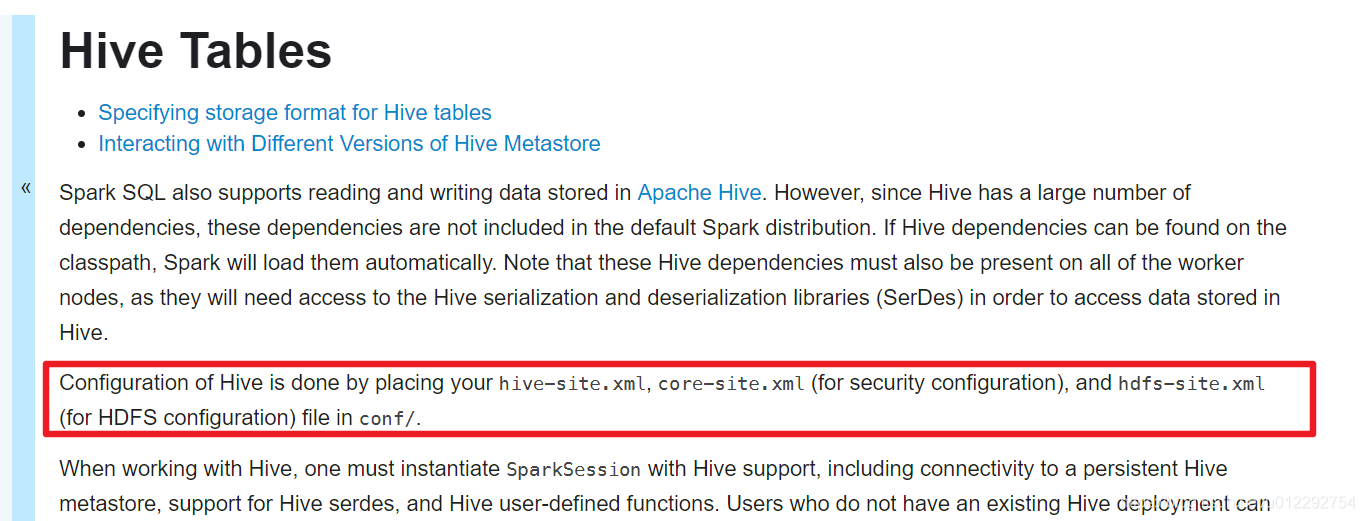
- hive-site.xml,core-site.xml,hdfs-site.xml 放入到Spark的conf目录
http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
1.1 hive-site.xml
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
1.2 参考文章
https://www.jianshu.com/p/ad9aac1aef76
https://blog.csdn.net/qq_35440040/article/details/82462269
https://blog.csdn.net/slq1023/article/details/50991796