前言:相信不管在生产过程中还是面试过程中,HashMap出现的几率都非常的大,因此有必要对其源码进行分析,但要注意的是jdk1.8对HashMap进行了大量的优化,因此笔者会根据不同版本对HashMap进行分析,首先我们来看jdk1.7中HashMap的原理。
注:jdk版本:jdk1.7.0_80
1.从demo入手
1 public class HashMapTest { 2 3 public static void main(String[] args) { 4 5 String key_Aa = "Aa"; 6 String key_BB = "BB"; 7 8 // 注意这里的hashCode值 9 System.out.println("key_Aa hashCode=" + key_Aa.hashCode()); 10 System.out.println("key_BB hashCode=" + key_BB.hashCode()); 11 12 Map<String, String> hashMap = new HashMap<String, String>(); 13 14 hashMap.put(key_Aa,"Aa"); 15 hashMap.put(key_Aa,"Aa"); 16 // hashMap.put(key_BB,"Aa"); 17 System.out.println(hashMap); 18 } 19 }
先直接看运行结果:
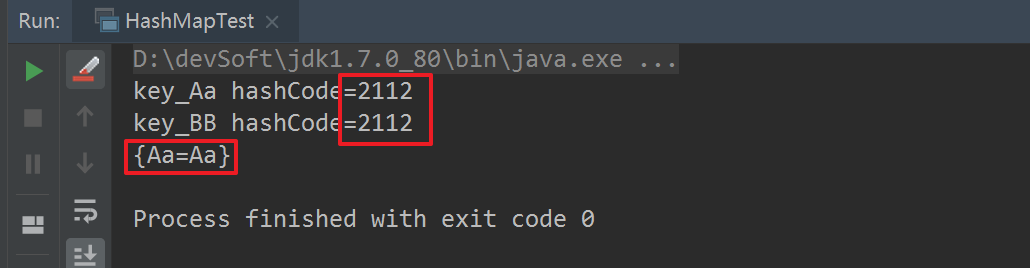
然后打开16行代码的注释,再次运行:
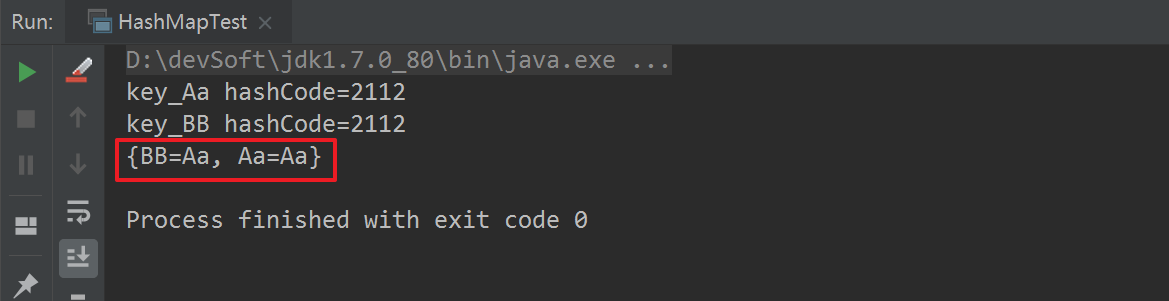
通过以上两组运行结果,我们可以得出如下结论:
#1.不同内容的字符串,其hashCode值可能是相等的。
#2.HashMap在进行put操作时,key相同时(注:hashCode和内容都是一样的),进行了覆盖;key不同时(注:【hashCode不同】或【hashCode相同,内容不同】)进行了插入(直接插入table上,或进行链表式插入数据)操作。
#3.对于HashMap来说,重要的是key,而不是value,value相当于key的一个附属值。
有了以上结论,接下来我们对其源码进行分析就比较有针对性了。

2.源码分析
2.1 put操作
1 public V put(K key, V value) { 2 // 如果table为空,则初始化 3 if (table == EMPTY_TABLE) { 4 inflateTable(threshold); 5 } 6 if (key == null) // 从这里可看出HashMap是可以插入null值的,key,value都可以为null 7 return putForNullKey(value); 8 int hash = hash(key); // 对key进行hash操作 9 int i = indexFor(hash, table.length); // 找出key的hash值在table中对应的位置 10 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 11 Object k; 12 // 如果该位置上元素的hash值与插入元素的hash值相等,并且key也相等或者内容相等,这里就进行覆盖操作 这里与demo中结论相吻合 13 // 注意这里的写法,比较巧妙 14 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 15 V oldValue = e.value; 16 e.value = value; 17 e.recordAccess(this); 18 return oldValue; 19 } 20 } 21 22 // 插入新元素,并且modCount++,modCount表示HashMap修改的次数 23 modCount++; 24 addEntry(hash, key, value, i); 25 return null; 26 }
分析:
#1.HashMap的元素是存储在table中,table的类型为Entry数组,先了解下Entry结构:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; // 存储下一个元素的值,这不就是一个链表吗,因此HashMap的底层数组结构为数组+链表的形式 int hash; /** * Creates new entry. */ // 从Entry的构造函数可以得出结论,在创建一个new Entry的时候,会将old Entry(在table位置上的元素)放在new Entry的next位置,形成链表。从其构造形式可以得出结论:在插入元素时采用的是头插入,新元素都是放在链表头(table上)的,将原来的头元素放在新元素的next位置,形成一个新的链表 Entry(int h, K k, V v, Entry<K,V> n) { value = v;// 当前新元素value next = n; // next表示原来的old Entry key = k; // 当前新元素key hash = h; } ....... ....... ....... }
要点:头插法
#2.inflateTable方法,初始化table。
1 private void inflateTable(int toSize) { 2 // Find a power of 2 >= toSize 3 /** 4 * HashMap的容量都是2的n次方的,这里表示计算出比传入参数最小的2的n次方的值 5 */ 6 /** 7 * HashMap的默认容量: 8 * The default initial capacity - MUST be a power of two. 9 * static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 10 */ 11 int capacity = roundUpToPowerOf2(toSize); 12 13 /** 14 * 扩容阈值,通过HashMap容量与扩容因子计算出来 15 * 默认扩容因子为0.75 16 * The load factor used when none specified in constructor. 17 * static final float DEFAULT_LOAD_FACTOR = 0.75f; 18 */ 19 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); 20 table = new Entry[capacity]; 21 // 该函数主要在扩容中使用,判断是否需要重新计算hash值 22 initHashSeedAsNeeded(capacity); 23 }
#3.从put函数可以看出HashMap是可以存储key为null的元素的,由于value为key的附属值,所以value也可以为null。
1 private V putForNullKey(V value) { 2 // 循环找出key=null的元素,然后将其值覆盖,从这里可以看出HashMap中key=null时,是不会形成链表的 3 for (Entry<K,V> e = table[0]; e != null; e = e.next) { 4 if (e.key == null) { 5 V oldValue = e.value; 6 e.value = value; 7 e.recordAccess(this); 8 return oldValue; 9 } 10 } 11 // 如果没有key为null的元素,则增加一个元素 12 modCount++; 13 addEntry(0, null, value, 0); 14 return null; 15 }
#4.在putForNullKey中出现了addEntry函数,因此这里对其进行分析。
1 /** 2 * HashMap增加元素 3 * 4 * @param hash key的hash值 5 * @param key key值 6 * @param value value值 7 * @param bucketIndex 插入元素在table中的位置 8 */ 9 void addEntry(int hash, K key, V value, int bucketIndex) { 10 // 如果当前HashMap的容量大于扩容阈值并且当前插入元素的位置在table上对应的值不为null 11 // 注意这里的table[bucketIndex]非常重要,如果当前位置上为空,是不需要扩容的 12 if ((size >= threshold) && (null != table[bucketIndex])) { 13 // 扩容,将新容量扩容为原来的2倍 14 resize(2 * table.length); 15 // 再次计算key的hash值,然后找出元素在新table中对应的位置 16 hash = (null != key) ? hash(key) : 0; 17 bucketIndex = indexFor(hash, table.length); 18 } 19 // 创建新元素 20 createEntry(hash, key, value, bucketIndex); 21 }
重点:在判断是否需要扩容时,需要判断当前位置在table上的元素是否为null,只有不为null才进行扩容。
#5.resize函数,这里先不忙分析,先看createEntry函数。
1 /** 2 * 创建元素 3 * 4 * @param hash key的hash值 5 * @param key key值 6 * @param value value值 7 * @param bucketIndex 插入元素在table中的位置 8 */ 9 void createEntry(int hash, K key, V value, int bucketIndex) { 10 // 取出要插入位置上的元素,可能为null,也可能有具体元素 11 Entry<K, V> e = table[bucketIndex]; 12 // 在插入位置上直接创建新元素,注意这里传入的参数e,在Entry构造函数中会放在next中,从而形成链表,从这里也可以看出在出现hash碰撞的时候,HashMap在插入元素的时候,采用的是头插法 13 table[bucketIndex] = new Entry<>(hash, key, value, e); 14 // size++,表示容量增加1个 15 size++; 16 }
重点:插入元素时采用的头插法。因为采用头插法,所以在hash碰撞的时候,才会出现demo中的结果,注意理解,这里交相呼应。
#6.在put方法中有两个方法值得我们注意hash(Object k)和indexFor(int h, int length)。
1 final int hash(Object k) { 2 int h = hashSeed; 3 // 如果使用了再次hash,并且key的类型为String,则直接使用String的hash算法返回其hash值 4 if (0 != h && k instanceof String) { 5 return sun.misc.Hashing.stringHash32((String) k); 6 } 7 // 如果走到这里h可能为0或者为1,再次异或上k的hashCode,如果h为1,表示再hash,则这里的h可能会±1,h为0的时候,h就表示k的hashCode 8 h ^= k.hashCode(); 9 10 // This function ensures that hashCodes that differ only by 11 // constant multiples at each bit position have a bounded 12 // number of collisions (approximately 8 at default load factor). 13 // 这里进行两次hash主要是为了最大可能的解决hash碰撞,防止低位不变,而高位变化时,产生hash碰撞 14 h ^= (h >>> 20) ^ (h >>> 12); 15 return h ^ (h >>> 7) ^ (h >>> 4); 16 } 17
这里为什么要进行了两次hash,通过如下计算过程可以大致了解一下:
假设目前hashMap的容量为16
-------------------------------------------------------------------
h_1: 0101 1000 1101 0111 0011 1110 1001 1011
h_1>>>20: 0000 0000 0000 0000 0000 0101 1000 1101
h_1>>>12: 0000 0000 0000 0101 1000 1101 0111 0011
h_1>>>20^h_1>>>12: 0000 0000 0000 0101 1000 1000 1111 1110
h_1: 0101 1000 1101 0111 0011 1110 1001 1011
h_1^h_1>>>20^h_1>>>12: 0101 1000 1101 0010 1011 0110 0100 0101
h_1>>>7: 0000 0000 1011 0001 1010 0101 0110 1100
h_1>>>4: 0000 0101 1000 1101 0010 1011 0110 0100
h_1^h_1>>>7: 0101 1000 0110 0011 0001 0011 0010 1001
h_1^h_1>>>7^h_1>>>4 0101 1101 1110 1110 0011 1000 0100 1101
&table.length-1: 0000 0000 0000 0000 0000 0000 0000 1111
result: 0000 0000 0000 0000 0000 0000 0000 1101=13
---------------------------------------------------------------------
h_2: 0101 1000 1101 1111 0011 1110 1001 1011
h_2>>>20: 0000 0000 0000 0000 0000 0101 1000 1101
h_2>>>12: 0000 0000 0000 0101 1000 1101 1111 0011
h_2>>>20^h_2>>>12: 0000 0000 0000 0101 1000 1000 1111 1110
h_2: 0101 1000 1101 1111 0011 1110 1001 1011
h_2^h_2>>>20^h_2>>>12: 0101 1000 1101 1010 1011 0110 0110 0101
h_2>>>7: 0000 0000 1011 0001 1011 0101 0110 1100
h_2>>>4: 0000 0101 1000 1101 1010 1011 0110 0110
h_2^h_2>>>7: 0101 1000 0110 1011 0000 0011 0000 1001
h_2^h_2>>>7^h_2>>>4 0101 1101 1110 0110 1010 1000 0110 1111
&table.length-1: 0000 0000 0000 0000 0000 0000 0000 1111
result: 0000 0000 0000 0000 0000 0000 0000 1111=15
分析:
注意上述计算过程中h_1和h_2只有高位中有一位不同,其余全都相同。
如果不采用二次hash这种方式,而是直接和table.length-1进行与操作,得到的结果都是11,造成hash碰撞;采用二次hash的方式,将高位加入运算,对key的hashCode进行了扰动计算,防止低位不变,而高位变化时造成hash碰撞,从而尽可能的减少hash碰撞。
再看indexFor函数:
1 static int indexFor(int h, int length) { 2 // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; 3 // 这里采用位运算来进行操作,求出元素在table中的位置,相当于mod运算,但是位运算效率更高 4 // 从这里可以了解到为什么HashMap的容量必须为2的n次方,因为2的n次方-1的二进制永远全部是1,这样会减少hash碰撞 5 /** 6 * h & (table.length-1) hash table.length-1 7 * 8 * 8 & (15-1): 0100 & 1110 = 0100 9 * 10 * 9 & (15-1): 0101 & 1110 = 0100 11 * 12 * ---------------------------------------------------------------------------------- 13 * 14 * 8 & (16-1): 0100 & 1111 = 0100 15 * 16 * 9 & (16-1): 0101 & 1111 = 0101 17 */ 18 return h & (length-1); 19 }
重点:从这里反推出:为什么HashMap的容量为什么会是2的n次方,因为这样可以尽量减少hash碰撞。
#7.接下来进入HashMap的扩容函数resize(int newCapacity):
1 void resize(int newCapacity) { 2 Entry[] oldTable = table; 3 int oldCapacity = oldTable.length; 4 // 判断是否允许扩容 5 if (oldCapacity == MAXIMUM_CAPACITY) { 6 threshold = Integer.MAX_VALUE; 7 return; 8 } 9 10 // 创建一个新的Entry数组,容量为原来的2倍 11 Entry[] newTable = new Entry[newCapacity]; 12 // 扩容主要函数transfer 13 transfer(newTable, initHashSeedAsNeeded(newCapacity)); 14 table = newTable; 15 // 更新扩容阈值 16 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); 17 }
注意:HashMap扩容后容量变为原来的2倍,在resize中的核心函数就是transfer:
1 /** 2 * 扩容核心函数 3 * 4 * @param newTable 新的Entry数组 5 * @param rehash 是否需要再次hash 6 */ 7 void transfer(Entry[] newTable, boolean rehash) { 8 int newCapacity = newTable.length; 9 // 循环原table 10 for (Entry<K, V> e : table) { 11 // 当元素为null时,循环结束 12 while (null != e) { 13 // 存储当前元素的next,因为可能存在链表结构,所以必须存储next元素 14 Entry<K, V> next = e.next; 15 // 判定是否需要再次对key进行hash操作 16 if (rehash) { 17 e.hash = null == e.key ? 0 : hash(e.key); 18 } 19 // 得到元素在newTable中的位置 20 int i = indexFor(e.hash, newCapacity); 21 /* 22 * #1.将newTabe[i]位置上的元素放入e的next位置 23 * #2.将e放入newTable[i]位置 24 * #3.将next元素赋值给e,继续进行循环 25 * 注意:这里会将原链表(如果存在)进行反序 26 * 原:3->7->5 27 * 第一次循环:newTable[i]=3,其next=null 28 * 第二次循环:newTable[i]=7,其next=newTable[i]=3(上一次的) 29 * 第三次循环:newTable[i]=5,其next=newTable[i]=7,next.next=3 30 * 最终结果:5->7->3,进行了反序 31 */ 32 e.next = newTable[i]; 33 newTable[i] = e; 34 e = next; 35 } 36 } 37 }
注意:transfer函数为扩容的核心函数,并且会将原table上的链表(如果存在)进行反序,这里也是HashMap在多线程中线程不安全的体现,具体线程不安全体现分析传送门:HashMap线程不安全的体现
至此HashMap的put源码已经分析完毕,下面继续分析HashMap中的其他源码。
2.2 get操作
1 public V get(Object key) { 2 // 如果key=null,则通过getForNullKey函数返回值,这里也侧面反映出HashMap的key可以为null的 3 if (key == null) 4 return getForNullKey(); 5 // 通过key取得具体的元素 6 Entry<K,V> entry = getEntry(key); 7 // 返回值,这里也反映出HashMap的值也可以是null的 8 return null == entry ? null : entry.getValue(); 9 }
分析:
通过HashMap的get函数,可得出结论:HashMap的key可以为null,其value也可以为null,因为value相当于key的一个附属值,既然key可以为null,value当然也可以。
#1.getForNullKey函数
1 private V getForNullKey() { 2 // 如果HashMap中还未put元素,则直接返回null 3 if (size == 0) { 4 return null; 5 } 6 // 在table中循环,找到key为null的元素,直接返回去value 7 for (Entry<K,V> e = table[0]; e != null; e = e.next) { 8 if (e.key == null) 9 return e.value; 10 } 11 // 如果在table中未找到,则直接返回null 12 return null; 13 }
getForNullKey函数逻辑简单,通过以上注释,基本上可以理解清楚。
#2.getEntry(Object key) 函数
1 final Entry<K,V> getEntry(Object key) { 2 // 如果HashMap中没有元素,则直接返回null 3 if (size == 0) { 4 return null; 5 } 6 // 注意这里再次判断了key是否为null,然后通过hash算法计算出hashCode 7 int hash = (key == null) ? 0 : hash(key); 8 // 由于可能table上可能存在链表,所以这里要从table[index]开头进行循环 9 for (Entry<K,V> e = table[indexFor(hash, table.length)]; 10 e != null; 11 e = e.next) { 12 Object k; 13 // 当元素的hashCode和key相同时,直接返回元素 14 if (e.hash == hash && 15 ((k = e.key) == key || (key != null && key.equals(k)))) 16 return e; 17 } 18 // 如果未找到,则返回null 19 return null; 20 }
要点:通过key找元素的时候,由于HashMap的底层结构是数组+链表的形式,所以这里要进行循环。
2.3 其他重要函数
#1.removeEntryForKey(Object key),该函数为remove的核心函数。
1 final Entry<K,V> removeEntryForKey(Object key) { 2 // 如果HashMap中没有元素,则直接返回null 3 if (size == 0) { 4 return null; 5 } 6 // 计算key的hash值 7 int hash = (key == null) ? 0 : hash(key); 8 // 找到key在table上的位置 9 int i = indexFor(hash, table.length); 10 // prev记录table[i]的前一个元素,初始时等于table[i] 11 Entry<K,V> prev = table[i]; 12 // e记录要删除元素开始处,初始时等于table[i] 13 Entry<K,V> e = prev; 14 15 // 循环寻找要删除的元素 16 while (e != null) { 17 // 由于table中可能存在链表,所以需要记录一下next的值。 18 Entry<K,V> next = e.next; 19 Object k; 20 // 当e的hashCode和key与入参相同时,则找到要删除的元素 21 if (e.hash == hash && 22 ((k = e.key) == key || (key != null && key.equals(k)))) { 23 modCount++; // 修改次数加1 24 size--; // HashMap包含元素减1 25 // 因为初始时,prev=e,也就是说要移除的元素就是table[i]上,则直接将table[i]指向e.next,后面的都不需要移动 26 if (prev == e) 27 table[i] = next; 28 else 29 prev.next = next; // 如果prev!=null,prev记录的是当前准备删除元素的前一个元素,这里直接将prev.next存储e的next值,就把e踢出了,prev和e的后一个元素形成了链表 30 e.recordRemoval(this); 31 return e; 32 } 33 // 如果上述未找到,则prev=e,记录要当前准备删除元素的前一个元素 34 prev = e; 35 // e赋值为next继续删除操作 36 e = next; 37 } 38 39 return e; 40 }
分析:
removeEntryForKey函数用得非常巧妙,只修改了一个节点的next值,就进行了删除操作,注意理解具体的删除逻辑。
为了更直观的了解remove的过程,笔者这里通过源码的调试来展示其具体过程:
1 public static void main(String[] args) { 2 3 String key_Aa = "Aa"; 4 String key_BB = "BB"; 5 6 // 注意这里的hashCode值 7 System.out.println("key_Aa hashCode=" + key_Aa.hashCode()); 8 System.out.println("key_BB hashCode=" + key_BB.hashCode()); 9 10 Map<String, String> hashMap = new HashMap<String, String>(); 11 12 hashMap.put(key_Aa, "Aa"); 13 hashMap.put(key_Aa, "Aa"); 14 hashMap.put(key_BB, "Aa"); 15 hashMap.remove(key_BB); 16 // hashMap.remove(key_Aa); 17 System.out.println(hashMap); 18 19 }
将上述代码Debug:

注意:由于“Aa”和“BB”的hashCode相等,所以此时HashMap是链式存储,顺序为key:BB->Aa。
直接进入remove函数内部:
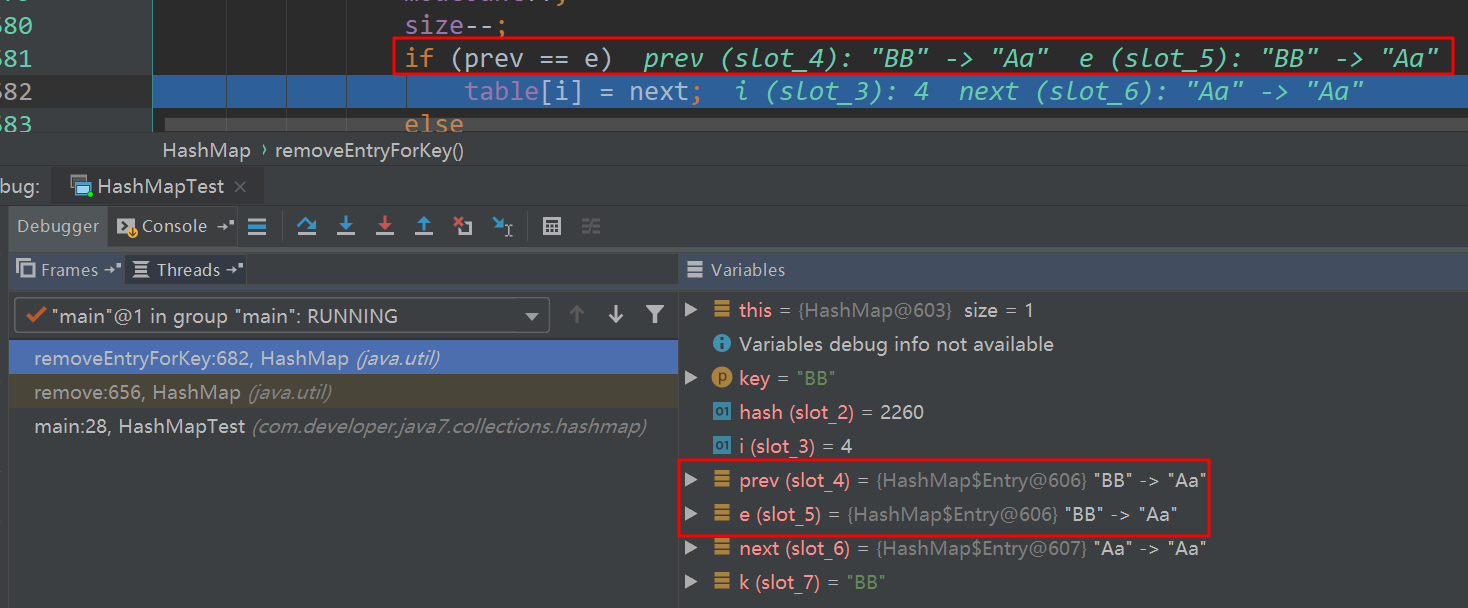
此时找到了删除元素,并且prev与e是相等的,所以直接将table[i]=next就移除了e了。
将上述代码15行注释,打开16行,再次进入remove内部:
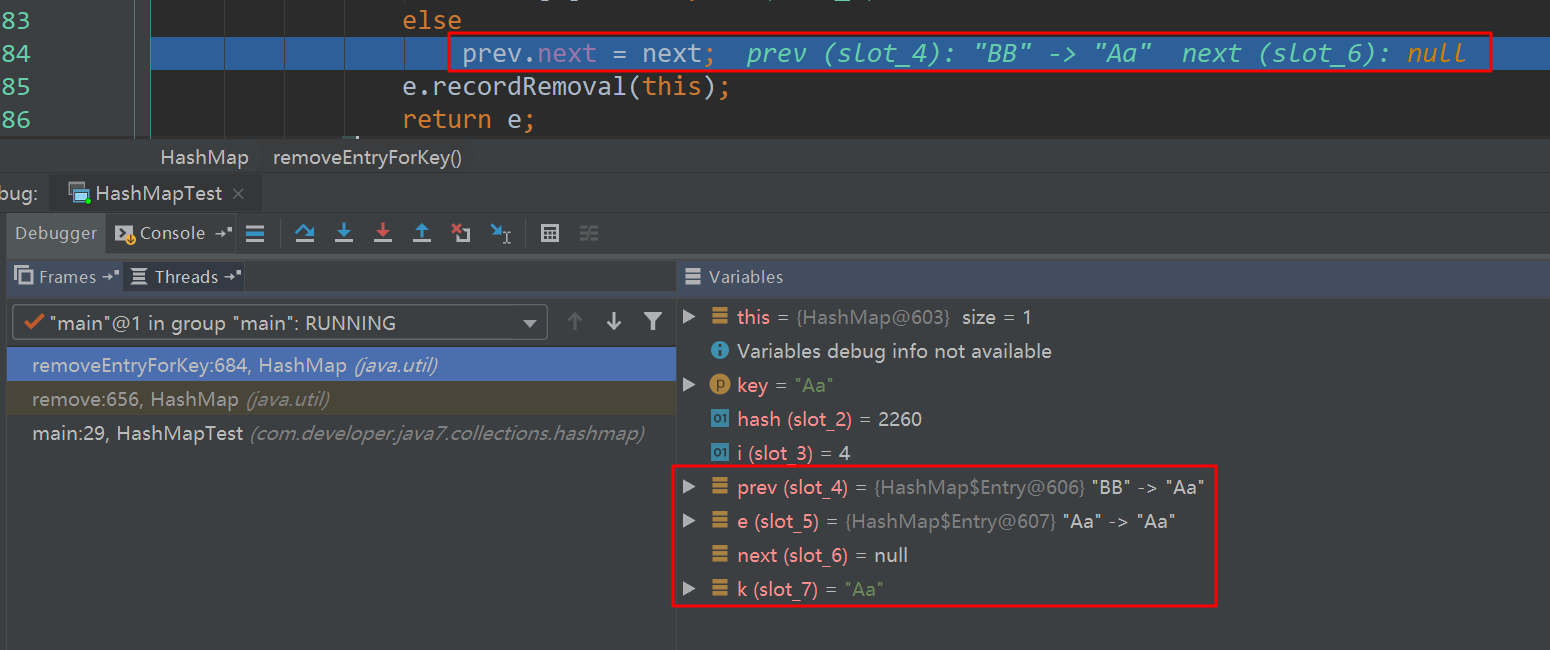
分析:
由于table[i]头上放置的是key为BB的元素,所以在第一次比较的时候,直接跳过,此次prev=BB,e=Aa,从这里可以看出,prev存储的是当前将要删除元素的前一个元素,所以删除时直接使用prev.next=next就踢出e了。
通过以上Debug过程,删除元素的过程应该非常清晰了。
#2.HashMap的fail-fast机制。
还是通过代码入手:
1 package com.developer.java7.collections.hashmap; 2 3 import java.util.HashMap; 4 import java.util.Map; 5 6 /** 7 * @author: developer 8 * @date: 2019/3/3 9:29 9 * @description: hashmap测试 10 */ 11 12 public class HashMapTest { 13 14 public static void main(String[] args) { 15 16 String key_Aa = "Aa"; 17 String key_BB = "BB"; 18 String key_Cc = "Cc"; 19 String key_Dd = "Dd"; 20 21 // 注意这里的hashCode值 22 System.out.println("key_Aa hashCode=" + key_Aa.hashCode()); 23 System.out.println("key_BB hashCode=" + key_BB.hashCode()); 24 25 Map<String, String> hashMap = new HashMap<String, String>(); 26 27 hashMap.put(key_Aa, "Aa"); 28 hashMap.put(key_Aa, "Aa"); 29 hashMap.put(key_BB, "Aa"); 30 hashMap.put(key_Cc, "Cc"); 31 hashMap.put(key_Dd, "Dd"); 32 for (String key : hashMap.keySet()) { 33 if (key_Dd.equals(key)) { 34 hashMap.remove(key); 35 } 36 } 37 System.out.println(hashMap); 38 39 } 40 41 }
运行结果如下:
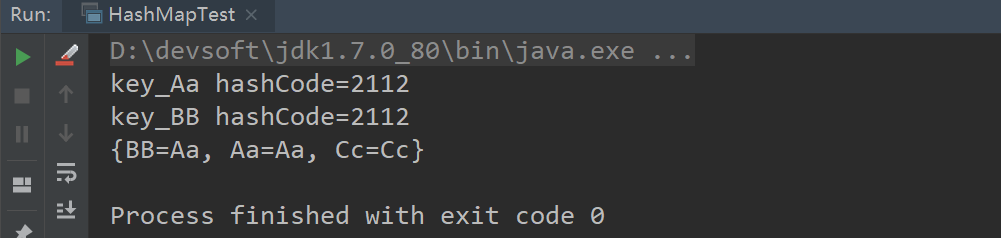
将代码稍微修改一下:
1 public static void main(String[] args) { 2 3 String key_Aa = "Aa"; 4 String key_BB = "BB"; 5 String key_Cc = "Cc"; 6 String key_Dd = "Dd"; 7 8 // 注意这里的hashCode值 9 System.out.println("key_Aa hashCode=" + key_Aa.hashCode()); 10 System.out.println("key_BB hashCode=" + key_BB.hashCode()); 11 12 Map<String, String> hashMap = new HashMap<String, String>(); 13 14 hashMap.put(key_Aa, "Aa"); 15 hashMap.put(key_Aa, "Aa"); 16 hashMap.put(key_BB, "Aa"); 17 hashMap.put(key_Cc, "Cc"); 18 hashMap.put(key_Dd, "Dd"); 19 for (String key : hashMap.keySet()) { 20 if (key_Cc.equals(key)) { 21 hashMap.remove(key); 22 } 23 } 24 System.out.println(hashMap); 25 26 }
运行结果如下:
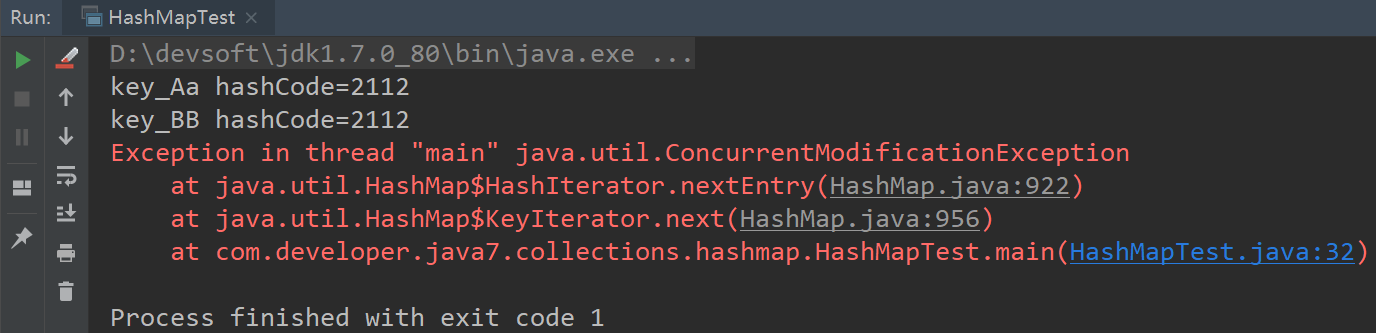
出现异常了,接着修改代码,依次移除key_Aa,key_BB都会报该异常,只有删除最后一个元素不会报异常,这是HashMap的fail-fast机制。
为什么删除最后一个元素不会报错呢,这里简要分析一下:
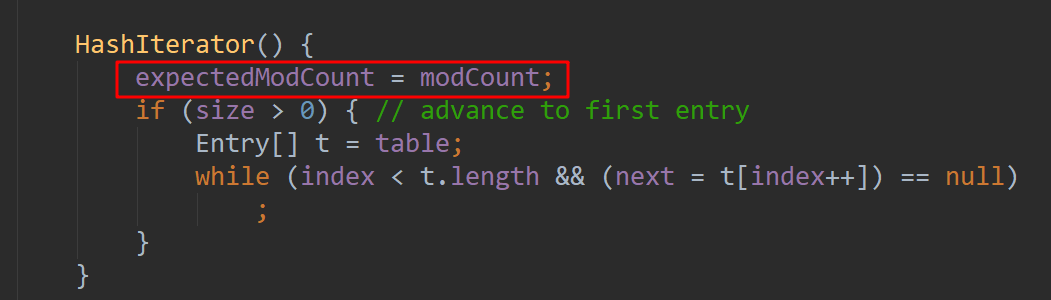
在循环初始化Iterator时,会先记录HashMap修改的次数。
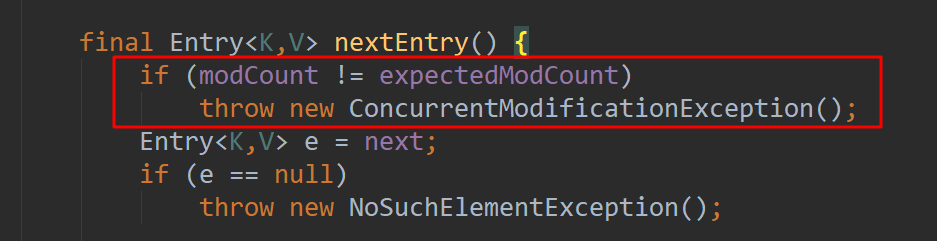
每次去获取nextEntry元素时,会判断modCount是否和expectedModCount是否相等,如果不相等则直接抛出异常。因为expectedModCount只是最开始的是否记录了modCount的值,后续modCount修改后并不会更新expectedModCount,所以remove时抛出异常。
但是为什么删除最后一个元素不抛异常呢?
这里的next已经为null了,不会往下走了,所以不抛异常,但是如果next不为null,也会抛异常的。
HashMap本身线程不安全,所以出现fail-fast也是正常的,在面对并发修改时,迭代器很快就会抛出异常,从而确定修改方法。
总结
至此,HashMap源码基本分析完了,后续如果还有一些重要的点,再加上。这里将源码分析中的重点再次总结一下:
#1.HashMap无序,通过源码调试的截图可知,因为HashMap是根据key的hash值来进行存储的,从这里也可以确定HashMap是无序的。
#2.HashMap线程不安全。
#3.HashMap可以存储key=null和value=null的值。
by Shawn Chen,2019.03.05,下午。