参考吴恩达课程
参考链接:
一、实用层面
数据集:训练集、验证集、测试集
超参数:神经网络层数、每个隐藏层的神经元个数、学习因子、激活函数
最佳参数的获得:循环迭代:
针对不同问题的最佳选择:样本数量、输入特征、GPU/CPU
1、数据集
(1)Train/Dev/Test
Train sets: 训练模型
Dev sets: 验证不同算法表现情况,选择最好的算法模型
Test sets: 测试最好算法的实际表现,进行无偏估计
2、模型拟合
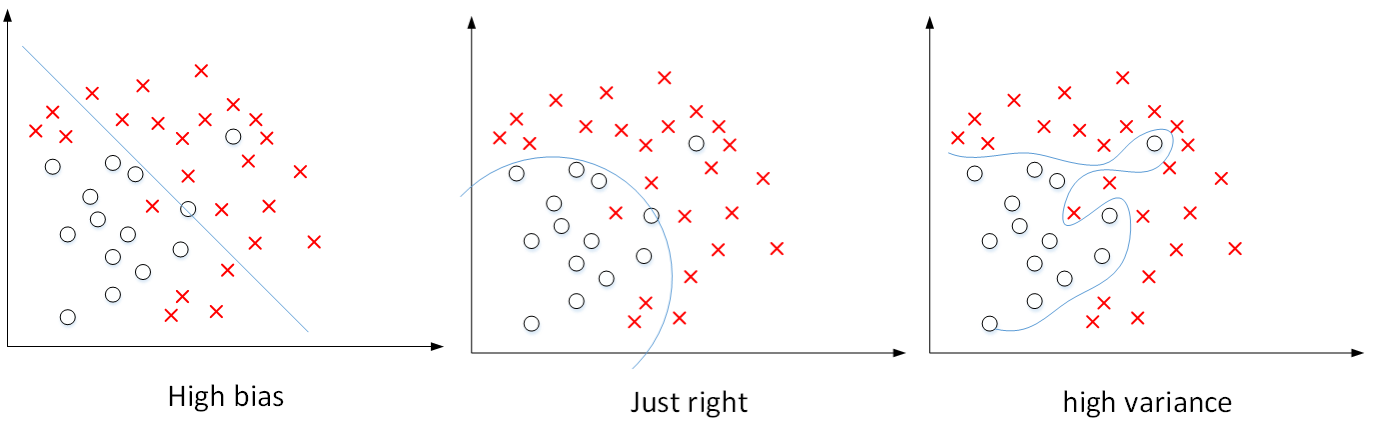
(1) Bias/Variance
深度学习目标:同时减小 Bias和Variance, 构建最佳神经网络模型
high bias: 欠拟合
high variance: 过拟合
图例的输入特征为二维:Train set error 体现bias, Dev set error 与 Train set error的差值体现variance
(2) Basic Recipe for Machine Learning
high bias 的减小:增加隐藏层个数、神经元个数、训练时间延长、更复杂的NN模型
high variance的减小:增加训练样本数据、正则化Regularization
(3) Regularization
L2 refularization表达式:
梯度下降算法:
选择合适大小的,能够同时避免high bias 和hige variance
(4) Dropout Regularization
Droupout: 训练中,每层的神经元按一定概率将其暂时从网络中丢弃
notice: 在测试和实际应用模型时,不需要进行dropout和随机删减神经元
(5) other regularization methods
1.增加训练样本
2.data augmentation:
- 水平翻转、垂直翻转、任意角度旋转、缩放或扩大
- 任意旋转或扭曲、增加noise
- early stopping: 减少训练次数防止过拟合,但是cost function(J)不会足够小)
3、数据处理
(1) Normalizing inputs
(2) Vanishing and Exploring gradients
梯度消失和梯度爆炸:层数过多
(3) Gradient Check
- 不要在整个训练过程中都进行梯度检查,仅作debug
- 如果梯度检查出现错误,找到对应出错的梯度,检查其推导是否出现错误
- 注意不要忽略正则化项,计算近似梯度的时候要包括进去
- 梯度检查时关闭dropout,检查完毕后再打开dropout
- 随机初始化时运行梯度检查,经过一些训练后再进行梯度检查
二、优化算法
Mini-batch gradient descent
Batch Gradient Descent: 所有m个样本,称为batch,通过向量化方法同时进行,训练速度慢
Mini-batch Gradient Descent: 把m个样本分为若干个子集,称为mini-batches
: 第i个样本
: 神经网络l层的线性输出
: 第t组mini-batches
算法
三、超参数调试、Batch正则化和编程框架
1、Tuning Process
(1) 超参数:
: 学习因子,待调范围
,主要分布区间
: 动量梯度下降因子,待调范围
: Adam算法参数,一般
,
和
- layers: 神经网络层数
- hidden units: 各隐藏层神经元个数
- learning rate decacy: 学习因子下降参数
- mini-batch size: 批量训练样本包含的样本个数
选择和调试:随机采样由粗到细采样(放大表现较好区域)
(2) Using an appropriate scale to pick hyperparamenters
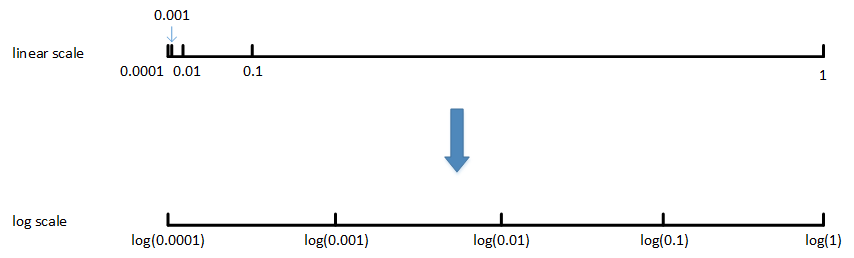
import numpy as np
a=0.0001
b=1
m=np.log10(a) #-4
n=np.log10(b) #0
r=np.random.rand()
r=m+(n-m)*r
r=np.power(10,r)
"""
m: -4.0
n: 0.0
[0,1]内随机数: 0.836032416605245
对指数区间[m,n]随机采样: -0.6558703335790201
反推到线性空间: 0.2208664070929086
"""(3) Hyperparameters tuning in pratice: Pandas vs. Caviar
- Babysitting one model: 受计算能力所限,只能对一个模型进行训练
调试不同的超参数,使得这个模型有最佳表现,类别Panda approach
- Training many models in parallel: 对多个模型同时进行训练
每个模型上调试不同的超参数,根据表现情况,选择最佳的模型,类别Caviar approach
(4) Normalization activations in network
Batch Normalization: 对l层隐藏层的输入做标准化处理:
m是单个mini-batch包含样本个数,可取
,防止分母为0
均值和方差的调整:
tips:
- Normalizing inputs: 使输入均值为0,方差为1
- Batch Normalization: 使各隐藏层输入的均值和方差为任意值
- activation function: 隐藏层输入的均值靠近0,处于激活函数线性区域,不利于训练好的非线性神经网络
2、Batch 正则化
(1) Fitting Batch Norm into a neural network

- Batch Norm对各隐藏层
有去均值的操作
的数值效果可由
- 梯度下降算法:分别
,
和
迭代更新
(2) Why does Batch Norm work?
- covariate shift: 训练样本和测试样本分布的变化
- covariate shift导致模型预测效果变差,重新训练的模型各隐藏层的
- Batch Norm: 减小covariate shift的影响,让模型更加健壮、鲁棒性更强
- Batch Norm减少了各层
(3) Batch Norm at test time
训练过程:Batch Norm 对单个mini-batch进行操作
测试过程:仅一个样本,求均值方差无意义,需要对和
进行估计
- 对l层隐藏层,考虑所有mini-batch在该隐藏层下的
和
- 指数加权平均预测当前单个样本的
- 利用训练过程得到的
和
(4) Softmax Regression
目的:处理多分类问题
- 用C表示种类个数,神经网络输出层有C个神经元,即
- 每个神经元的输出对应属于该类的概率
- 输出层激活函数:
,
- 输出层
:对应属于该类的概率
- 所有
,维度
3、Deep learning frameworks
(1) 根据需要选择最合适的深度学习框架
- Ease of programming(development and deployment)
- Running speed
- Truly open(open source with good governance)
(2) Tensorflow
cost function:
import numpy as np
import tensorflow as tf
w=tf.Variable(0,dtype=tf.float32)
cost=w**2-10*w+25
train=tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init=tf.global_variables_initializer()
session=tf.Session()
"initialize"
session.run(init)
print(session.run(w))
"train one time"
session.run(train)
print(session.run(w))
"train"
for i in range(1000):
session.run(train)
print(session.run(w))
"""
output:
0.0
0.099999994
4.9999886
"""
(3) Tensorflow优点
- 数据流图(data flow graphs): 进行数值运算
- 节点(Nodes): 表示数学操作
- 线(edges): 表示节点间相互联系的多维数据数组,即张量(tensor)
import numpy as np
import tensorflow as tf
coefficients=np.array([[1],[-10],[25]])
w=tf.Variable(0,dtype=tf.float32)
x=tf.placeholder(tf.float32,[3,1])
cost=x[0][0]*w**2-x[1][0]*w+x[2][0]
train=tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init=tf.global_variables_initializer()
session=tf.Session()
"initialize"
session.run(init)
print(session.run(w))
"train one time"
session.run(train, feed_dict={x:coefficients})
print(session.run(w))
"train"
for i in range(1000):
session.run(train, feed_dict={x:coefficients})
print(session.run(w))
"""
output:
0.0
-0.099999994
-4.9999886
"""