【软件工程综合实践专题】
——程序简单测试、维护、升级
tips:[Jewish]SHOU 1759223 软工2 版权所有 转载请注明
目录
《软件工程综合实践专题》……1
——程序简单测试、维护、升级……1
1.源代码……2
2.代码分析……3
3.自我需求增加……4
*4.新增需求测试用例……5
5.根据自我需求增量开发……6
6.感悟总结……7
Page 2 源代码
①程序代码如下(如侵删):本代码为本人在中国慕课学习python爬虫时所学 代码为参考自以下链接地址:
——(不过我推荐学python爬虫意向的萌新可以学习一下本网络课程)中国大学Mooc 北京理工大学 嵩天
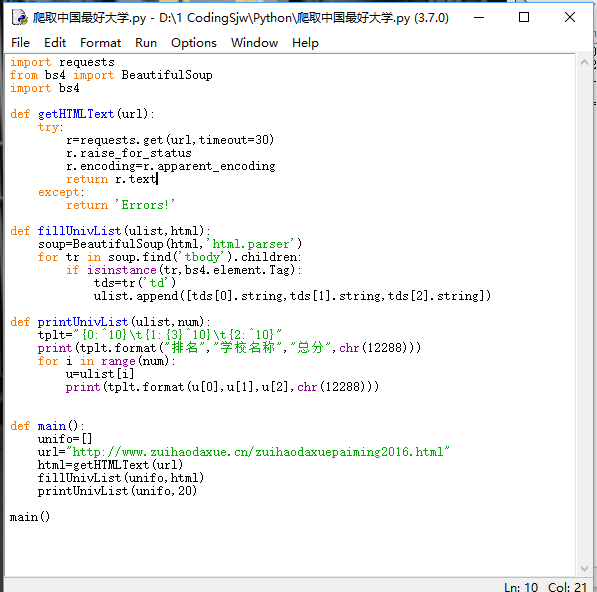
②程序运行结果:

Page 3 代码分析
①功能分析:通过python语言实现了模拟访问《最好大学网》(http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html)并且抓取信息并使用正则表达式提取需要信息在本地显示的功能,实际上就是python实现的爬虫小程序。

②python语言分析:python简洁易懂,对于初学者极易上手,特别对于有其他编程语言基础者更易上手,本人在大一暑假花费7天就学完了python的基本语法并根据自我需求并通过搜索引擎解决问题编写出了本人大学的一卡通变账服务,并且已经挂在服务器上运行(部分源代码在第六页 根据自我需求增量开发一栏)。而且python相较于其他编程语言更容易编写爬虫也更适合编写爬虫,主要原因有以下两个:
a.直接获取网页本身接口
与其他编程语言相比,python更容易抓取网络接口;除此之外,python提供了比其他语言更多的API;有时爬虫要模拟浏览器行为防止被防爬机制封杀ip;python拥有更多的第三方包,比如beautifulsoup 可以更好的处理获得的html王爷代码并提取有效信息。
b.网页信息处理
抓取的网页需要处理,过滤标签,提取信息。“美味汤” 库能用极短的代码完成大部分文档的处理。
③尊重爬虫robots协议:遵守职业道德
恶劣的爬虫可能造成网站服务器的崩溃,或者爬取不让爬的信息构成违法,这里我们在爬取一个网站时需要注意每个网站的robots协议,比如我们想爬www.baidu.com输入www.baidu.com/robots.txt则会出现这个网站提供给的道德的爬取规范,虽然不是硬性规定,但出于职业操守或道德我们最好遵守。如果某个网站的robots.txt找不到网站,则网站运行方没有给出规则,根据需要自行决定,我们的爬虫频率不要太快以免给网站服务器造成负荷。
④代码分析:
输入:url链接(定向爬虫)
输出:大学排名信息的屏幕输出(排名,大学名称,地区)
技术:python的requests库以及bs4
步骤一:从网络获取排名 getHTMLText函数实现
步骤二:提取信息 fillUnivList函数实现
步骤三:筛选信息进行输出结果 printUnivList函数实现
首先我们引入所用到的requests库以及bs4库,写法以及功能类似于C语言的include<stdio.h>语句
我们在步骤一的函数中使用requests库的get函数得到url信息,然后使用raise_for_status函数获取异常信息,然后使用r.coding=r.apparent_encoding修改编码转换为我们看得懂的html代码,将html代码返回。
我们在步骤二的函数中使用bs4库并通过正则表达式参照网页源代码提取有效信息,先创建bs对象,然后筛选标签,提取信息
我们在步骤三的函数中进行格式控制,分为排名 学校 地区,以及显示功能
我们在主函数中给步骤一函数穿参 传网址 并调用其他两个函数 实现爬虫功能
Page 4 自我需求增加
对于这个程序来说我觉得功能一点都不实用,不如上网直接看,而我根据自我需求定制了以下需求:作为大学生,我就想出了一卡通实施变账短信提醒得服务。
1.能够爬取校园网并登陆我的账户 并且保存cookie 循环爬取的时候就不需要重复提交账户
2.每隔一段时间运行一次不至于给网站造成负担
3.每次运行需要与上次信息进行比较,如果变化,则根据充值还是消费发送短信提醒
4.由于自己电脑不可能一直开机运行,需要租借服务器(已租海外服务器,在搭建科学上网的主要目的后顺便挂自己实现的代码)
*Page 5 新增需求测试用例
1.测试用例说明:
假设测试用户使用中国地区的+86手机号码进行消息接收。功能如下:
当每次用户充值一卡通时,会在【0,爬取间隔频率】时间内收到信息提醒,提醒包括消费时间、地点、金额、余额等。
当每次用户消费一卡通时,会在【0,爬取间隔频率】时间内收到信息提醒,提醒包括消费时间、地点、金额、余额等。
表1
用例ID:180xxxx6896 2019-3-4
用例描述 校园一卡通变账服务提醒助手
用例接口 腾讯云下的sms短信服务(每个月免费100条)
用例ID 场景 步骤
180xxxx6896 充值 运行.py程序,等待消息
180xxxx6896 消费 运行.py程序,等待消息
175xxxx8730(本人另一号码)充值 运行.py程序,等待消息
175xxxx8730(本人另一号码)消费 运行.py程序,等待消息
Page 6 增量开发
1.需求确认:
a.能够爬取校园网并登陆我的账户 并且保存cookie 循环爬取的时候就不需要重复提交账户
b.每隔一段时间运行一次不至于给网站造成负担
c.每次运行需要与上次信息进行比较,如果变化,则根据充值还是消费发送短信提醒
d.由于自己电脑不可能一直开机运行,需要租借服务器(已租海外服务器,在搭建科学上网的主要目的后顺便挂自己实现的代码)
(2)设计:
a.第一次使用python post账户密码进入登陆后的界面 之后通过把cookie保存在模拟浏览器的头(head)里面进行免验证登陆从而解决第一个需求
b.用while True:
……
sleep(秒数)
来确定爬取频率解决需求2
c.每次爬取记录第一行数据,并与之前的数据加以比较,如果变化则需要发短信,如果变账金额号为-则为消费 否则为充值,从而满足需求三
d.租借Vultr服务器
(3)开发(以下所有代码均为本人所写)
1.为了解决需求b,c
while True:
headers={'User-Agent':'Mozilla/5.0(Windows NT 10.0;Win64;x64;rv:61.0) Gecko/20100101 Firefox/61.0'}
login()
results=useCookie()
way=results[3]
money=results[4]
check=results[5]
#处理爬取到的时间
time1=results[1].split(' ')[0]
time2=results[1].split(' ')[1]
time1=time1.split("-")
time2=time2.split(":")
date1=time1[0]+"-"+time1[1]+"-"+time1[2]
date2=time2[0]+":"+time2[1]+":"+time2[2]
#储存地址
address=results[2]
str1=''
str2=''
n=len(address)//2
m=len(address)-n
for i in range(n):
str1=str1+address[i]
for j in range(m):
str2=str2+address[n+j]
#判断是否发送信息
adj="不"
if decide!=check:
adj="已"
decide=check
#判断发送消费短信
if '-' in money:
#发信息需要所需要资料
############此处省略因为包含腾讯云个人用户以及密码信息
############
except HTTPError as e:
print(e)
except Exception as e:
print(e)
#判断发送充值短信
else:
#发信息需要所需要资料
############此处省略 因为包含腾讯云个人用户以及密码信息
############
print("您好!您于"+results[1]+"在"+address+"通过"+way+"充值了"+money+"余额为"+check+"元")
try:
result = ssender.send_with_param(86, phone_numbers[0],
template_id, params, sign=sms_sign, extend="", ext="") # 签名参数未提供或者为空时,会使用默认签名发送短信
except HTTPError as e:
print(e)
except Exception as e:
print(e)
fre=fre+1
freall=str(fre)
print("第"+freall+"次爬取成功!信息"+adj+"发送!")
time.sleep(10)
2.为了解决需求a:
#登陆账号 并返回头
def login():
############此处省略网址 因为包含个人用户以及密码信息
###########
try:
login_page=session.post(post_url,data=postdata,headers=headers)
login_code=login_page.text
except:
pass
return login_page.request.headers
3.为了解决需求d:
申请Vultr服务器并设置服务器
(3)回归测试:
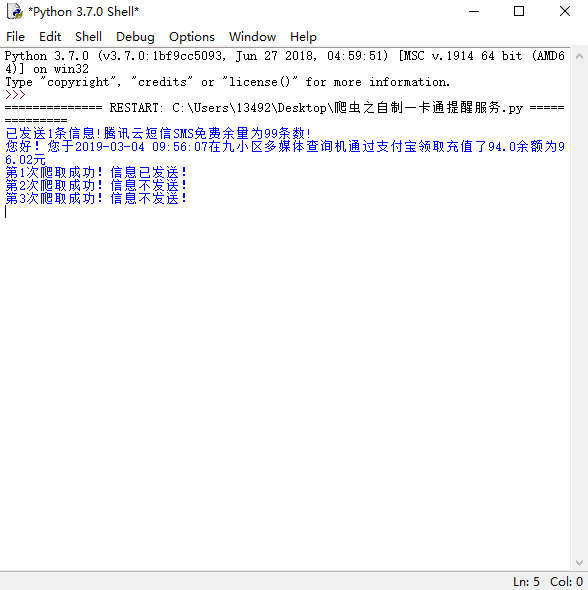
手机信息效果图:

综上所述 完成了我自己所添加的需求。
Page 7 感悟收获
我其实从早就想有一个属于自己的博客,可是都是由于三分钟热度而没能实现,这种形式的作业我觉得形式非常好,可以让我们养成分析技术、分享技术、记录技术的习惯,我希望通过一学期的坚持,我能够养成这种习惯,在博客圆、CSDN等博客中分享自己的技术以及学习技巧。这是我第一次这么认真的书写博客,当然了,还有很多不足,不足之处欢迎大家评论指出!谢谢!
python是一个极其易学又极其有用的语言,爬虫的应用也非常广泛,由于本人对it比较感兴趣,所以在大一暑假中学习的python语言以及爬虫技术,并完成了自己的这项需求,这里面也有百度谷歌搜素引擎的功劳,希望通过这种类型作业我希望能够激发我做更多好玩实用程序的激情。在以后的作业里或博客里会分享其它语言的程序以及各种软件的应用,如C C++ JAVA Python C# 软件方面涉及unity 3d/3dsmax/ecilpse/vc++6.0/vs 2017/dev c++/idle/aconoda/jupyter book
谢谢!
Jewish
2019年3月4日
欢迎来访问个人主页或评论,有空必回。