Spark SQL主要是操作DataFrame,DataFrame本身提供了save和load的操作.
Load:可以创建DataFrame;
Save:把DataFrame中的数据保存到文件或者说与具体的格式来指明我们要读取的文件的类型以及与具体的格式来指出我们要输出的文件是什么类型。
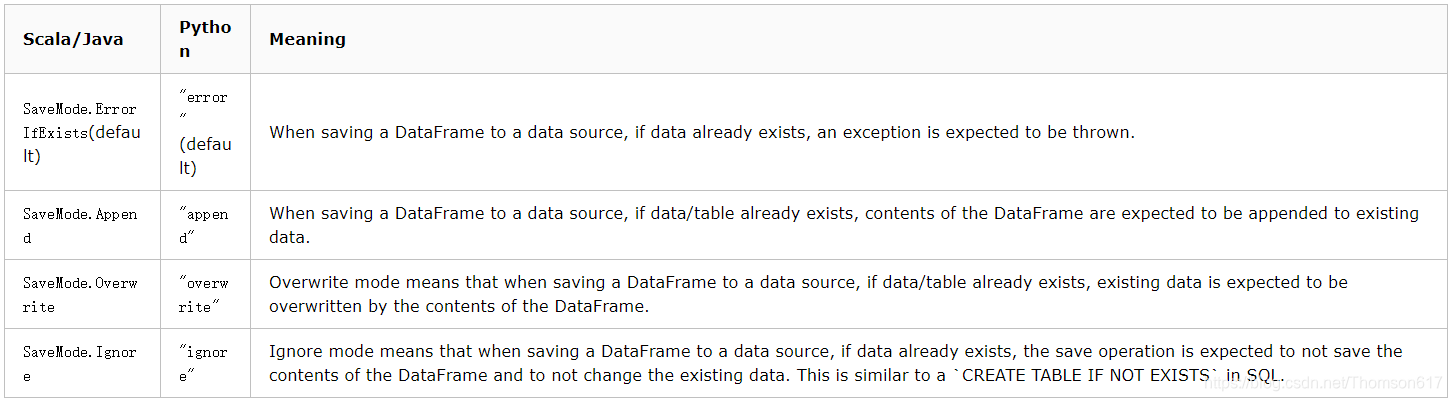
SparkSQL的保存模式
* SaveMode.ErrorIfExist ----->default 文件存在,保存失败,有异常
* SaveMode.Append ----->append 在现有的基础之上追加新的数据
* SaveMode.Overwrite ----->overwrite 重写覆盖现有目录
* SaveMode.Ignore ----->ignore 忽略当前的保存操作
具体设置的话,使用mode()方法进行设置
SparkConf conf = new SparkConf().setAppName("SaveMode").setMaster("local");
//JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sc= new SQLContext(sc);
//重新加载以前的处理结果(可选)
sc.load("hdfs://node01.sun.com:9000/sql/res1")
sc.load("hdfs://node01.sun.com:9000/sql/res2", "json")
//读取hdfs中json格式的数据
DataFrame df = sc.read().json("hdfs://node01.sun.com:9000/input/student.json");
//以JSON文件格式覆写HDFS上的JSON文件
import org.apache.spark.sql.SaveMode._
result.save("hdfs://node01.sun.com:9000/sql/res2", "json" , Overwrite)
//直接保存
result.save("hdfs://node01.sun.com:9000/sql/res1")
result.save("hdfs://node01.sun.com:9000/sql/res2", "json")
//加载数据 默认加载的数据格式为parquet
DateFrame df=sc.read().parquet("hdfs://node01.sun.com:9000/output/aaa");
//df.show();
//将数据追加写入到hdfs文件系统中
df.write().mode(SaveMode.Append).save("hdfs://node01.sun.com:9000/output/aaa");