提交作业
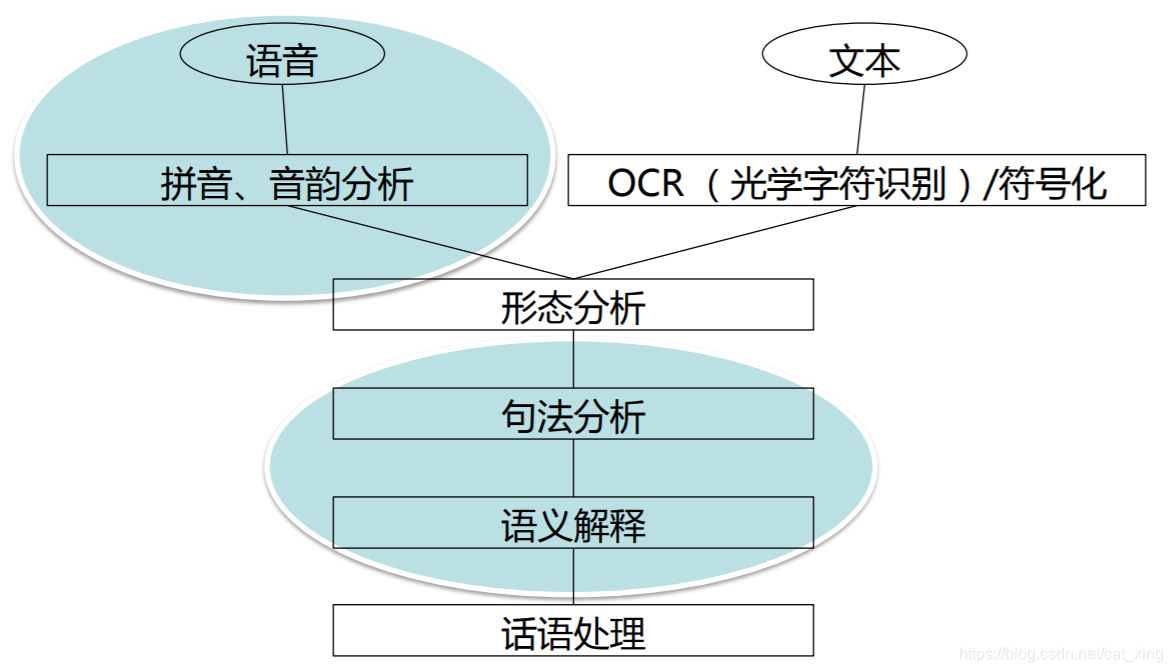
什么是自然语言处理 (NLP)?

NLP层级
NLP应用

NLP在工业上的应用越发广泛

深度学习在NLP中的应用

练习1:统计文本中的单词数
tr –sc ‘A-Za-z’ ‘\n’ < nyt_200811.txt | sort | uniq –c
首先用<符导入文件,然后使用tr缩减连续重复的字符成\n,再用sort命令将文本文件的第一列以ASCII码的次序排列,并结合uniq命令删除文本文件中重复出现的行列,将结果输出到标准输出。
tr [OPTION]…SET1[SET2]
- Linux tr 命令用于转换或删除文件中的字符
- -s, --squeeze-repeats:缩减连续重复的字符成指定的单个字符
- -c, --complement:反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][–help][–version][输入文件][输出文件]
- -c或–count 在每列旁边显示该行重复出现的次数。
扩展计数练习
- 通过将所有大写字母转换成小写字母来合并大小写
tr -sc 'A-Za-z' '\n' < nyt_200811.txt | tr 'A-Z' 'a-z' | sort | uniq -c
- 不同的元音序列的频次
tr -sc 'A-Za-z' '\n' < nyt_200811.txt | tr 'A-Z' 'a-z' | tr -sc 'a
eiou' '\n' | sort | uniq -c
练习2:以不同方式对单词列表进行排序
- 找出 NYT 中最常见的50个单词
tr -sc 'A-Za-z' '\n' < nyt_200811.txt | sort | uniq -c | sort -nr | head -n 50
sort
[-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][–help][–verison][文件]
- -n 依照数值的大小排序。
- -r 以相反的顺序来排序。
- 找出 NYT 中以“zz”为结尾的单词
tr -sc 'A-Za-z' '\n' < nyt_200811.txt | tr 'A-Z' 'a-z' | rev | sort | uniq -c | rev | tail -n 7
练习3:抽取字典中的有用信息
(找出 NYT 中以“zz”为结尾的单词)
练习4:计算N-Gram(语言模型)统计数据
Bigrams

tail [参数] [文件]
- -n<行数> 显示文件的尾部 n 行内容
- tail -n 100 /etc/cron #显示最后100行数据
- tail -n -100 /etc/cron #除了前99行不显示外,显示第100行到末尾行
- tail +20 notes.log #显示文件 notes.log 的内容,从第 20 行至文件末尾
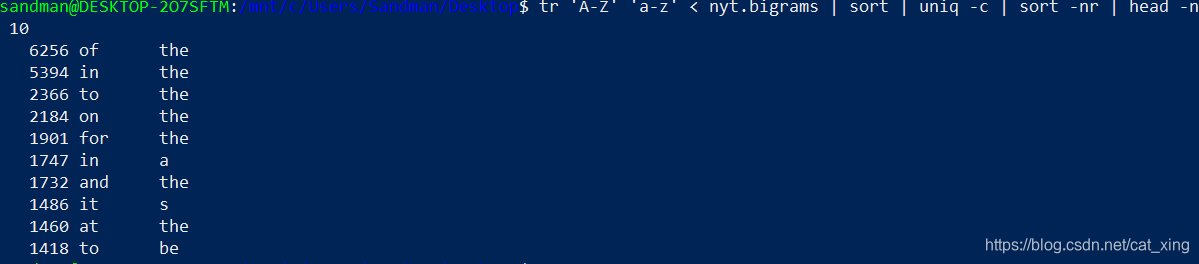
- 找出10个最常见的二元语法
tr 'A-Z' 'a-z' < nyt.bigrams | sort | uniq -c | sort -nr | head -n 10
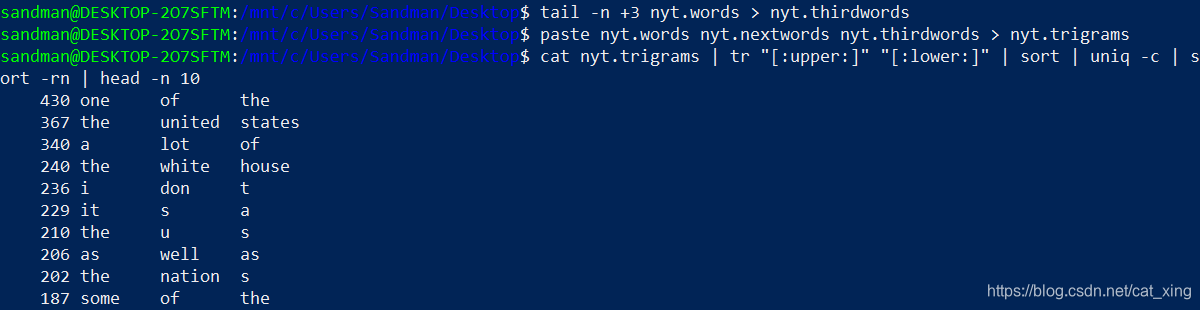
- 找出10个最常见的三元语法
$ tail -n +3 nyt.words > nyt.thirdwords
$ paste nyt.words nyt.nextwords nyt.thirdwords > nyt.trigrams
$ cat nyt.trigrams | tr "[:upper:]" "[:lower:]" | sort | uniq -c | sort -rn | head -n 10
练习5:处理标记文本中的词性
练习:grep & wc
- NYT文件中,有多少字母全为大写的单词?
grep -P '^[A-Z]+$' nyt.words | wc
-P 可以让grep使用perl的正则表达式语法,因为perl的正则更加多元化,能实现更加复杂的场景。
^:匹配输入字符串的开始位置。
- 共有多少4位字母的单词?
grep -P '^[a-zA-Z]{4}$' nyt.words | wc
- 共有多少不含元音的单词?他们属于哪种类型?
grep -v '[AEIOUaeiou]' nyt.words | sort | uniq | wc
- 共有多少单音节单词?
tr 'A-Z' 'a-z' < nyt.words | grep -P '^[^aeiouAEIOU]*[aeiouAEIOU]+[^AEIOUaeiou]*$' | uniq | wc
看不太懂这个正则表达式。。。
第2节练习:Python正则表达式
- 请在网页链接“http://www.poshoaiu.com and https://iusdhbfw.com”中,匹配出“http://”和“https://”
import re
key = r"http://www.poshoaiu.com and https://iusdhbfw.com"
p1 = r"https*://"
pattern1 = re.compile(p1)
print pattern1.findall(key)
- 请在字符串“[email protected]”中,匹配出“@hotmail.”
import re
key = r"[email protected]"
p1 = r"@.+?\."
pattern1 = re.compile(p1)
print pattern1.findall(key)
- 请用非懒惰匹配的方法,在字符串“[email protected]”中,匹配出“@hotmail.”
import re
key = r"[email protected]"
p1 = r"@[^.]+\."
pattern1 = re.compile(p1)
print pattern1.findall(key)