可重定位目标
重定位是将EFL文件中的未定义符号关联到有效值的处理过程。在main.o中,这意味着对printf和puts的未定义的引用必须替换为该进程的虚拟地址空间中适当的机器代码所在的地址。在目标中用到的相关符号之处,都必须替换。
对用户空间程序符号的替换,内核并不涉及其中,因为所有的替换操作都是由外部工具完成的。对内核模块来说,情况有所不同,因为内核所收到的模块裸数据,与其存储在二级制文件中的形式完全相同,内核本身需要负责重定位操作。
在每个目标文件中,都有一个专门的表,包含了重定位项,标识了需要进行重定位之处。每个表项都包含下列信息:
1)一个偏移量,指定了修改的项的位置
2)对符号的引用(符号表的索引),提供了需要插入到重定位位置的数据
重定位步骤
1)重定位节和符号定义。
链接器将所有相同类型的节合并为同一类型的新的聚合节。例如来自输入模块的.data节全部合并成一个节,这个节成为输出可执行目标文件的.data节。然后链接器将运行时存储器地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号。当这一步完成时,程序中的每个指令和全局变量都有唯一的运行时存储器地址了。
2)重定位节中的符号引用。
在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得他们指向正确的运行时地址。为了执行这一步,链接器依赖于称之为重定位条目的可重定位目标模块中的数据结构。
重定向条目
当汇编器生成一个目标模块时,它并不知道数据和代码最终将存放在存储器中的什么位置。它也不知道这个模块引用的任何外部定义的函数和全局变量。所以,无论何时汇编器遇到对最终位置未指定目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并可执行文件时如何修改这个引用。代码重定位条目放在.rel.text中。已经初始化数据的重定位条目放在.rel.data中。
数据结构
由于技术原因,有两种类型的重定位信息,由两种稍有不同的数据结构表示。第一种类型称之为普通重定位。SHT_REL类型的节中的重定位项由以下数据结构定义:
/*Relocation table entry without addend (in section of type SHT_REL). */
typedef struct
{
Elf32_Addr r_offset; /* Address */指定需要重定位的项的位置
Elf32_Word r_info; /* Relocation type andsymbol index */提供了符号表中的一个位置,同时还包括重定位类型的有个信息。这是通过将值划分为两部分来达到的。
r_info == int symbol:24,type:8;
} Elf32_Rel;
另一种类型,称之为需要添加常数的重定位项,只出现在SHT_RELA类型的节中。数据结构如下:
/* Relocation table entry with addend (insection of type SHT_RELA). */
typedef struct
{
Elf32_Addr r_offset; /* Address */
Elf32_Word r_info; /* Relocation type andsymbol index */
Elf32_Sword r_addend; /* Addend */加数,计算重定位是,将根据重定位类型,对该值进行不同的处理。
} Elf32_Rela;
截图例子
为说明如何使用重定位信息,我们看一下此前的main.c测试程序。首先readelf显示文件中所有的重定位项,如下所示:
在程序运行时或者链接main.o产生可执行文件时,如果某些机器代码引用了虚拟地址空间中位置尚不明确的函数或者符号,则将使用Offset列的信息。main的汇编语言代码调用了若干函数,分别位于偏移量0x26的puts和位于0x40的printf。这些可以使用objdump工具看到:
在puts和printf函数的地址已经确定后,必须将其插入到指定的偏移量处,以便生成能够正确运行的可执行代码。
重定位类型
ELF定义了很多重定位类型,对每种支持的体系结构,都有一个独立的集合。这些类型大部分用于生成动态或与装载位置无关的代码。在一些平台上,特别是IA32平台,还必须弥补许多设计错误和历史包袱。幸运的是,Linux内核只对模块的重定位感兴趣,因此用以下两种重定位类型就可以了:
1)相对重定位
2)绝对重定位
相对重定位生成的重定位表项指向相对于程序计数器(pc,亦即指令指针)指定的内存地址。这些主要用于子例程调用。另一种重定位生成绝对地址,从名字就能看出。通常,这种重定位项指向内存中在编译时就已知的数据,例如字符串常数。
在IA32系统上,和两种重定位类型由常数R_386_PC_32(相对重定位)和R_386_32(绝对重定位)表示。重定位结果计算如下:
R_386_32:Result= S+A
R_386_PC_32:Result=S-P+A
A代表加数值,在IA32体系结构上,由重定位位置处的内存内容隐士提供(一般为操作码后面的数值)。S是符号表中保存的符号的值,而P代表重定位的位置偏移量,换言之,即算出的数据写入到二进制文件中的位置偏移量(修改处的运行时地址或者偏移,对于目标文件P为修订处段内的偏移,对可执行文件P为运行时的地址)。如果加数值为0,那么绝对重定位只是将符号表中的符号的值插入在重定位位置。但在相对重定位中,需要计算符号位置和重定位位置之间的差值。换言之,需要通过计算确定符号与重定位位置相距多少字节。
在这两种情况下,都会加上加数值,因而使得结果产生一个线性位移。
举例说明
这是一个难点,但是掌握了技巧也很简单。
首先协助说明的三个c源文件:
a.c

b.c
main.c

首先我们明确的是重定向发生在链接的时候,当多个输入最终链接成一个目标文件的时候,当符号解析完成之后。
在此例子中,a.c和b.c没有外部引用,所以在.o文件中不存在重定位表项,只有main.o存在,如图:
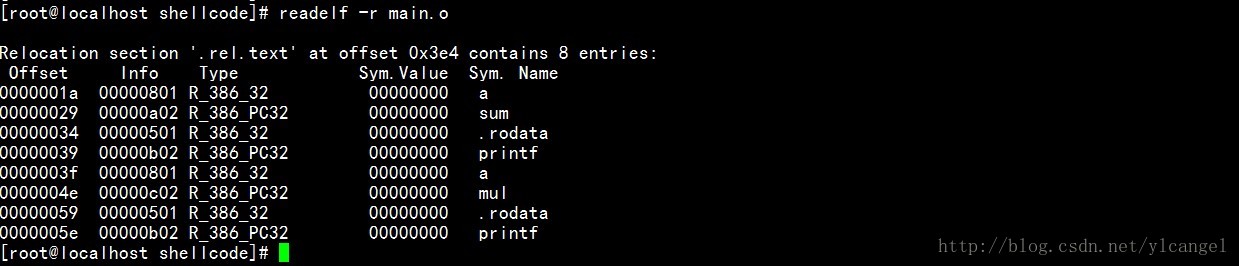

从main.c源文件也不难看出,它引用了外面sum和mul符号,并且引用了一个全局a符号。并且从上图也可以看出。并且a的重定位类型为绝对定位,而其他两个为相对重定位。
并且可以得到:
a第一处r_offset : 0x1a 重定位的字节处 并且从第二幅图可以得知a的大小为4个字节
a第二处r_offset : 0x3f
sumr_offset : 0x29
mulr_offset : 0x4e
计算a的重定位后的地址:根据公式S+A
S为目标文件符号表中的对应的地址(为什么不是.o文件呢,因为.o文件的符号表中的地址都是重定位REL类型,都为0):
如图:
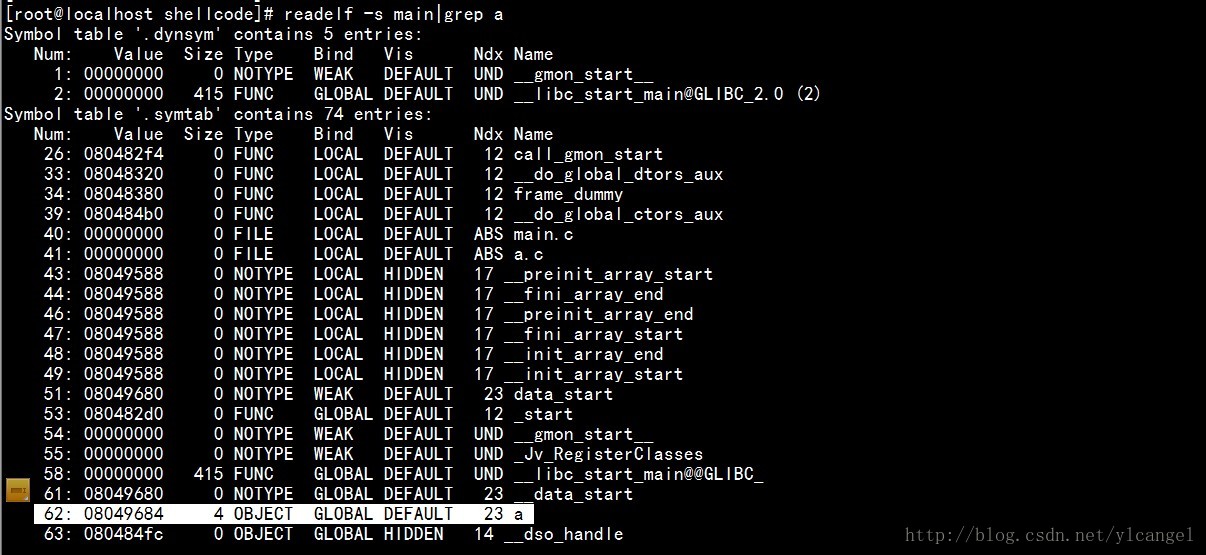
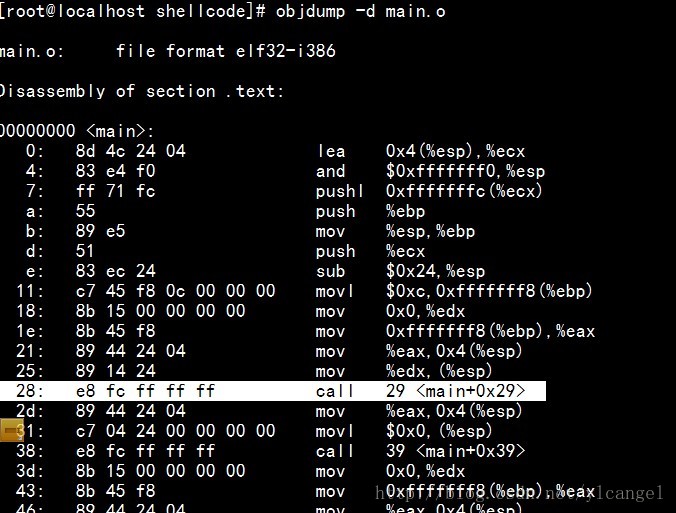
可以得到S(a) = 0x8049684,接下来要确定加值A,这要看main.o 的汇编代码了,利用objdump来查看该.text节的汇编代码:
Disassembly of section .text:
00000000 <main>:
0: 8d 4c 24 04 lea 0x4(%esp),%ecx
4: 83 e4 f0 and $0xfffffff0,%esp
7: ff 71 fc pushl 0xfffffffc(%ecx)
a: 55 push %ebp
b: 89 e5 mov %esp,%ebp
d: 51 push %ecx
e: 83 ec 24 sub $0x24,%esp
11: c7 45 f8 0c 00 00 00 movl $0xc,0xfffffff8(%ebp)
18: 8b 15 00 00 00 00 mov 0x0,%edx
怎么读这些代码呢?其实很简单,从这些汇编代码可以看出它的每行包含个部分:
1)左边两栏中最左面一栏是上面所有机器指令的字节数(16进制),紧接着其后的是机器代码(十六进制形式)
其实真正的二进制代码是这样的(十六进制),前两行8d 4c 24 04 83 e4 f0,工具为了方便阅读。
我在工具的基础上为了方便说明这两栏,只提取了前面两栏(好比一个大的字节数组从零开始)。
0: 8d 4c 24 04 以前是0个字节,下标是从0开始,其中8d是操作码
4: 83 e4 f0 上面一共四个字节,此行小标也是从4开始,83是操作码
2)最后一栏是汇编指令
lea 0x4(%esp),%ecx
and $0xfffffff0,%esp
这没什么好讲的就是汇编指令。
明白了这些就应该很容易看下面的图片了:
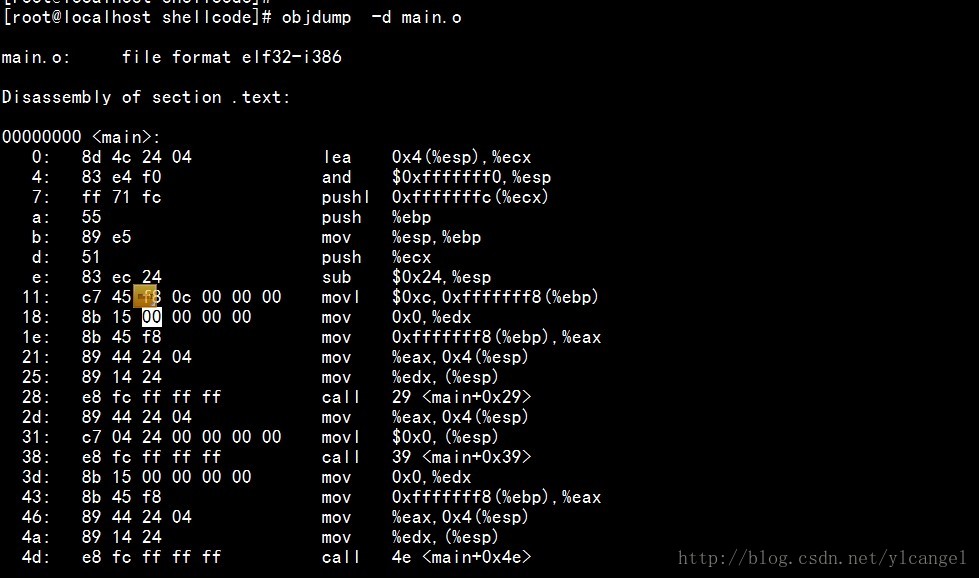
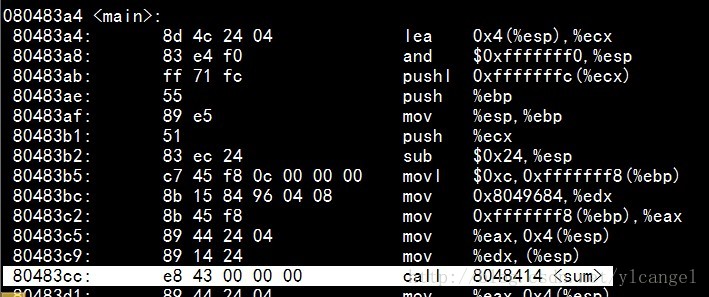
在图片中我特意标出了0x1a后面的4个字节的位置,其后0x00000000=0所有加值为0,则Result=0x8049684+0=0x8049684,也就是目标文件的1a后面的后4个字节要被替换为该值。现在我们验证一下:
从图中可以看出,在1a(对应15)开始后的4个字节为84 96 04 08,因为是小端表示法,所所以倒过来就是08049684和上面的一样。
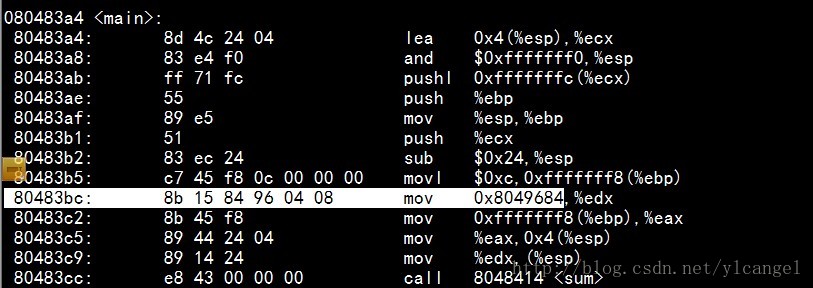
相对重定位的计算:
以sum为例(由前面的截图和计算可以得知r_offset=0x29):

S(sum)= 0x8048414
A(sum)= 0xfffffffc = -4(2的补码形式)
P(sum)= 0x80483cc+1(操作指令一个字节) = 0x80483cd --运行时地址
Result= S+A-P
= 0x8048414-4-0x80483cd
= 0x43
如图e8之后是00 00 0043(小端)。
在运行时,call指令将放在0x0x80483cc处,当cpu执行call指令时,pc的值为0x0x80483cc+1+4=0x0x80483d1,即紧随着call指令之后的指令的地址。为了执行这条指令,cpu执行以下的步骤:
1push PC onto stack
2 PC <- PC+0x43 = 0x0x80483d1 +0x43= 0x8048414
该地址恰好是swap的第一条指令的地址。