1. 概述
LinkedHashMap的遍历顺序与插入时的顺序相同。
例如:
LinkedHashMap<String, Integer> lmap = new LinkedHashMap<String, Integer>();
lmap.put("语文", 1);
lmap.put("数学", 2);
lmap.put("英语", 3);
lmap.put("历史", 4);
lmap.put("政治", 5);
lmap.put("地理", 6);
lmap.put("生物", 7);
lmap.put("化学", 8);
for(Entry<String, Integer> entry : lmap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
运行结果为:
语文: 1
数学: 2
英语: 3
历史: 4
政治: 5
地理: 6
生物: 7
化学: 8
LinkedHashMap的数据结构如下:
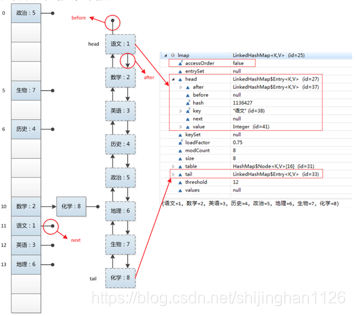
即LinkedHashMap仍沿用了HashMap的数组+链表的实现,只是对每个Node节点中添加了before和after指针,这样,就相当于用双向链表把每个元素串起来。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
LinkedHashMap 采用的 hash 算法和 HashMap 相同,但是它重新定义了数组中保存的元素 Entry,该 Entry 除了继承了HashMap的Entry外,还保存了其上一个元素 before 和下一个元素 after 的引用,从而在哈希表的基础上又构成了双向链接列表。
2. LinkedHashMap的元素添加
LinkedHashMap并没有重写父类HashMap的put方法,而是重写了父类HashMap的put方法调用的子方法void recordAccess(HashMap m), void addEntry(int hash, K key, V value, int bucketIndex), void createEntry(int hash, K key, V value, int bucketIndex), 从而完成了LinkedHashMap自己特有的双向链表的实现。
accessOrder决定是是按访问顺序迭代,还是按照插入顺序迭代。默认顺序是false, 即按照插入顺序迭代。
当accessOrder为true时,是按照访问顺序迭代。这时,LinkedHashMap自己实现了个LRU算法,即当新插入元素时,如果继承自LinkedHashMap的融云的LRUHashMap的大小大于LRUHashMap允许的最大值,那么则删除LinkedHashMap中的head元素,即上例中的“语文:1”。
所以,融云自己实现的LRUHashMap是继承自LinkedHashMap, 并重写了removeEldestEntry方法:
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
boolean ret = size() > maxSize;
if (onEvict != null) {
onEvict.invoke(eldest.getKey(), eldest.getValue());
}
return ret;
}
这时,当向LRUHashMap即向LinkedHashMap中插入新元素时,如果removeEldestEntry返回为true, 那么,会自动调用HashMap的removeEntryForKey方法来删除LinkedHashMap的Head元素。通过这种机制,来实现LRUHashMap. 也就是说,LRUHashMap实际上的存储结构也就是LinkedHashMap, 即hash表(数组+链表+串起数组元素的双向链表)。
3. LinkedHashMap的关键属性
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
当插入元素时,从tail开始;当遍历时,从head开始。LinkedHashMap之所以使用双链表,是为了删除其中某个元素时,链表不会断。
那么,为什么单向链表删除单个元素时,链表不会断呢?这是因为单向链表在删除前,先要从一端开始依次查找该元素,这样很容易知道要删除元素的前一个和后一个元素,然后即可切换指针。但对于LinkedHashMap, 双向链表的元素查找,可通过Hash表hash的方式来查找,这样比依次查找链表元素性能要快得多,但坏处也就是无法知道这个链表节点的前一个元素,所以采用双向链表。
采用双向链表的另一个好处就是可以逆序遍历,不过需要自己实现。