由于我们的系统的商品数量众多,接近百万的SKU,所以某些搜索业务需求较难实现,而国外大型商家的合作数量逐渐增多,商品日益增加,长远考虑来看,考虑接入Elasticsearch搜索引擎。
设计难点:如何在无停机的状态下实现数据的全量&增量同步,还要保证数据的正确性和一致性?
系统原理:
Elasticsearch:一个基于Lucene的搜索引擎。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,具有近实时、可靠、开箱即用等特点。
通过获取MySQL的binlog日志,通过解析binlog,将解析后的数据推入消息队列中(我们选用kafka),在业务中建立kafka消费端,将数据存入ES。
获取binlog
Mysql为保证高可用、数据容灾备份等问题,存在一个二进制日志(binlog),在事务提交时一次性将事务中的sql按照一定格式记录到binlog中。
订阅binlog有两种方式,从争夺系统资源和耦合性来上说我们选择第二种:
- 在Mysql Server上通过外部程序监听binlog
- 伪装成Mysql的Master-Slaver服务器获得binlog日志。
这里有一个注意的点: MySQL 的 binlog 支持三种格式:Statement 、 Row 和 Mixed 格式:
- Statement 格式就是说日志中记录 Master 执行的 SQL
- Row 格式就是说每次讲更改的数据记录到日志中
- Mixed 格式就是让 Master 自主决定是使用 Row 还是 Statement 格式
我们一般将binlog日志格式设置为Row
配置方式:
[mysqld]
log-bin=mysql-bin #设置开启binlog日志
binlog-format=ROW #将binlog日志格式设为row
server_id=1 #表示从服务器ID,各个服务器id不能相同
解析binlog
目前由好多大厂开源的binlao解析工具
这里选用阿里开源的Canal项目。
Canal项目利用了MySQL数据库主从同步的原理,将Canal Server模拟成一台需要同步的从库,从而让主库将binlog日志流发送到Canal Server接口。Canal项目对binlog日志的解析进行了封装,我们可以直接得到解析后的数据,而不需要理会binlog的日志格式。而且Canal项目整合了zookeeper,整体实现了高可用,可伸缩性强,是一个不错的解决方案。
搜索架构图
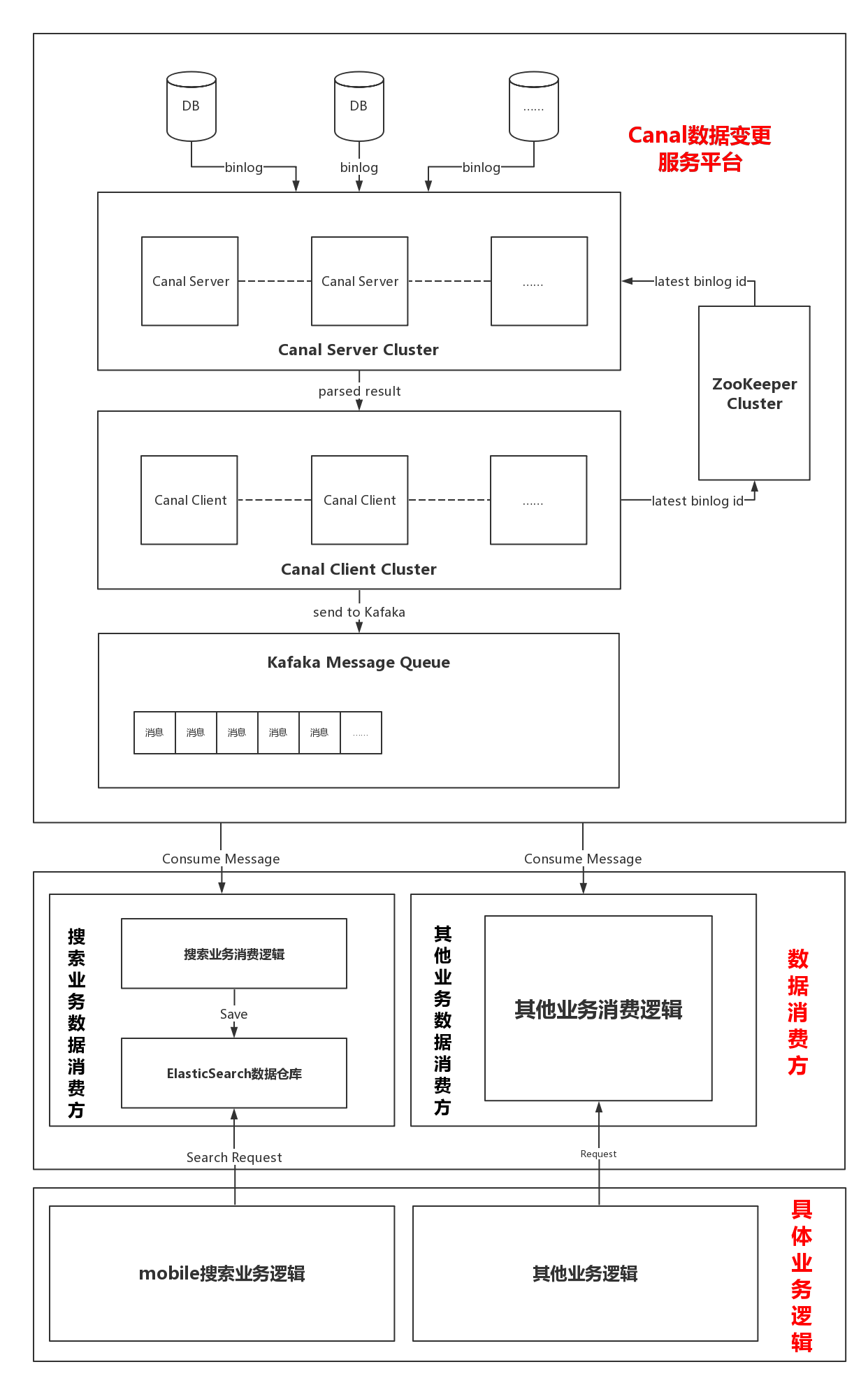
从架构图可以看出整个系统分为两大部分:
Canal数据变更服务平台。
这部分负责解析MySQL的binlog日志,并将其解析后的数据封装成特定的对象放到Kafka中。
配置文件中配置监控的表,重启即生效
- Canal Server端。Canal Server伪装成MySQL的一个从库,使主库发送binlog日志给 Canal Server,Canal Server 收到binlog消息之后进行解析,解析完成后将消息直接发送给Canal Client。在Canal Server端可以设置配置文件进行具体scheme(数据库)和table(数据库表)的筛选,从而实现动态地增加对数据库表的监视。
- Canal Client端。Canal Client端接收到Canal Server的消息后直接将消息存到Kafka指定Partition中。由于同步服务会重启,因此必须自行维护 binlog 的状态。当服务重启后,自动根据存储的 binlog 位置,继续同步数据。并将最新的binlogid发送给zookeeper集群保存。
Kafka数据消费方。
这部分负责消费存放在Kafka中的消息,当消费方拿到具体的用户表变更消息时,将最新的用户信息存放到ES数据仓库中。
数据分区策略:MySQL数据同步需要保证顺序,由于 Kafka 保证同一个 partition 保序,所以将一条数据的不同版本放入同一个partition 。
Kafka中数据按照Key来分区,同一个分区保证顺序。可在DB层面将某列设为主键,并将其设为kafka的key易于数据平衡与扩展。
公司已经封装了第一部分,所以我们的系统接入ES只需实现第二部分即可(kafka数据消费方)。
API:
ES客户端
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequestBuilder;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.aggregations.AggregationBuilder;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ExecutionException;
/**
* Created by mushuangcheng on 2018/7/30
*/
public class ESUtils {
static TransportClient client ;
public static void main(String[] args) throws ExecutionException, InterruptedException {
ElasticSearchClientFactory clientFactory=new ElasticSearchClientFactory();
clientFactory.initialize();
client = clientFactory.getClient();
//index();
// bulkOperator();
query();
// complexQuery();
}
/**
* 增加数据
* @throws ExecutionException
* @throws InterruptedException
*/
public static void index() throws ExecutionException, InterruptedException {
Map<String,Object> source=new HashMap<>();
source.put("name","小明");
source.put("age",18);
source.put("country","China haha");
IndexRequest indexRequest=new IndexRequest("person","student","1").source(source);
IndexResponse indexResponse = client.index(indexRequest).get();
System.out.println(indexRequest);
}
/**
* 更新
* @throws ExecutionException
* @throws InterruptedException
*/
public void update() throws ExecutionException, InterruptedException {
Map<String, Object> source=new HashMap<>();
source.put("name","小明明");
source.put("age",188);
source.put("country","China haha 哈哈");
UpdateRequest updateRequest=new UpdateRequest("person","student","1").doc(source).upsert(source);
UpdateResponse updateResponse = client.update(updateRequest).get();
System.out.println(updateRequest);
}
/*
删除
*/
public void delete() throws ExecutionException, InterruptedException {
DeleteRequest deleteRequest=new DeleteRequest("person","student","1");
DeleteResponse deleteResponse = client.delete(deleteRequest).get();
System.out.println(deleteRequest);
}
public static void bulkOperator() throws ExecutionException, InterruptedException {
BulkRequestBuilder bulkRequestBuilder = client.prepareBulk();
Map<String,Object> source=new HashMap<>();
source.put("name","小明");
source.put("age",18);
source.put("country","China haha");
IndexRequest indexRequest=new IndexRequest("person","student","1").source(source);
Map<String, Object> source2=new HashMap<>();
source2.put("name","小明明");
source2.put("age",188);
source2.put("country","China haha 哈哈");
UpdateRequest updateRequest=new UpdateRequest("person","student","1").doc(source2).upsert(source2);
Map<String, Object> source3=new HashMap<>();
source3.put("name","晓华");
source3.put("age",15);
source3.put("country","Amarecal haha 美国");
//DeleteRequest deleteRequest=new DeleteRequest("person","student","1");
UpdateRequest updateRequest1=new UpdateRequest("person","student","2").doc(source3).upsert(source3);
Map<String, Object> source4=new HashMap<>();
source4.put("name","单方");
source4.put("age",10);
source4.put("country","aesfas haha 大四");
//DeleteRequest deleteRequest=new DeleteRequest("person","student","1");
UpdateRequest updateRequest2=new UpdateRequest("person","student","3").doc(source4).upsert(source4);
BulkResponse bulkItemResponses = bulkRequestBuilder.add(indexRequest).add(updateRequest).add(updateRequest1).add(updateRequest2).get();
System.out.println(bulkItemResponses);
}
/**
* 简单查询
*/
public static void query(){
QueryBuilder termQb= QueryBuilders.matchQuery("country","haha");
QueryBuilder queryBuilder=QueryBuilders.boolQuery().should(termQb);
SearchRequestBuilder builder=client.prepareSearch("person").setTypes("student").setSize(10).setFrom(0).setQuery(queryBuilder);
SearchResponse searchResponse = builder.get();
System.out.println(searchResponse);
}
public static void complexQuery(){
QueryBuilder rangeQuery=QueryBuilders.rangeQuery("age").gte(10).lte(250);
QueryBuilder queryBuilder=QueryBuilders.boolQuery().must(rangeQuery);
AggregationBuilder aggregationBuilder= AggregationBuilders.terms("agg_hh").field("age")
.order(Terms.Order.aggregation("max_age",false)).size(10)
.subAggregation(AggregationBuilders.max("max_age").field("age"));
SearchRequestBuilder searchRequestBuilder=client.prepareSearch("person")
.setTypes("student").setFrom(0).setSize(10).setQuery(queryBuilder).addAggregation(aggregationBuilder);
SearchResponse searchResponse = searchRequestBuilder.get();
System.out.println(searchResponse);
}
}
import com.google.common.base.Preconditions;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Controller;
import javax.annotation.PostConstruct;
import java.net.InetAddress;
import java.util.Arrays;
import java.util.List;
/**
* Created by mushuangcheng on 2018/7/30
*/
@Controller("elasticSearchClientFactory")
public class ElasticSearchClientFactory {
private static Logger logger= LoggerFactory.getLogger(ElasticSearchClientFactory.class);
/**
* 集群名称
*/
@Value("${elasticSearch.clusterName}")
private String clusterName="elasticsearch";
/**
* 节点列表
*/
@Value("${elasticSearch.nodeList}")
private String nodeList="127.0.0.1:9300";
// 搜索客户端
private TransportClient client;
@PostConstruct
public void initialize() {
Preconditions.checkNotNull(clusterName);
List<String> nodeList = Arrays.asList(this.nodeList.split(","));
Preconditions.checkNotNull(nodeList);
Preconditions.checkArgument(nodeList.size() > 0);
client = initClient(clusterName, nodeList);
Thread shutdownThread = new Thread(this::close, "ElasticSearchShutdownHook");
shutdownThread.setPriority(Thread.MIN_PRIORITY);
Runtime.getRuntime().addShutdownHook(shutdownThread);
}
private TransportClient initClient(String name, List<String> nodes) {
try {
Settings settings = Settings.builder().put("cluster.name", name).put("client.transport.ping_timeout", "10s").put("transport.type","netty3")
.put("client.transport.sniff", false).build();
TransportClient client = new PreBuiltTransportClient(settings);
for (String node : nodes) {
String address;
int port;
try {
String[] temp = node.split(":");
address = temp[0];
port = Integer.parseInt(temp[1]);
logger.info("init elasticsearch client, address:{}, port:{}", address, port);
} catch (ArrayIndexOutOfBoundsException | NumberFormatException e) {
logger.info("init elasticsearch client node fail:{},{}", node, e);
continue;
}
client = client
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(address), port));
}
return client;
} catch (Exception e) {
logger.error("init elasticsearch client fail:{},{},{}", name, nodes, e);
return null;
}
}
public void close() {
if (client != null) {
client.close();
}
}
public TransportClient getClient() {
return this.client;
}Kafka消费端:
import com.netease.dts.common.subscribe.SubscribeEvent;
import com.netease.dts.common.subscribe.SubscribeEvent.OneRowChange;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
public class KafkaConsumerDemo {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerDemo.class);
private static final int HEART_BEAT_INTERVAL = 5000;
private volatile long lastPollTime = 0L;
private KafkaConsumer<Long, SubscribeEvent> consumer = null;
private ReentrantLock consumerLock = new ReentrantLock();
public void startSubscribe() throws InterruptedException {
String topic = "test_center_private-dts.Dashboard-add_by_nss_do_not_del_for_guoyi_newsrec";//kafka topic created by NDC
String brokerAddress = "hzadg-newsfeed-3.server.163.org:9092,hzadg-newsfeed-2.server.163.org:9092,hzadg-newsfeed-1.server.163.org:9092";//kafka broker address
String group = "News_info_article";//consumer group name
Properties props = new Properties();
props.put("bootstrap.servers", brokerAddress);
props.put("group.id", group);
props.put("enable.auto.commit", "false");//trun off autocommit
props.put("session.timeout.ms", "50000");
props.put("request.timeout.ms", "60000");
props.put("max.partition.fetch.bytes", "20000000");
props.put("auto.offset.reset", "earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.LongDeserializer");
props.put("value.deserializer", "com.netease.dts.sdk.KafkaSubscribeEventDeserializer");//NDC subscribe deserializer
try {
consumer = new KafkaConsumer<>(props);//create consumer
consumer.subscribe(Arrays.asList(topic));//subscribe topic
//Thread t = new Thread(new HeartBeatTask(), "kafka_heart_beat");
//t.start();
while(true) {
ConsumerRecords<Long, SubscribeEvent> records = null;
consumerLock.lockInterruptibly();
try {
records = consumer.poll(2000);
} finally {
consumerLock.unlock();
}
for (ConsumerRecord<Long, SubscribeEvent> record : records) {
System.out.println(record.value().getTimestamp());
for (OneRowChange orc : record.value().getRowChanges()) {
if (orc.getTableName().equals("app_toutiao_article")) {
if (orc.getColumnChanges().get(0).equals(1098110813)) {
logger.info(record.toString());
System.out.println(record.toString());
}
logger.info(orc.getColumnChanges().get(0).toString());
System.out.println(orc.getColumnChanges().get(0).toString());
}
}
//System.out.println(record.offset());
}
consumerLock.lockInterruptibly();
try {
//consumer.commitSync();//commit offset manually
} finally {
consumerLock.unlock();
}
}
} finally {
if (consumer != null)
consumer.close();
}
}
class HeartBeatTask implements Runnable {
@Override
public void run() {
lastPollTime = System.currentTimeMillis();
while (!Thread.interrupted()) {
try {
if (System.currentTimeMillis() - lastPollTime > HEART_BEAT_INTERVAL) {
consumerLock.lockInterruptibly();
try {
Set<TopicPartition> partitionSet = consumer.assignment();
consumer.pause(partitionSet.toArray(new TopicPartition[]{}));
consumer.poll(0L);
lastPollTime = System.currentTimeMillis();
partitionSet = consumer.assignment();
consumer.resume(partitionSet.toArray(new TopicPartition[]{}));
} catch(Exception e) {
logger.error("Heartbeat task fail to touch broker", e);
} finally {
consumerLock.unlock();
}
}
TimeUnit.MILLISECONDS.sleep(HEART_BEAT_INTERVAL);
} catch (InterruptedException e) {
logger.info("Heartbeat task interrupeted");
}
}
}
}
public static void main(String[] args) throws InterruptedException {
KafkaConsumerDemo demo = new KafkaConsumerDemo();
demo.startSubscribe();
}
}
参考文章:
https://www.jianshu.com/p/be3f62d4dce0