MVC在界面开发中被奉为设计的典范,在移动开发中也是
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写。
它将业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。
我刚接触ios,想通过ios的一些实例设计来理解MVC在ios中的应用。
1. IOS的view
对于工具化的图形界面设计,这个就应该是各种视图控件的设计,页面和控件的大小、位置、边框、颜色(前景、背景)、字体、title等属性的设置。
对于定制化的图形界面,仍然需要代码来设计页面和控件的大小、位置、边框、颜色(前景、背景)、字体、titile等属性。
UIView是ios视图设计中,最基本的一个类。里面很多属性需要定义。
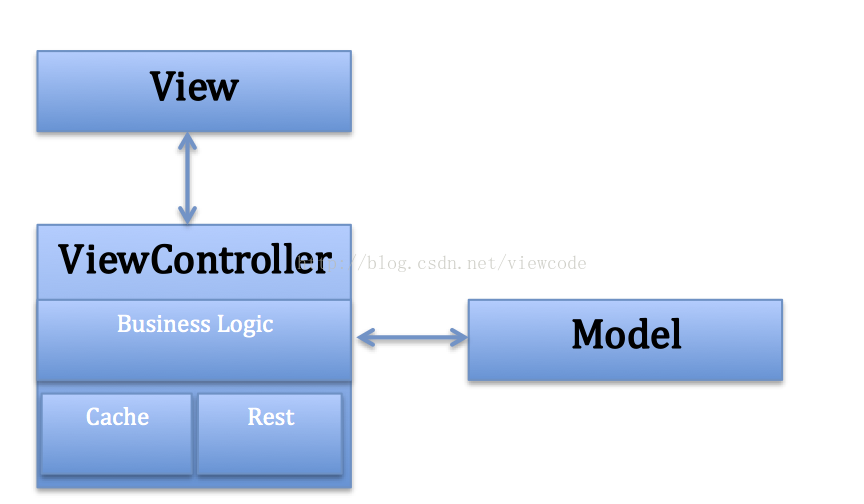
与view紧密关联的数据就是viewcontroller了,view的刷新和输入提交都是通过controller来完成。
controller对view拥有控制权,简单来说,一个controller拥有访问其view实体的权利。
controller会拥有哪些权利? 这就是controller与view不同的地方,代码相分离的地方。
2. iOS的controller
controller面对view的功能有:
能显示的修改view中的关联变量,驱动view的刷新。
能保存view中的关联变量,驱动model数据在服务端或cache的更新。
为实现一个完整的feature:
controller一般还拥有一些功能,如:
1. 逻辑处理、数据处理、错误处理等等
2. 与其他controller的交互
3. 访问server
4. 访问数据库
由以上功能来看,controller还能再分几层, 如逻辑层,cache层,server api call层(如rest)。
3. ios的Model
1. 协议内,只有一个主体业务对象,以及其他业务无关的属性
2. 每个对象根据路径,可以有子对象和反向引用的父对象,对于通过不同路径都能拿到属性,选取路径最短的方式给出
3. 对单个对象的response,协议内使用此对象作为主体,对于list的response,协议内使用list的父对象作为主体
4. 尽量采用OO方式引用,避免复制重复字段出现
5. 采取拉平的方式给出对象,组合的方式,而不是继承的方式。可能继承是server比较容易处理的方式,而前段可能针对不同平台,组合是最好的方式
===============================
当一个项目进行到一半,到中后期时,被另外一个项目复用时,该如何处理sdk 底层 code base:
两种方案:
1. 两个sdk底层实现的项目,利用同一个代码库(分支),但对于逻辑层进行严格分离,不能复用,杜绝逻辑层善变带来的重构烦恼,对于DAO和REST层次,可以复用一些公共的模块。
对于一些公共的数据模型,还是可以复用的。
缺点:上层在使用底层代码时,容易混淆数据模型。
2. 在当前code base上,新建项目代码库。
优点:数据模型独立,代码可以随意修改。
缺点:工作量加大。