深度学习500问
References
01. 数学基础
02. 机器学习基础
-
ROC曲线
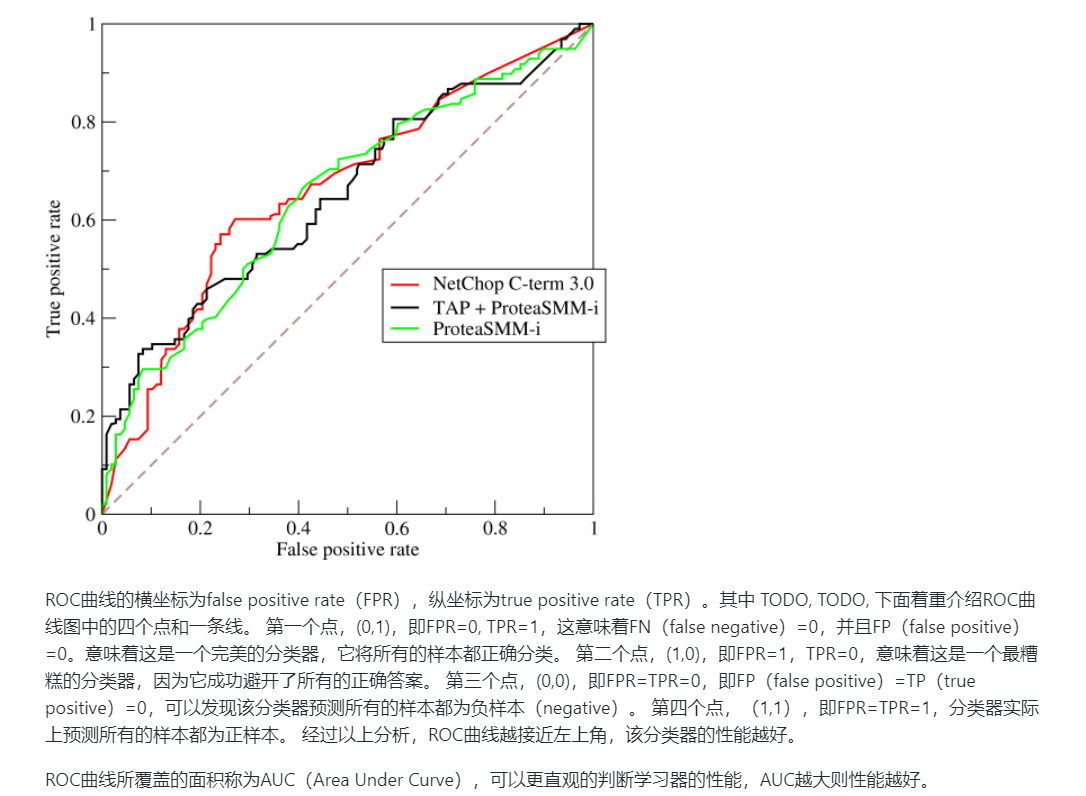
-
SVM(support vector machine)
参考1:https://blog.csdn.net/Love_wanling/article/details/69390047
参考2:https://blog.csdn.net/wsj998689aa/article/details/47027365
核函数非线性的牛逼之处:高维空间中向量的内积等于原空间中向量之间的核函数值。
优点:
(1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射; (2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心; (3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。
(4)SVM 是一种有坚实理论基础的新颖的小样本学习方法。它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题。
(5)SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。 (6)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。这种“鲁棒”性主要体现在: ①增、删非支持向量样本对模型没有影响; ②支持向量样本集具有一定的鲁棒性; ③有些成功的应用中,SVM 方法对核的选取不敏感
不足
(1) SVM算法对大规模训练样本难以实施 由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的 CSVM以及O.L.Mangasarian等的SOR算法。
(2) 用SVM解决多分类问题存在困难经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
- GBDT和随机森林的区别
GBDT和随机森林的相同点:
- 都是由多棵树组成
- 最终的结果都是由多棵树一起决定
GBDT和随机森林的不同点:
- 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只由回归树组成
- 组成随机森林的树可以并行生成;而GBDT只能是串行生成
- 对于最终的输出结果而言,随机森林采用多数投票等;而GBDT则是将所有结果累加起来,或者加权累加起来
- 随机森林对异常值不敏感,GBDT对异常值非常敏感
- 随机森林对训练集一视同仁,GBDT是基于权值的弱分类器的集成
- 随机森林是通过减少模型方差提高性能,GBDT是通过减少模型偏差提高性能
03. 深度学习基础
- 激活函数的性质
- 非线性
- 可微性
- 单调性
- 输出值的范围
- f(x) = x :当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值。
04. 经典网络
05. 卷积神经网络
06. 循环神经网络
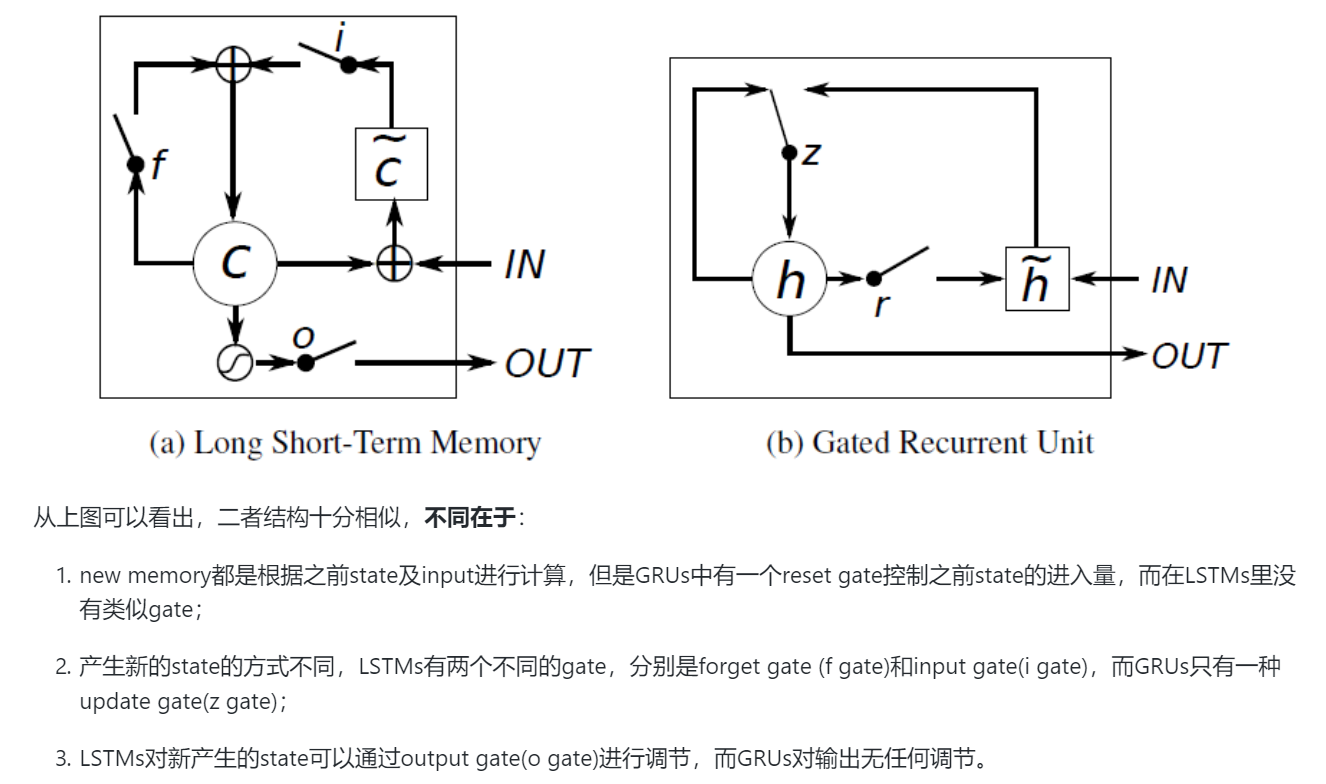
07. 生成对抗网络
- GAN是什么
GAN由生成器和判别器组成,生成器负责生成样本,判别器负责判断生成器生成的样本是否为真。生成器要尽可能迷惑判别器,而判别器要尽可能区分生成器生成的样本和真实样本。
在GAN的原作1中,作者将生成器比喻为印假钞票的犯罪分子,判别器则类比为警察。犯罪分子努力让钞票看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。
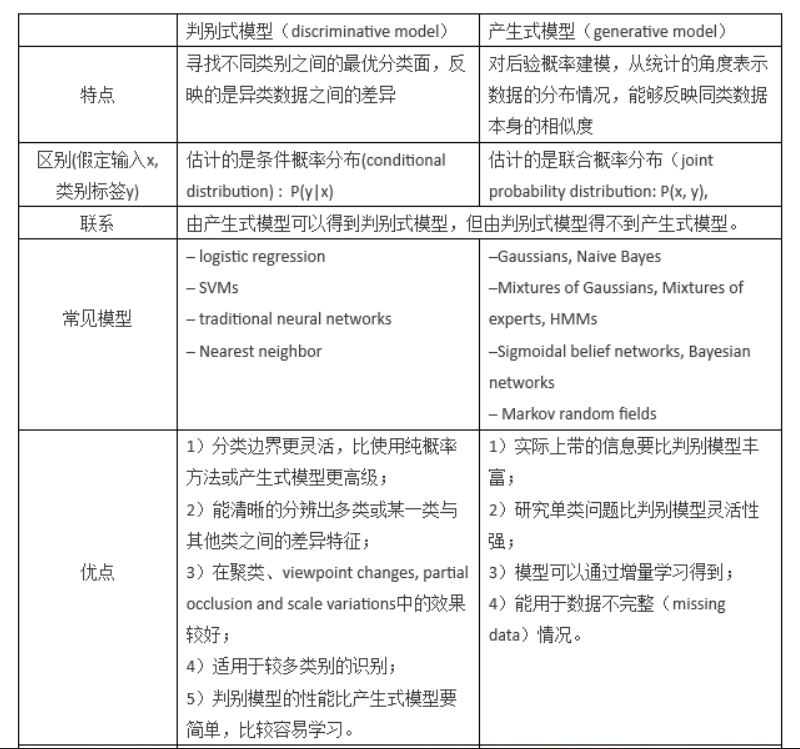
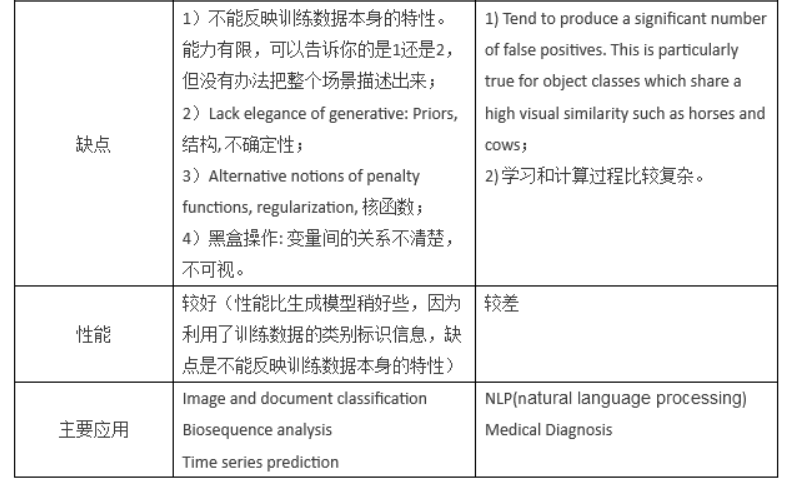
08. 目标检测
- 目标检测要解决的核心问题
除了图像分类之外,目标检测要解决的核心问题是:
- 目标可能出现在图像的任何位置。
- 目标有各种不同的大小。
- 目标可能有各种不同的形状。
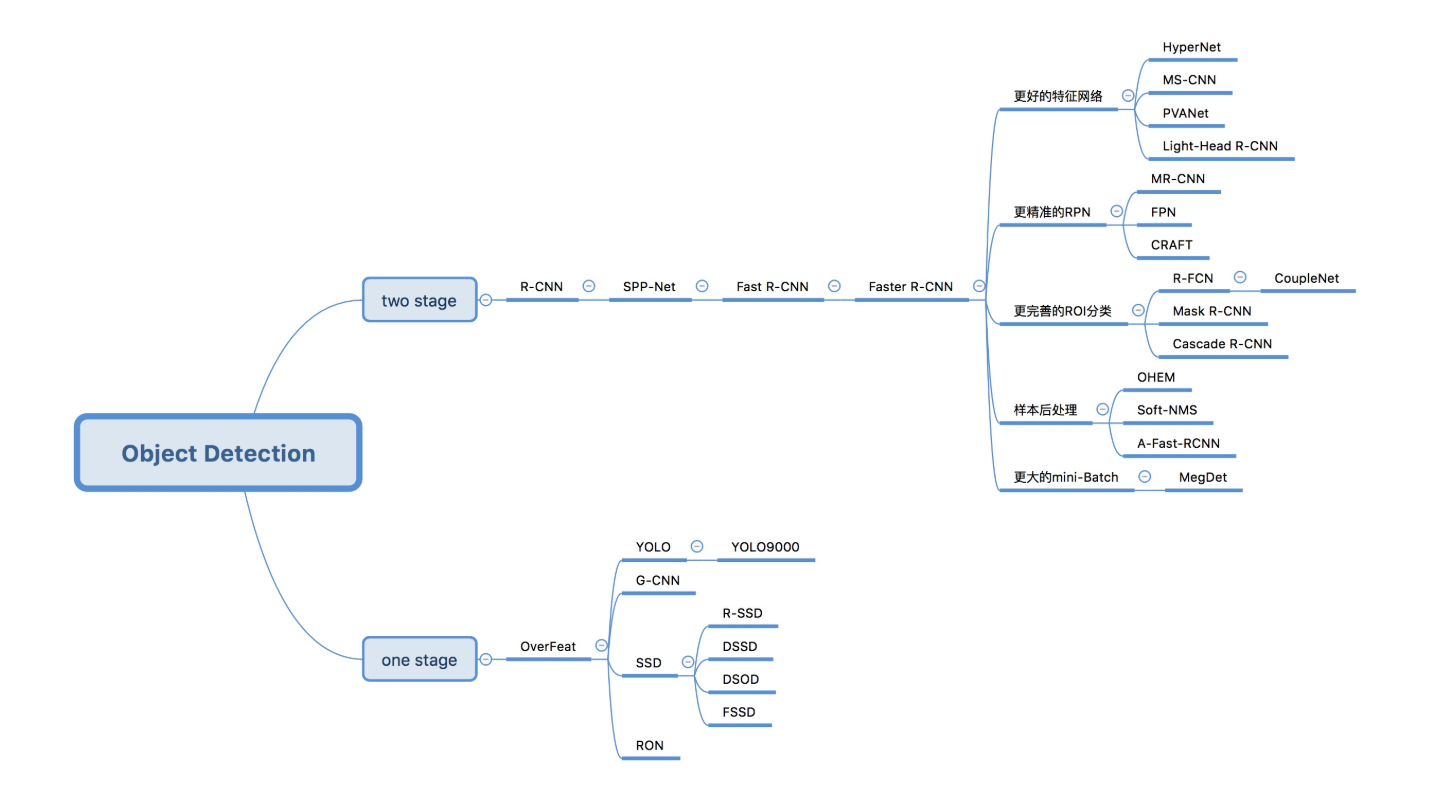
1. Two-Stage 目标检测算法
1. R-CNN (AlexNet)
- 创新点:
- 使用CNN(ConvNet)对 region proposals 计算 feature vectors。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
- 采用大样本下(ILSVRC)有监督预训练和小样本(PASCAL)微调(fine-tuning)的方法解决小样本难以训练甚至过拟合等问题。
-
流程图
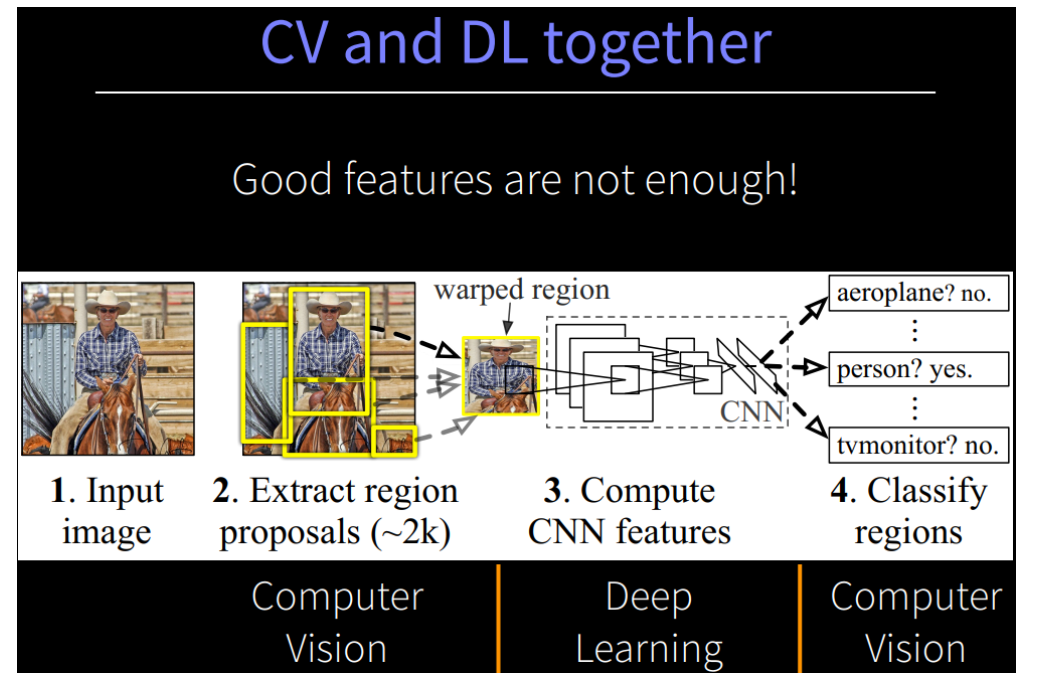
-
MAP:58.5%
2. Fast R-CNN (AlexNet)
- 创新点
- 只对整幅图像进行一次特征提取,避免R-CNN中的冗余特征提取
- 用RoI pooling层替换最后一层的max pooling层,同时引入建议框数据,提取相应建议框特征
- Fast R-CNN网络末尾采用并行的不同的全连接层,可同时输出分类结果和窗口回归结果,实现了end-to-end的多任务训练【建议框提取除外】,也不需要额外的特征存储空间【R-CNN中的特征需要保持到本地,来供SVM和Bounding-box regression进行训练】
- 采用SVD对Fast R-CNN网络末尾并行的全连接层进行分解,减少计算复杂度,加快检测速度。
-
流程图
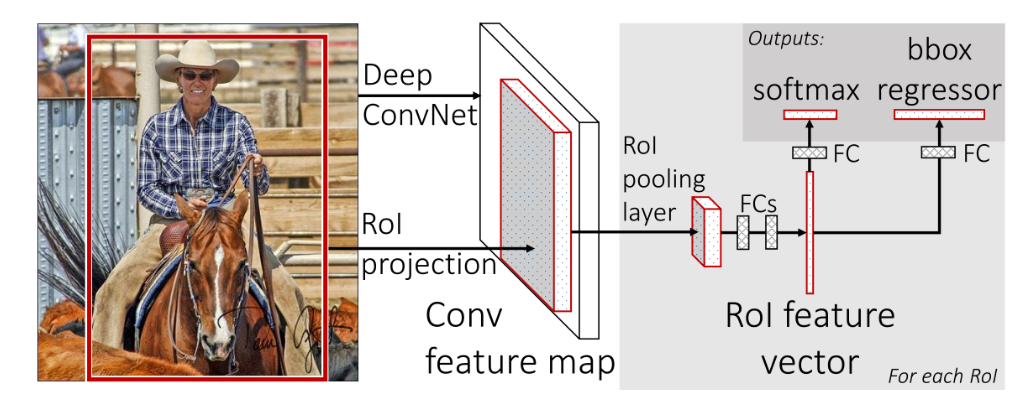
-
在测试中,Fast R-CNN需要2.3秒来进行预测,其中2秒用于生成2000个ROI。
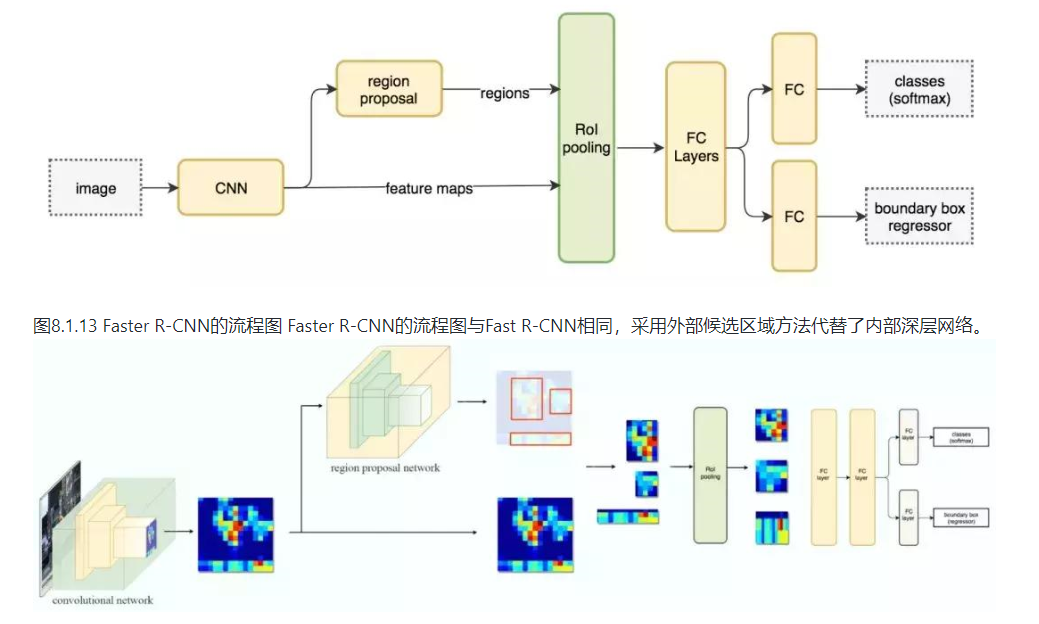
3. Faster R-CNN (ZF-NeT)
- 创新点
Faster R-CNN采用与Fast R-CNN相同的设计,只是它用内部深层网络代替了候选区域方法。新的候选区域网络(RPN)在生成ROI时效率更高,并且以每幅图像10毫秒的速度运行。 - 流程图
4. R-FCN (ResNet)
- 创新点
- Fully convolutional
- 位置敏感得分图(position-sentive score maps)
our region-based detector is fully convolutional with almost all computation shared on the entire image. To achieve this goal, we propose position-sensitive score maps to address a dilemma between translation-invariance in image classification and translation-variance in object detection.
-
流程图
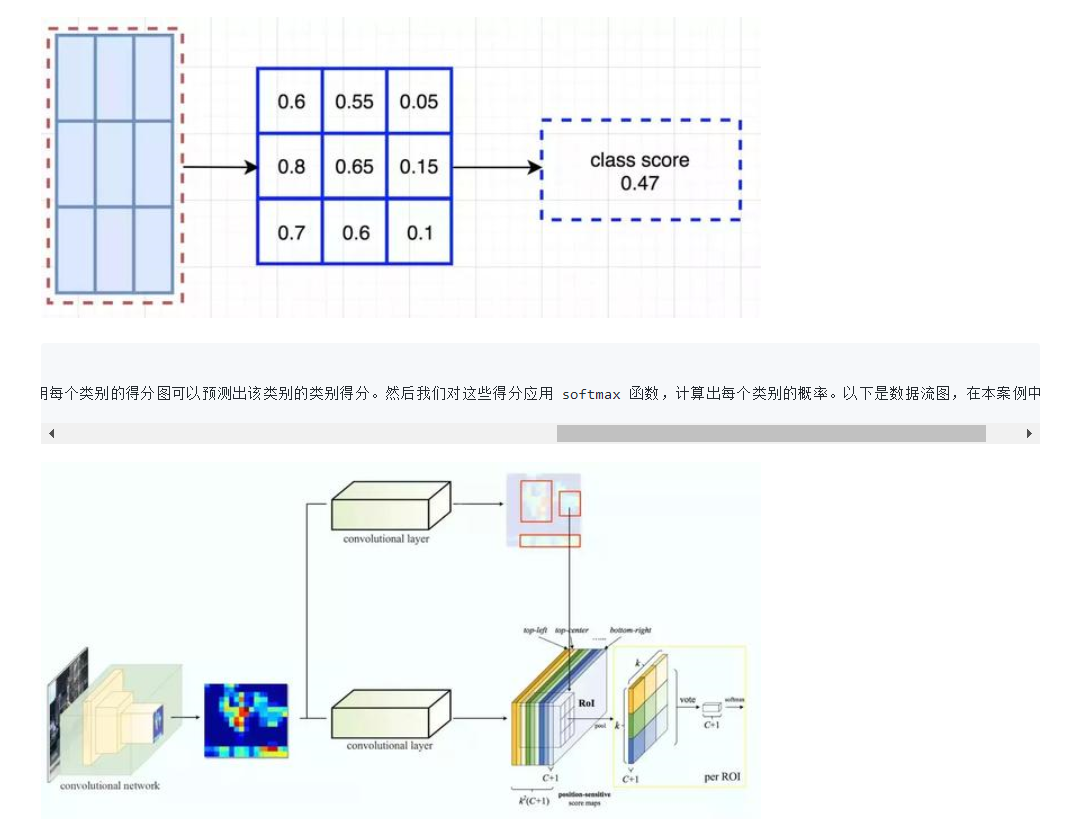
-
ResNet-101+R-FCN:83.6% in PASCAL VOC 2007 test datasets, 既提高了mAP,又加快了检测速度.
2. One-Stage 目标检测算法
1. SSD(VGG-16)
- 创新点
- SSD使用 VGG16 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样),将后面的全连接层替换成卷积层,并在之后添加自定义卷积层,并在最后直接采用卷积进行检测。
- 在多个特征图上设置不同缩放比例和不同宽高比的default boxes(先验框)以融合多尺度特征图进行检测,靠前的大尺度特征图可以捕捉到小物体的信息,而靠后的小尺度特征图能捕捉到大物体的信息,从而提高检测的准确性和定位的准确性。原文对于300x300的输入,分别在conv4_3, conv7,conv8_2,conv9_2,conv10_2,conv11_2的特征图上的每个单元取4,6,6,6,4,4个default box. 由于以上特征图的大小分别是38x38,19x19,10x10,5x5,3x3,1x1,所以一共得到38x38x4+19x19x6+10x10x6+5x5x6+ 3x3x4+1x1x4=8732个default box.对一张300x300的图片输入网络将会针对这8732个default box预测8732个边界框。
- 流程图
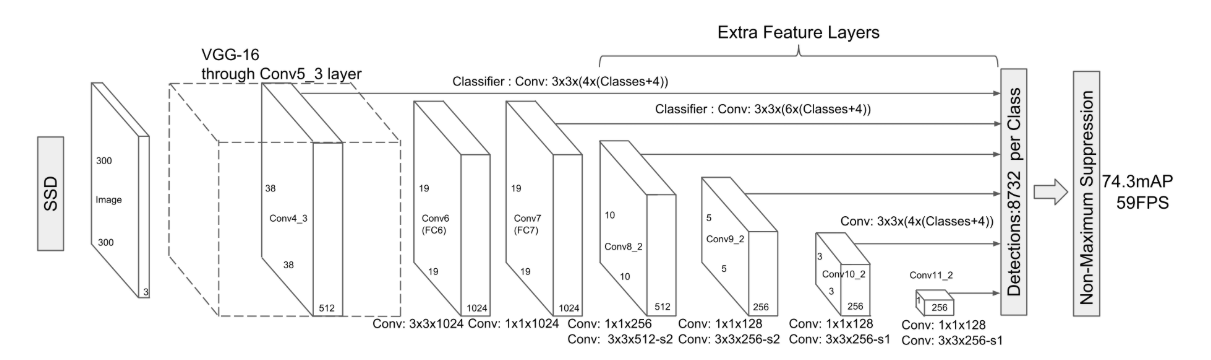
- 74.3 MAP, 59FPS
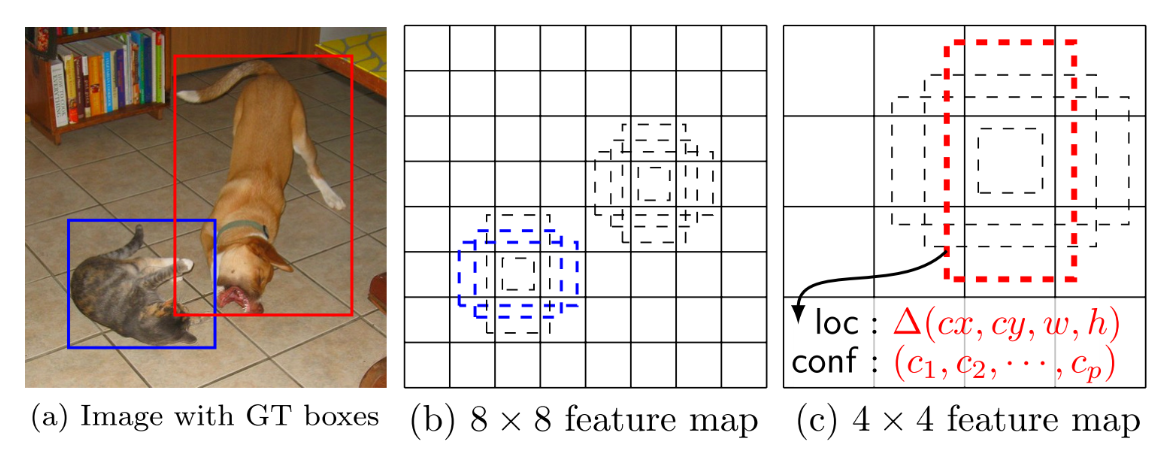
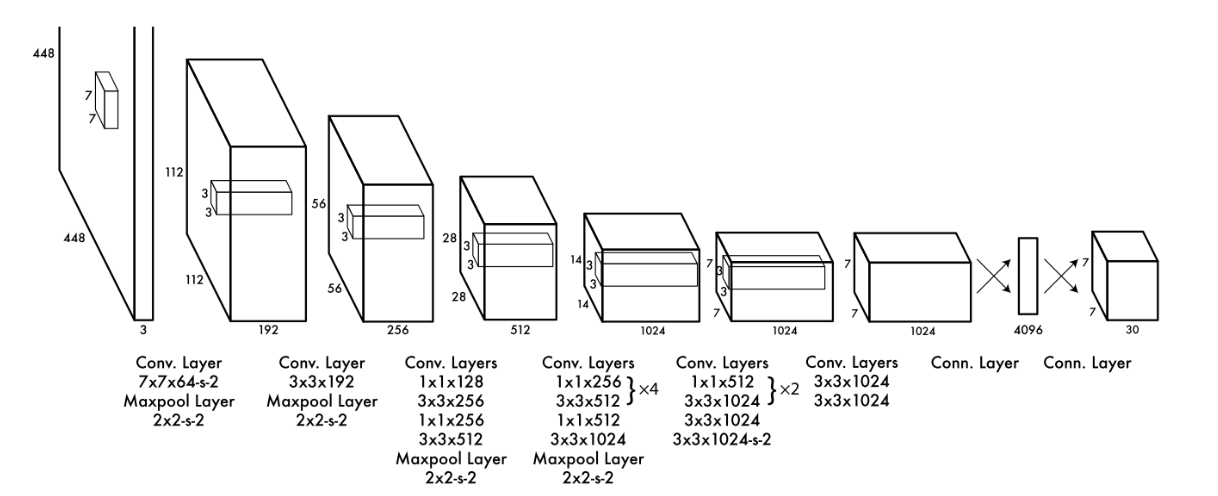
2. YOLO v1(Google Net)
- 创新点
- One-Stage 的开山之作:YOLO创造性的将物体检测任务直接当作回归问题(regression problem)来处理,将候选区和检测两个阶段合二为一。
- 事实上,YOLO也并没有真正的去掉候选区,而是直接将输入图片划分成7x7=49个网格,每个网格预测两个边界框,一共预测49x2=98个边界框。可以近似理解为在输入图片上粗略的选取98个候选区,这98个候选区覆盖了图片的整个区域,进而用回归预测这98个候选框对应的边界框。
- 流程图
3. YOLO v2(DarkNet-19)
-
创新点

-
流程图
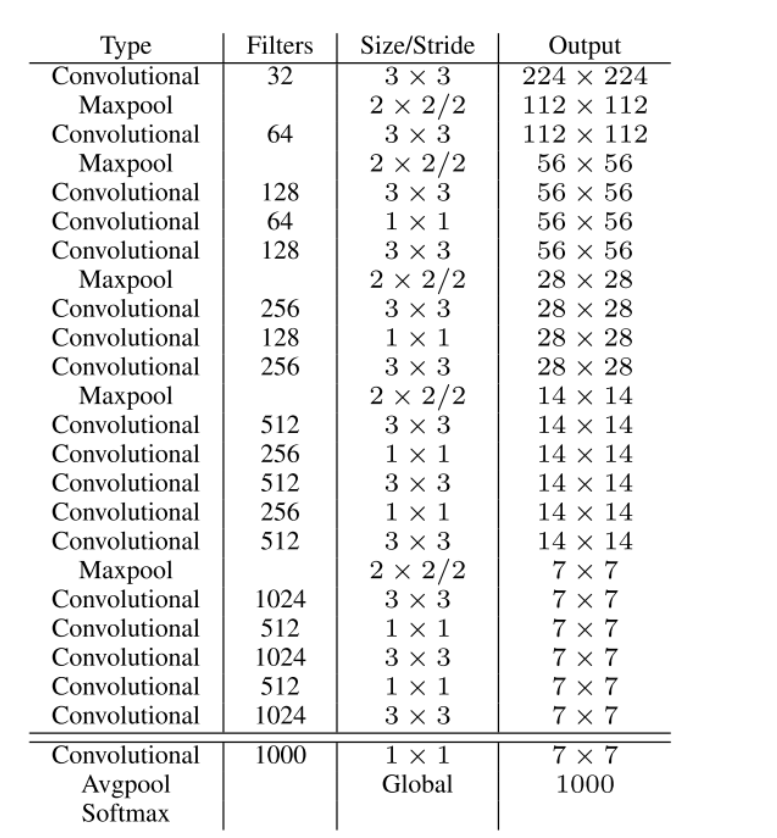
4. YOLO v3
- 创新点
- 一个是使用残差模型,进一步加深了网络结构;
- 另一个是使用FPN架构实现多尺度检测
-
流程图
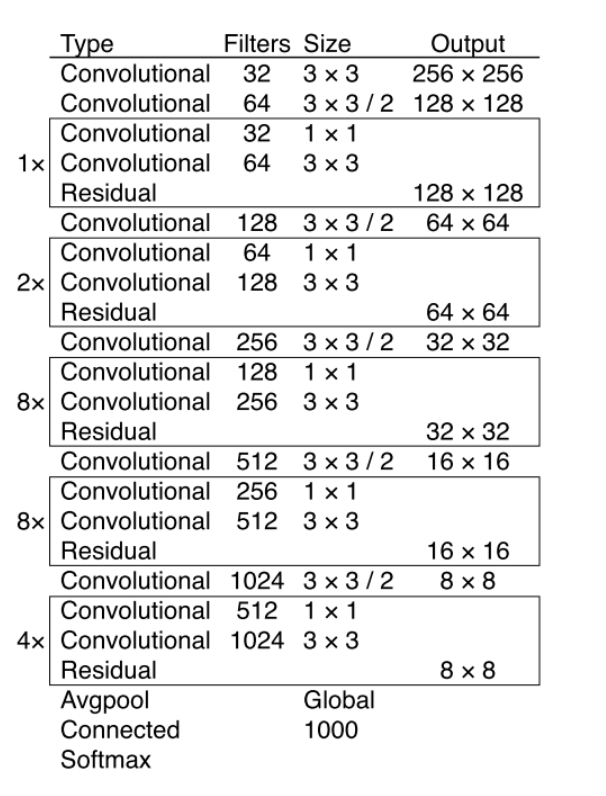
-
从YOLOv1到YOLOv2再到YOLO9000、YOLOv3, YOLO经历三代变革,在保持速度优势的同时,不断改进网络结构,同时汲取其它优秀的目标检测算法的各种trick,先后引入anchor box机制、引入FPN实现多尺度检测等。
4. RetinaNet
- 创新点

2. 样本的类别不均衡会带来什么问题?
简单来说,因为bbox数量爆炸。 正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
-
为什么在two-stage检测器中,没有出现类别不均衡(class imbalamce)问题呢?
因为通过RPN阶段可以减少候选目标区域,而在分类阶段,可以固定前景与背景比值(foreground-to-background ratio)为1:3,或者使用OHEM(online hard example mining)使得前景和背景的数量达到均衡。 -
均衡交叉熵函数


3. 人脸识别
- 基于级联卷积神经网络的人脸检测(Cascade CNN)
- 基于多任务卷积神经网络的人脸检测(MTCNN)
- Facebox
09. 图像分割
1. FCN
-
流程图
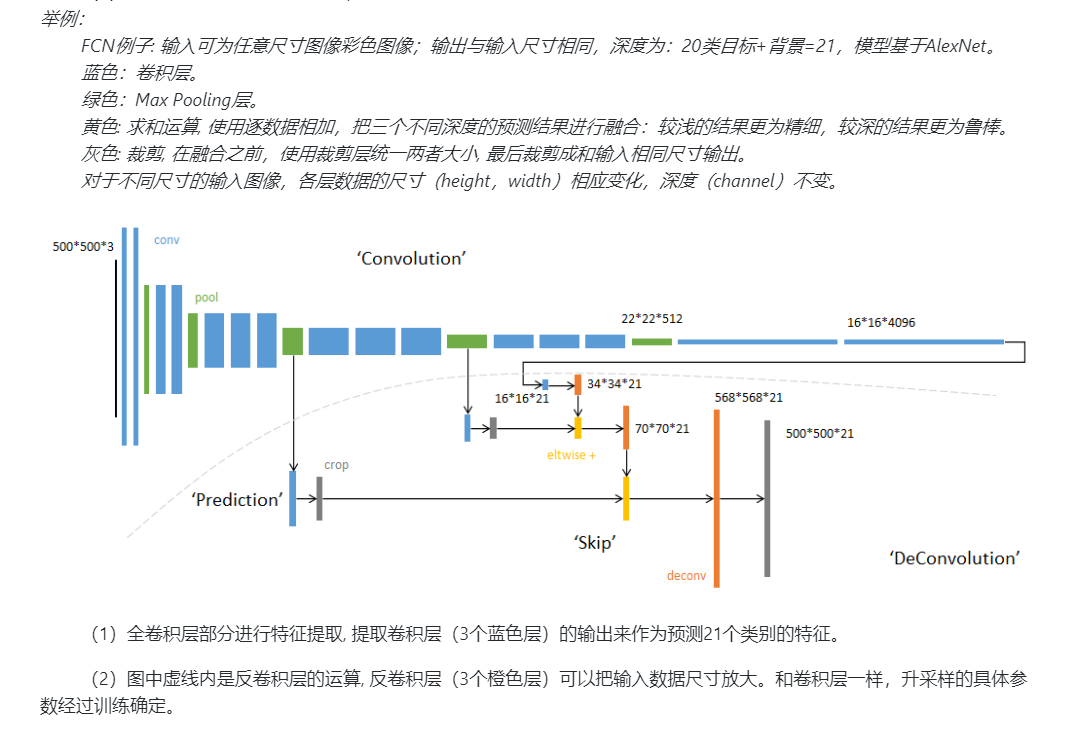
-
缺点
- 得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
- 对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
2. U-NET
-
流程图
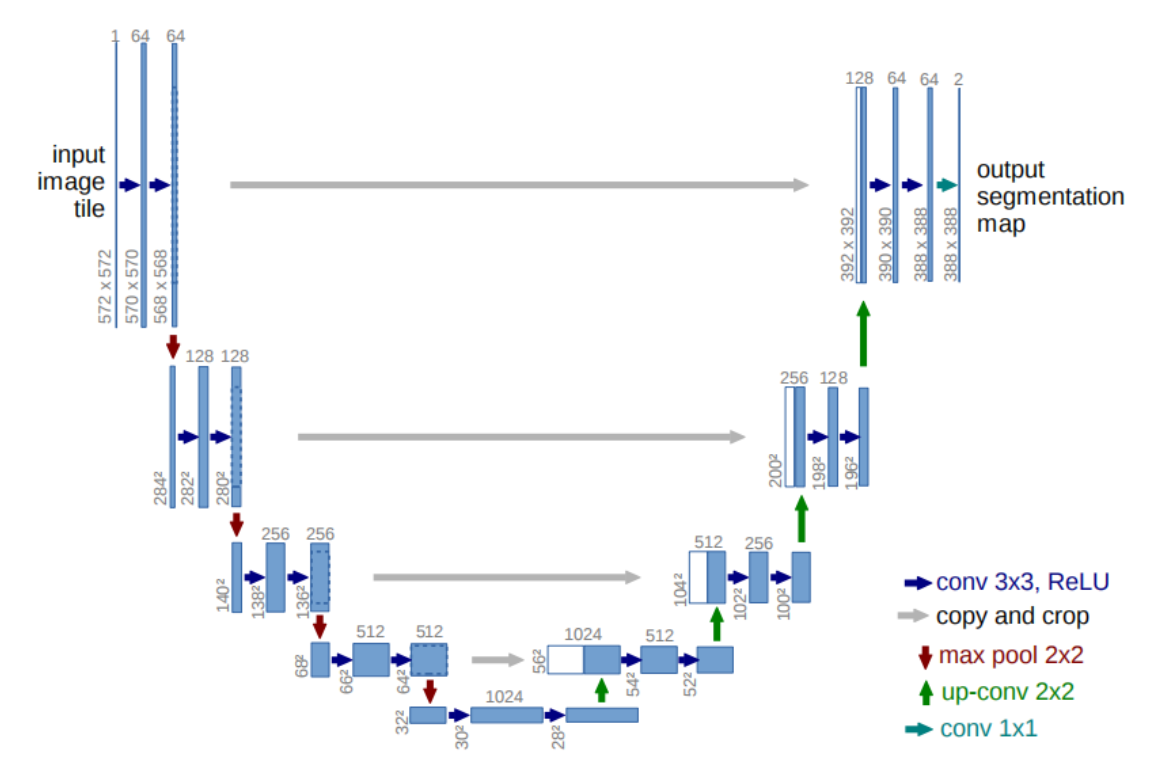
-
创新点
- 使用全卷积神经网络。(全卷积神经网络就是卷积取代了全连接层,全连接层必须固定图像大小而卷积不用,所以这个策略使得,你可以输入任意尺寸的图片,而且输出也是图片,所以这是一个端到端的网络。)
- 左边的网络是收缩路径:使用卷积和maxpooling。
- 右边的网络是扩张路径:使用上采样产生的特征图与左侧收缩路径对应层产生的特征图进行concatenate操作。(pooling层会丢失图像信息和降低图像分辨率且是不可逆的操作,对图像分割任务有一些影响,对图像分类任务的影响不大,为什么要做上采样?因为上采样可以补足一些图片的信息,但是信息补充的肯定不完全,所以还需要与左边的分辨率比较高的图片相连接起来(直接复制过来再裁剪到与上采样图片一样大小),这就相当于在高分辨率和更抽象特征当中做一个折衷,因为随着卷积次数增多,提取的特征也更加有效,更加抽象,上采样的图片是经历多次卷积后的图片,肯定是比较高效和抽象的图片,然后把它与左边不怎么抽象但更高分辨率的特征图片进行连接)。
- 最后再经过两次反卷积操作,生成特征图,再用两个1X1的卷积做分类得到最后的两张heatmap,例如第一张表示的是第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax类,选择它作为输入给交叉熵进行反向传播训练。
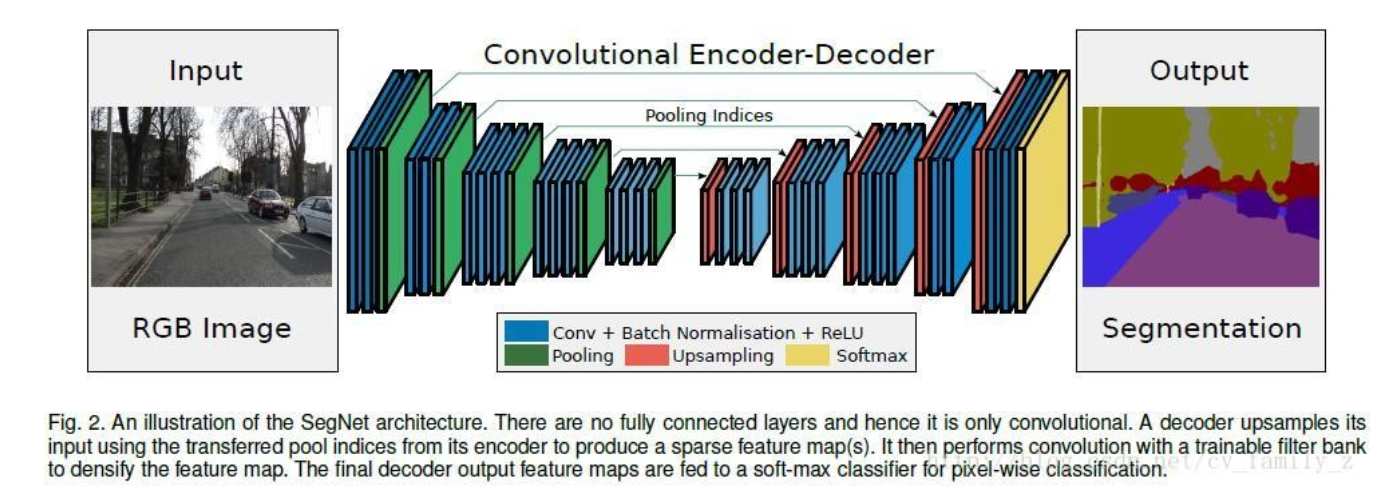
3. SegNet
- 流程图
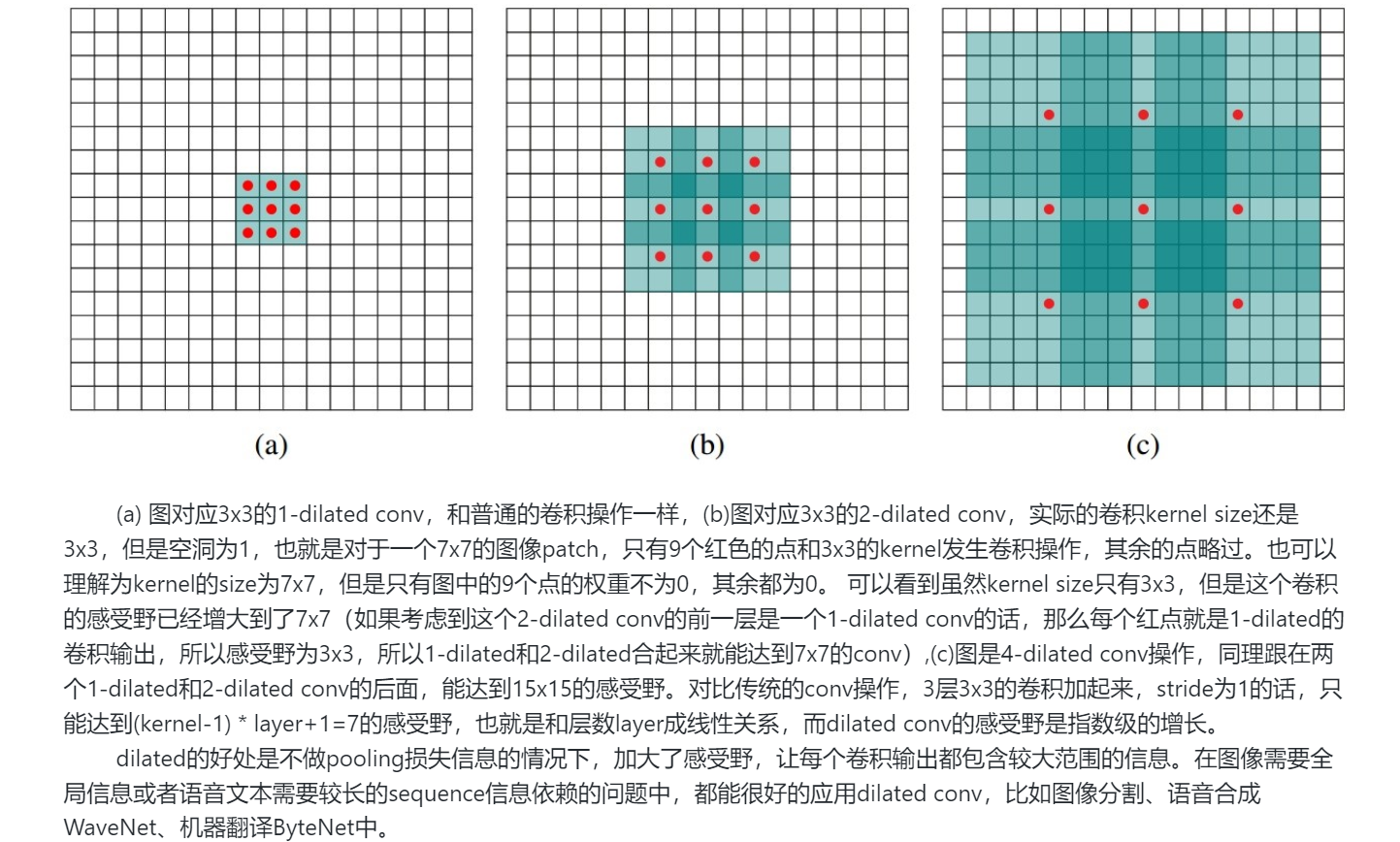
4. 空洞卷积
10. 强化学习
机器学习可以分成三部分:监督学习、无监督学习、强化学习。
11. 迁移学习
- 什么是迁移学习?
迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
- 为什么需要迁移学习?
- 大数据与少标注的矛盾
- 大数据与弱计算的矛盾
- 普适化模型与个性化需求的矛盾
- 特定应用(零启动)的需求
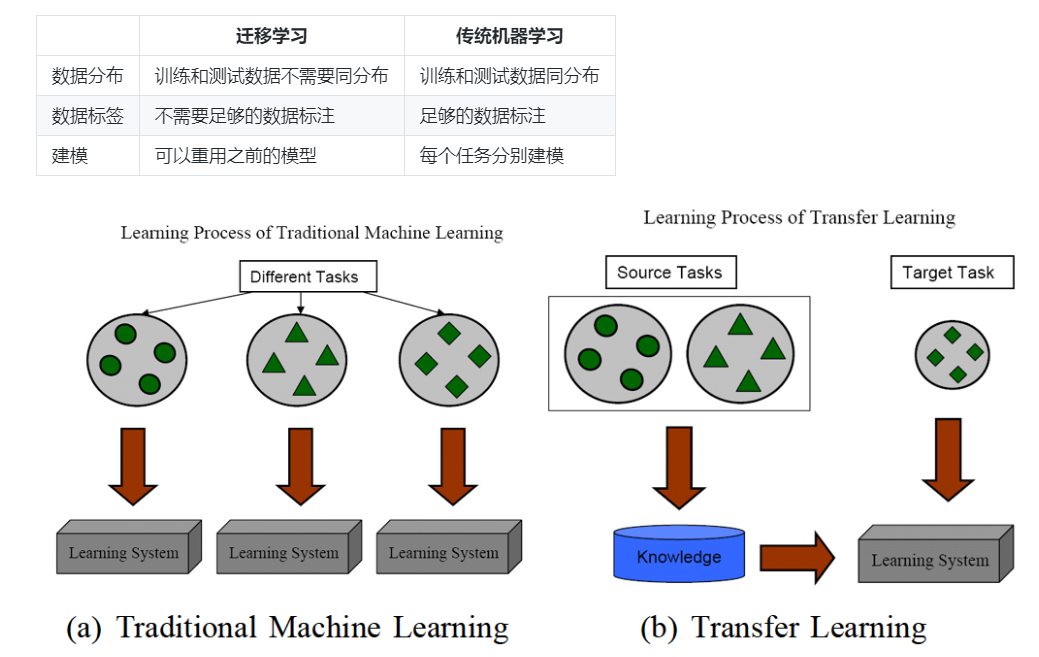
- 迁移学习和传统机器学习的区别?
12. 网络搭建及训练
参考:
- 深度学习 - 模型训练技巧:https://blog.csdn.net/u012968002/article/details/72122965
- 深度学习基础之-梯度弥散和梯度爆炸及解决办法:https://blog.csdn.net/u013403054/article/details/78424095
- 深度学习模型训练痛点及解决方法:https://yq.aliyun.com/articles/598429?utm_content=m_51302
- 深度学习中Dropout原理解析:https://zhuanlan.zhihu.com/p/38200980
1. 训练痛点及解决办法:
- 收敛速度慢:
- 设置合理的w和b
- 优化学习率
- BN
- 采用更先进的网络结构,减少参数量
- 使用GPU并行计算
- 线性模型的局限性:
- 激活函数的使用
- 两个小卷积核的叠加代替一个大卷积核
- 1*1 小卷积核的使用
- 过拟合问题:
- 输入增强,增大样本量
- drop out
- 正则化
- 梯度弥散,无法使用更深的网络
- ReLu
- 残差网络
2. TensorFlow, PyTorch, Caffe
参考:https://github.com/scutan90/DeepLearning-500-questions/blob/master/ch12_网络搭建及训练/第十二章_网络搭建及训练.md
PyTorch 和 TensorFlow 具有不同计算图实现形式,TensorFlow 采用静态图机制(预定义后再使用),PyTorch采用动态图机制(运行时动态定义)。
13. 优化算法
-
贝叶斯错误率:贝叶斯错误率是应用贝叶斯分类规则的分类器的错误率。贝叶斯分类规则的一个性质是:在最小化分类错误率上是最优的。1所以在分类问题中,贝叶斯错误率是一个分类器对某个类别所能达到的最低的分类错误率。
-
误差分析
实际上,如果你观察 个错误标记的开发集样本,也许只需要 到 分钟的时间,亲自看看这 个样本,并亲自统计一下有多少是狗。根据结果,看看有没有占到 、 或者其他东西。这个在 到 分钟之内就能给你估计这个方向有多少价值,并且可以帮助你做出更好的决定,是不是把未来几个月的时间投入到解决错误标记的狗图这个问题。
所以总结一下,进行错误分析,你应该找一组错误样本,可能在你的开发集里或者测试集里,观察错误标记的样本,看看假阳性(false positives)和假阴性(false negatives),统计属于不同错误类型的错误数量。在这个过程中,你可能会得到启发,归纳出新的错误类型,就像我们看到的那样。如果你过了一遍错误样本,然后说,天,有这么多Instagram滤镜或Snapchat滤镜,这些滤镜干扰了我的分类器,你就可以在途中新建一个错误类型。总之,通过统计不同错误标记类型占总数的百分比,可以帮你发现哪些问题需要优先解决,或者给你构思新优化方向的灵感。 -
为什么值得花时间查看错误标记数据:
其次,不知道为什么,我看一些工程师和研究人员不愿意亲自去看这些样本,也许做这些事情很无聊,坐下来看100或几百个样本来统计错误数量,但我经常亲自这么做。当我带领一个机器学习团队时,我想知道它所犯的错误,我会亲自去看看这些数据,尝试和一部分错误作斗争。我想就因为花了这几分钟,或者几个小时去亲自统计数据,真的可以帮你找到需要优先处理的任务,我发现花时间亲自检查数据非常值得,所以我强烈建议你们这样做,如果你在搭建你的机器学习系统的话,然后你想确定应该优先尝试哪些想法,或者哪些方向。 -
快速搭建初始系统的意义
它可以是一个快速和粗糙的实现(quick and dirty implementation),你知道的,别想太多。初始系统的全部意义在于,有一个学习过的系统,有一个训练过的系统,让你确定偏差方差的范围,就可以知道下一步应该优先做什么,让你能够进行错误分析,可以观察一些错误,然后想出所有能走的方向,哪些是实际上最有希望的方向。
14. 超参数调整
- 神经网络包含的超参数
- 网络参数:网络层与层之间的交互方式(相加、相乘、串接)、卷积核的数量和尺寸、网络层数(深度)和激活函数
- 优化参数:学习率、批样本数量、不同优化器的参数和部分损失函数的可调参数
- 正则化:权重衰减系数、drop out
- 如何改善GAN的性能?
(1)优化GAN性能通常需要在如下几个方面进行:
- 设计或选择更适合目的代价函数。
- 添加额外的惩罚。
- 避免判别器过度自信和生成器过度拟合。
- 更好的优化模型的方法。
- 添加标签明确优化目标。
(2)GAN常用训练技巧 - 输入规范化到(-1,1)之间,最后一层的激活函数使用tanh(BEGAN除外)
- 使用wassertein GAN的损失函数,
- 如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
- 使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
- 避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用leakrelu激活函数
- 优化器尽量选择ADAM,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率, * 给D的网络层增加高斯噪声,相当于是一种正则
15. 异构运算, GPU和框架选型指南
-
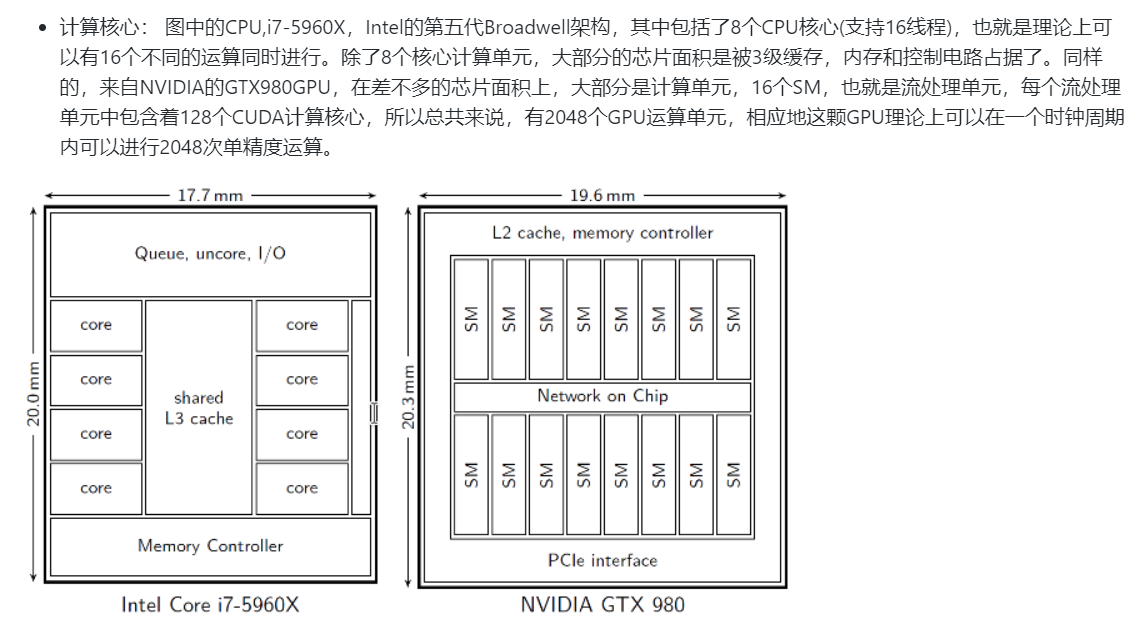
GPU和CPU
CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。
-
为什么要使用GPU
- 并行指令:也就是多个指令可以同时分配到不同的计算核心上同时进行,而他们的操作是不同的,并且他们之间相互独立,不需要额外的同步和信息共享。(不同的地方同时做不同的事情)
- 并行数据流:如果数据本身存在的天然的独立性,比如图像中的每一个像素,那么在对这个图像做处理的过程中,同一个指令可以同时作用于每一个像素。在这种情况下,这个对于完整图像的操作可以并行化。理论上,如果内存不是问题,并且计算单元的数量大于整个图像中总像素点的话,这个操作可以在一个时钟周期内完成。(不同地方同时做相同的事)
基于深度学习中大部分的操作的天然并行性(大量的矩阵操作),GPU在当下还是一种非常适合的计算平台。
- GPU主要性能指标
- 计算能力。通常我们关心的是32位浮点计算能力。16位浮点训练也开始流行,如果只做预测的话也可以用8位整数
- 显存大小。当模型越大,或者训练时的批量越大时,所需要的GPU显存就越多
- 显存带宽。只有当显存带宽足够时才能充分发挥计算能力
- GPU、CUDA、CuDNN
参考:https://blog.csdn.net/u014380165/article/details/77340765
- GPU:图像处理器,多用于处理并行任务:并行指令/并行数据流
- CUDA:CUDA是NVIDIA推出的用于自家GPU的并行计算框架
- CuDNN:是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
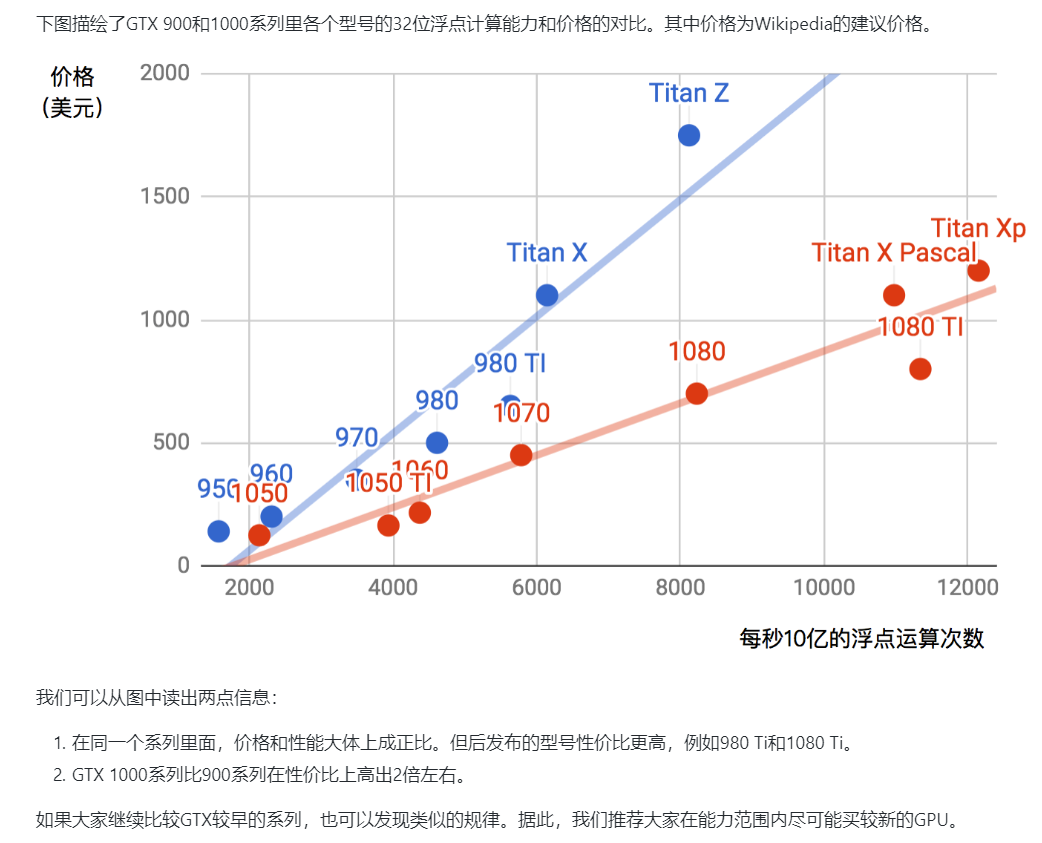

17. 模型压缩、加速及移动端部署
- 为什么需要模型压缩和加速?
- 随着AI技术的飞速发展,越来越多的公司希望在自己的移动端产品中注入AI能力
- 对于在线学习和增量学习等实时应用而言,如何减少含有大量层级及结点的大型神经网络所需要的内存和计算量显得极为重要。
- 智能设备的流行提供了内存、CPU、能耗和宽带等资源,使得深度学习模型部署在智能移动设备上变得可行。
- 高效的深度学习方法可以有效的帮助嵌入式设备、分布式系统完成复杂工作,在移动端部署深度学习有很重要的意义。
18. 后端架构选型、离线及实时运算
如需转载请注明出处, 谢谢!