A股上市公司营收预测
前言
这是我第一次写博客,也是第一次用 Markdown编辑器。主要用于记录项目思路和笔记吧,不足之处还请指正
这篇估计要写几天,因为一边看机器学习的书,这几天会一点一点写完
背景
在金融领域,每24小时都会产生大约2.5亿字节的数据,早已超过人脑处理的极限,面对全球百万亿美元的资产管理规模,行业迫切需要人工智能的加入,提升行业运行效率,让投资变得更加智能
这个题目是天池大赛的题目,看了大佬们的答辩视频的笔录,因为看不懂公式,所以只做了个乞丐版。
实现了简单线性预测,用到三种方法:
- 神经网络测出重要变量
- 决策树调整自变量能控制因变量(其实还是不太理解)
- 线性回归预测营收
人员介绍
四个人
数据理解
财务数据和营业收入是成相关的
Q1季报
S1半年报
Q3前三季
A全年
一般来说,把单个季度作为单位预测回更加准确一些
复赛大佬的PPT截图: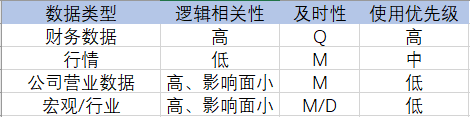
数据准备
翻译利润表的变量名(吃了文化亏)
表需要转成xlsx才能导入spss
字典里面多了5个变量,删除了这些变量:
数据来源 公告id 实际纰漏时间 会计准则 货币代码
某大佬说空值填0,这样不会影响内在的等式关系。不过最后没有填0,因为删去了很多变量
通过spss statistisc的自动线性建模分析出影响到营业收入的10个变量
工商利润表

银行

保险

证券

建模(乱建的模)
负责建模组员的原话
建模流程:
理解问题–>数据的处理–>数据挖掘的执行–>分析影响公司营业收入的因素–>取出个别公司进行营收预测
开始实施:
这次的建模主要使用到了3个模型,一个是类神经网络,主要用了预测变量的重要性和一个走势,二是决策树,决策树也是可以预测变量和影响营业收入的因素,给公司提供一个合理的改进计划,三是时间序列,用于预测下一年的营业收入,和一个季度涨幅走势

分区是用于每一只股的分类,来进行一个训练和培养,最后对训练出来的模型进行一个分析
类神经网络
将目标设置为营业收入
把不影响营业收入的变量剔除出来
在神经网络看来归属于母公司所有者或股东的净利润是对营业收入最重要
可以看出营业收入和自变量属于一个正相关的关系




CART决策树



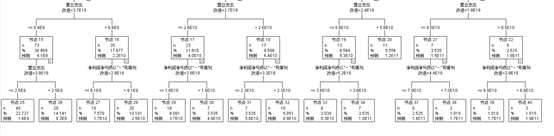

业务及管理费用<=6.e10有92.9%是盈利的
营业支出<=2.1e10有74.7%盈利的
业务及管理费用>6.e10有7.01%是亏损的
可以知道CART决策树可以,给公司的收入提出一个合理的改进计划,改变公司的营业收入
时间序列
选择日期,选择时间间隔 季度

选择要输出的模型,图表
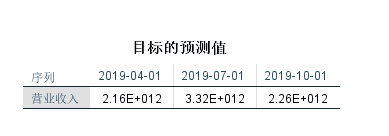
可以预测出根据之前的一个年份预测出2019年的Q1 Q3的一个走势可以看得出2019的的营业收入会比之前的都高


预测出的未来值,因为有个大量的数据,而且报告类型,都是季度的,若要让数值的准确度更加高,我们将取两只股会到下面的评估进来一个细致的预测