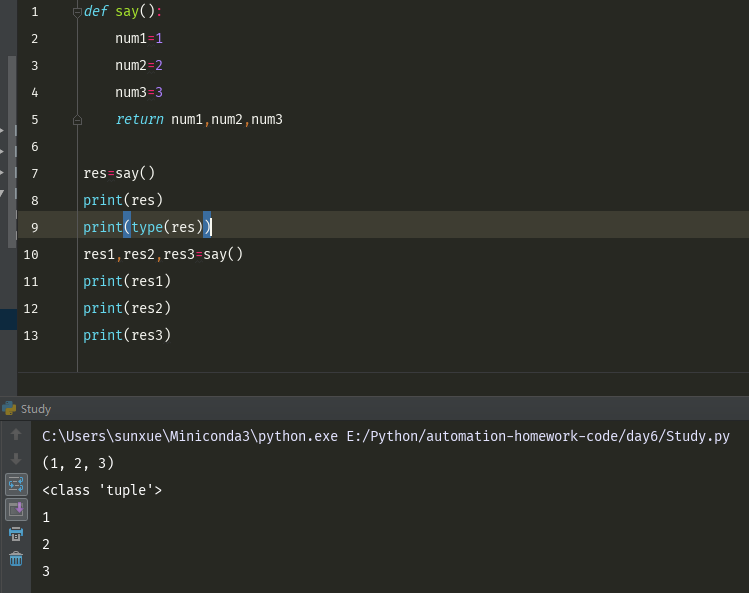
函数也可以return多个值
这返回的多个值,保存在元祖当中
也可以用多个变量接收函数的返回值
当用多个变量接收这个函数的返回值的时候,会分别将这几个值放到这几个变量中
def say(): num1=1 num2=2 num3=3 return num1,num2,num3 res=say() print(res) print(type(res)) res1,res2,res3=say() print(res1) print(res2) print(res3)
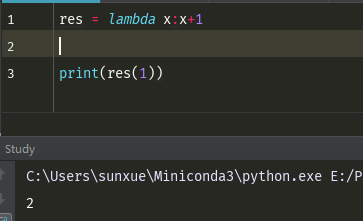
匿名函数:函数只用一次就不在使用了
lambda,后面跟变量,然后跟对变量简单的操作
lambda res = lambda x:x+1 #冒号后面的是函数体,也是函数的处理逻辑,冒号前面的返回值 print(res(1))
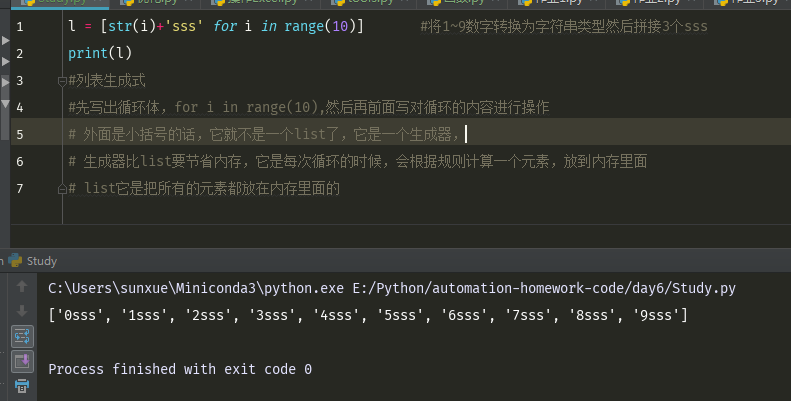
列表生成式
外面是小括号的话,它就不是一个list了,它是一个生成器,
生成器比list要节省内存,它是每次循环的时候,会根据规则计算一个元素,放到内存里面
list它是把所有的元素都放在内存里面的
三元运算符
简化代码的判断逻辑
a = 5 b = 4 if a > b: #如果a大于b c = a #c=a else: #否则 c = b #c=b #跟下面的结果一样 c = a if a > b else b # 如果a大于b的话,c=a,否则c =b ,如果不用三元运算符的话,就得上面这么写
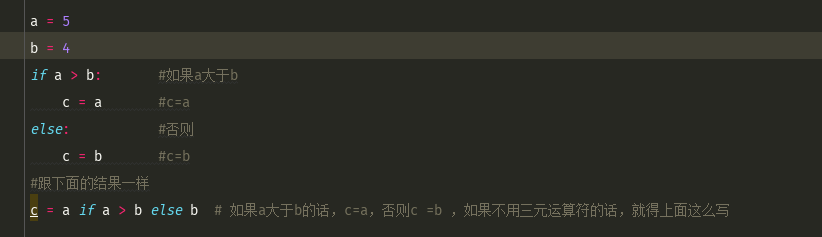
字典排序
#字典是无序,直接对字典排序是不存在的。
sort,会自动循环调用,还会将数据进行排序
先取到d.items的二维数组,然后将输入传给lambda,然后取二维数组每个元素的第一个值,进行排序
d = {'a':8,'b':2,'c':3}
#字典是无序,直接对字典排序是不存在的。
print(d.items())
res = sorted(d.items(),key=lambda x:x[0]) #根据key排序的话为x[0],根据value排序的话则为x[0]
res1 = sorted(d.items(),key=lambda x:x[1]) #根据key排序的话为x[0],根据value排序的话则为x[1]
#sort,会自动循环调用,还会将数据进行排序
print(res)
print(res1)
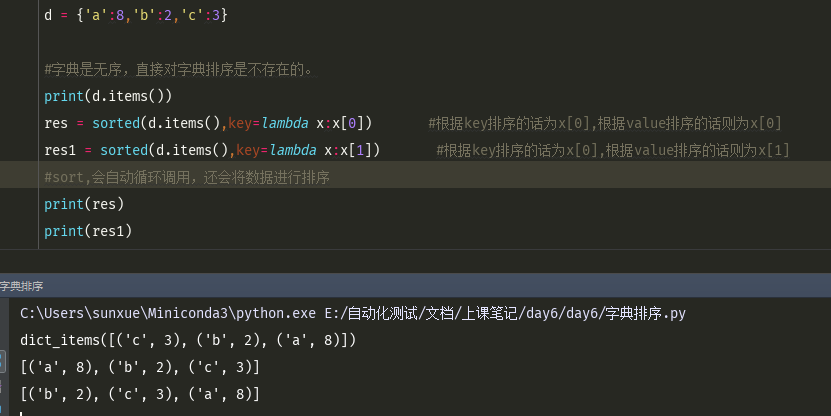
循环一个list 的时候,可以传多个值,然后对多个值进行循环
l = [ [1,2,3,4], [1,2,3,4], [1,2,3,4], [1,2,3,4], [1,2,3,4] ] for a,b,c,d in l: #循环一个list 的时候,可以传多个值,然后对多个值进行循环 print(d)
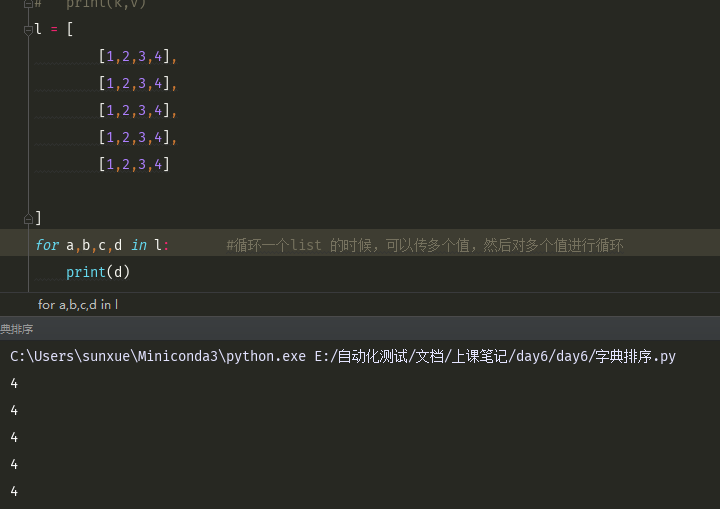
常用模块
OS模块
import os #对操作系统的操作 #print(os.getcwd()) #获取当前目录 #os.chmod("/user/local",7) #给文件、目录加权限,在linux下使用 # print(os.chdir("../day3")) #更改当前目录 # print(os.getcwd()) #获取当前目录 # print(os.makedirs("test1/2")) #递归创建文件夹,父目录不存在的时候,会创建父目录 # print(os.mkdir("test2/1")) #创建文件夹,父目录不存在的时候,会报错 # print(os.rmdir("test1/2")) #删除指定的文件夹(空目录) # print(os.removedirs("test1/2")) #递归删除空目录 # print(os.remove("test1")) #删除文件,不能删除文件夹 重要 # print(os.listdir("e:\\")) #列出一个目录下的所有文件 重要 # print(os.stat("函数.py")) #获取文件信息 # print(os.sep) #当前操作系统路径系统的分隔符 # print(os.linesep) #当前操作系统的的换行符 # print(os.pathsep()) #当前系统的环境变量中每个路径的分隔符是什么 # print(os.environ) #获取当前系统的环境变量 # print(os.name) #当前系统名称, windows系统都是nt,linux都是posix # os.system('ipconfig') #执行操作系统命令,但是获取不到结果 # res = os.popen('ipconfig').read() #可以获取到命令执行的结果 # print(res) # print(__file__) #获取到当前文件的绝对路径 # print(os.path.abspath('.')) #h获取绝对路径 # print(os.path.abspath(__file__)) #h获取绝对路径 # print(os.path.split("/user/hhe/hhe.txt")) #分割路径跟文件名 # print(os.path.split(os.path.abspath(__file__))) #分割路径跟文件名 # print(os.path.dirname("e:\\syz\\dat")) #获取父目录,获取上一级目录 # print(os.path.basename("e:\\Python\\firth.py")) #获取最后一集,如果是文件,显示文件目录名 # print(os.path.exists("E:\Python\firth.py")) #判断目录文件是否存在 # print(os.path.isabs("../day5")) #判断是否是绝对路径 # print(os.path.isfile("函数.py")) #判断是否是一个文件,1、文件要存在2、必须是一个文件 # print(os.path.isdir("../day5")) #判断是否是一个路径,这个路径是否存在 # size = os.path.getsize('函数.py') #获取文件的大小 # print(size) # print(os.path.join("root","hhe","a.sql")) #拼接成一个路径 # for path,dir,file in os.walk(r'E:\Python\automation-homework-code\day6'): #对文件夹进行循环,找到所有的文件,文件夹 # print(path,dir,file) #path当前循环的绝对路径 #dir目录下面所有的文件夹 #file目录下面所有的文件
主要记住如下方法
SYS模块
sys.argv # 命令行参数List,第一个元素是程序本身路径 sys.exit(n) #退出程序,正常退出时exit(0) sys.version #获取Python解释程序的版本信息 sys.maxint #最大的Int值 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform # 返回操作系统平台名称 sys.stdout.write('please:') #向屏幕输出一句话 val = sys.stdin.readline()[:-1] #获取输入的值
python导入模块的时候的顺序:
1、从当前目录下找需要导入的python文件
2、从python的环境变量中找 sys.path
如果在当前目录下找不到的话,就直接去环境变量中找,且顺序是从头到尾的
导入模块的实质:
就是这这个python文件从头到尾执行一遍
如下,创建一个Brunce1.py的py文件
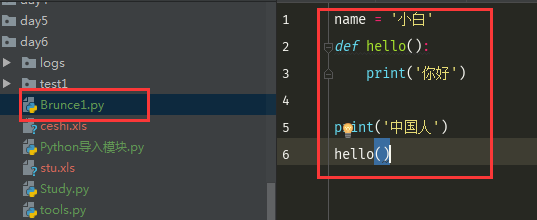
然后再导入执行
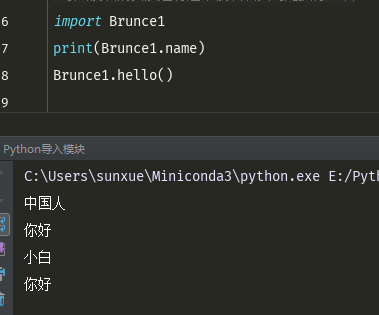
#导入其他路径下面的模块的话,
#先将路径加入到环境变量中,然后再导入模块
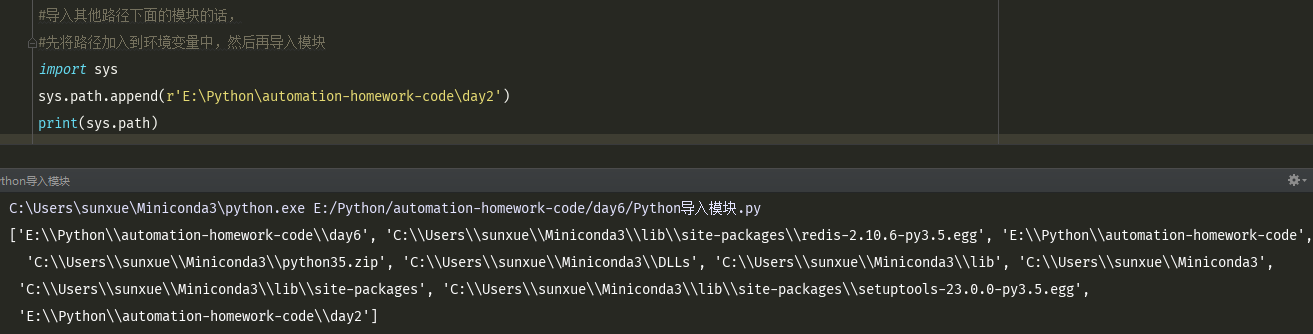
sys.path.append(r'E:\syz\ly-code\day5') #在末尾增加 sys.path.insert(0,r'E:\syz\ly-code\day5') #在list文件最前位置增加,这样遍历的时候会第一个找到,加快执行效率


print(sys.argv) #用来获取命令行里边运行的Python文件的时候传入的参数
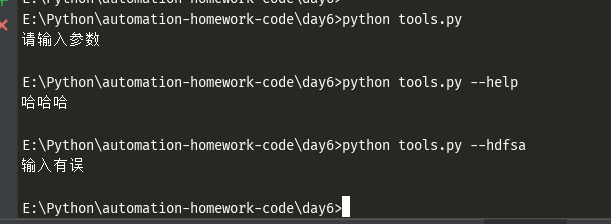
如下,在tools.py 中有如下脚本
import sys command = sys.argv #获取传入的参数,保存到一个list中 if len(command)>1: #如果list长度大于1,则包含一个参数 if command[1]=='--help': #如果输入的第二个值,也就是后面带的参数为--help print('哈哈哈') #则输出哈哈哈三个字 else: print('输入有误') ##否则输出输入有误 else: print('请输入参数') #如果没输入参数,则输出请输入参数
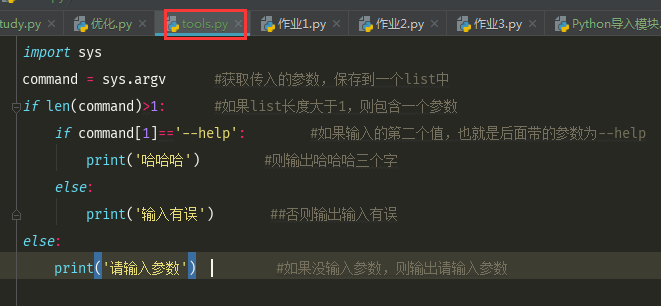
然后再命令行中进行操作,用Python命令执行这个脚本,先cd进入到对应的文件目录
如下:
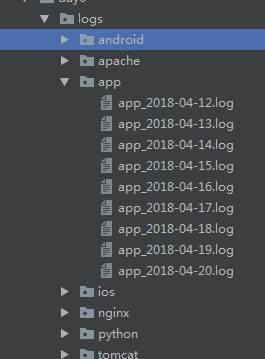
练习1
如下目录中,有很多文件,将偶数日期的文件中,写入任意文件内容
思路:
# 1、获取到log目录下面的所有文件 os.walk()
# 2、根据文件名来判断,是否是双数日期 ,分割字符串,取到日期
# 3、12%2==0
# 4、打开这个文件 open()
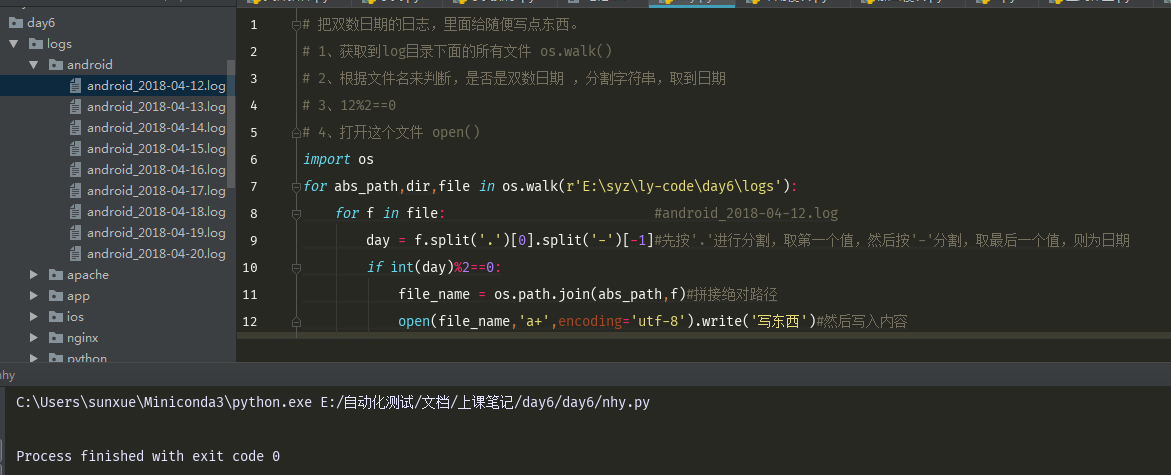
代码如下:
# 把双数日期的日志,里面给随便写点东西。 # 1、获取到log目录下面的所有文件 os.walk() # 2、根据文件名来判断,是否是双数日期 ,分割字符串,取到日期 # 3、12%2==0 # 4、打开这个文件 open() import os for abs_path,dir,file in os.walk(r'E:\syz\ly-code\day6\logs'): for f in file: #android_2018-04-12.log day = f.split('.')[0].split('-')[-1]#先按'.'进行分割,取第一个值,然后按'-'分割,取最后一个值,则为日期 if int(day)%2==0: file_name = os.path.join(abs_path,f)#拼接绝对路径 open(file_name,'a+',encoding='utf-8').write('写东西')#然后写入内容
时间模块
#1、时间戳 从unix元年到现在过了多少秒
#2、格式化好的时间
可以在网上对时间搓进行转换,找到时间搓对应的时间
print(time.time()) #获取当前的时间搓 # time.sleep(10) #睡眠时间,休息多少秒 #print('1111111') s=time.strftime('%Y-%m-%d %H:%M:%S') #获取格式化好的时间,类型为字符串 s1=time.strftime('%Y-%m-%d') #获取格式化好的时间,类型为字符串 print(s) print(s1) print(type(s))
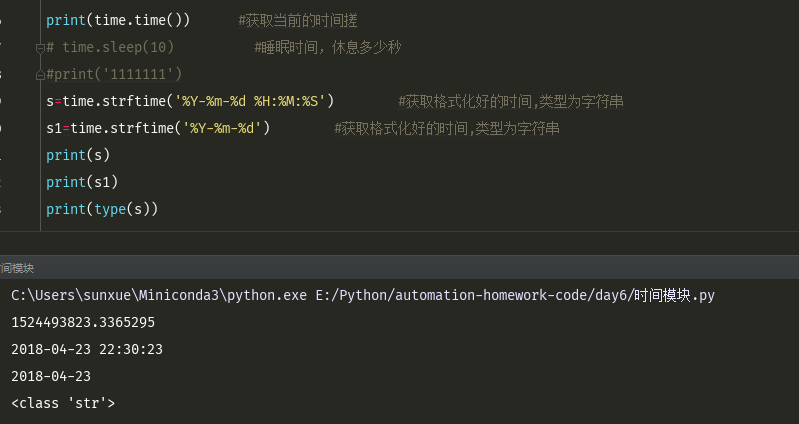
如果要将时间搓转换为格式化好的时间,
1、时间戳转成时间元组 time.localtime()
2、再把时间元组转成格式化的时间
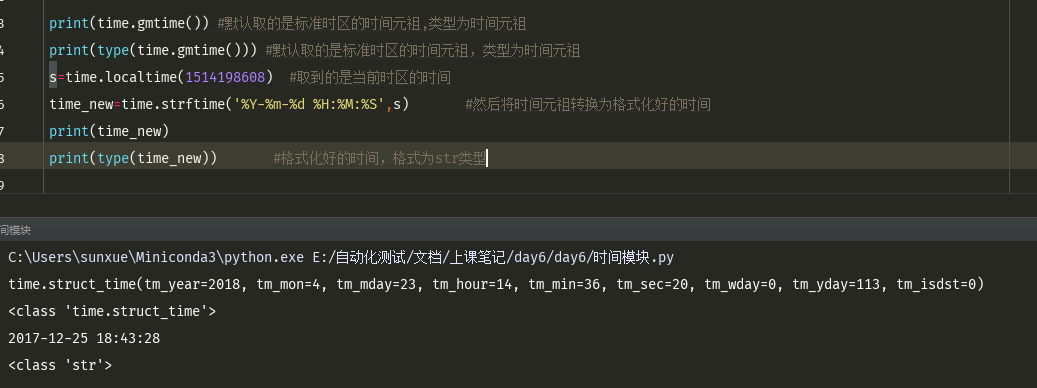
print(time.gmtime()) #默认取的是标准时区的时间元祖,类型为时间元祖 print(type(time.gmtime())) #默认取的是标准时区的时间元祖,类型为时间元祖 s=time.localtime(1514198608) #取到的是当前时区的时间 time_new=time.strftime('%Y-%m-%d %H:%M:%S',s) #然后将时间元祖转换为格式化好的时间 print(time_new) print(type(time_new)) #格式化好的时间,格式为str类型
将时间搓转换为时间元祖,写成一个函数,用的时候,直接调用就行
#时间戳转换时间元组 # 1、时间戳转成时间元组 time.localtime() # 2、再把时间元组转成格式化的时间 def timestamp_to_fomat(timestamp=None,format='%Y-%m-%d %H:%M:%S'): #1、默认返回当前格式化好的时间 #2、传入时间戳的话,把时间戳转换成格式化好的时间,返回 if timestamp: time_tuple = time.localtime(timestamp) res = time.strftime(format,time_tuple) else: res = time.strftime(format) #默认取当前时间 return res
将格式化好的时间,转换为时间搓
写成一个函数如下
# tp = time.strptime('2018-4-21','%Y-%m-%d') #把格式化好的时间转成时间元组的 # print(time.mktime(tp)) #把时间元组转成时间戳 def strToTimestamp(str=None,format='%Y%m%d%H%M%S'): # 20180421165643 #默认返回当前时间戳 if str: #如果传了时间的话 tp = time.strptime(str,format) #格式化好的时间,转成时间元组 res = time.mktime(tp)#再转成时间戳 else: res = time.time() #默认取当前的时间戳 return int(res)
datetime模块
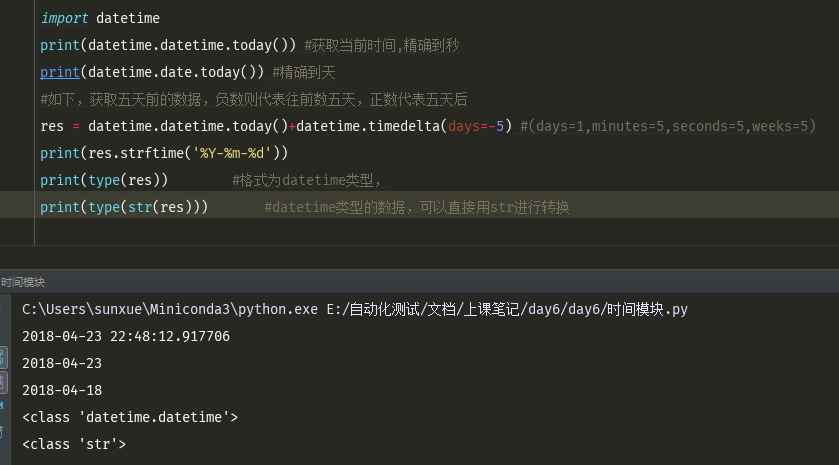
import datetime print(datetime.datetime.today()) #获取当前时间,精确到秒 print(datetime.date.today()) #精确到天 #如下,获取五天前的数据,负数则代表往前数五天,正数代表五天后 res = datetime.datetime.today()+datetime.timedelta(days=-5) #(days=1,minutes=5,seconds=5,weeks=5) print(res.strftime('%Y-%m-%d')) print(type(res)) #格式为datetime类型, print(type(str(res))) #datetime类型的数据,可以直接用str进行转换
hashlib模块,对字符串进行加密
#md5加密是不可逆
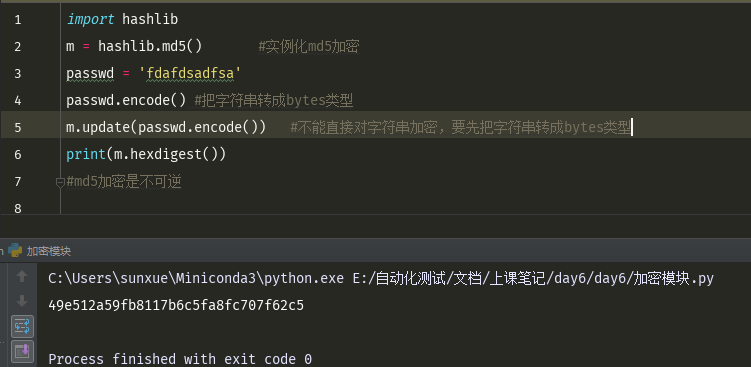
import hashlib m = hashlib.md5() #实例化md5加密 passwd = 'fdafdsadfsa' passwd.encode() #把字符串转成bytes类型 m.update(passwd.encode()) #不能直接对字符串加密,要先把字符串转成bytes类型 print(m.hexdigest())
将字符串加密写成一个函数,如下
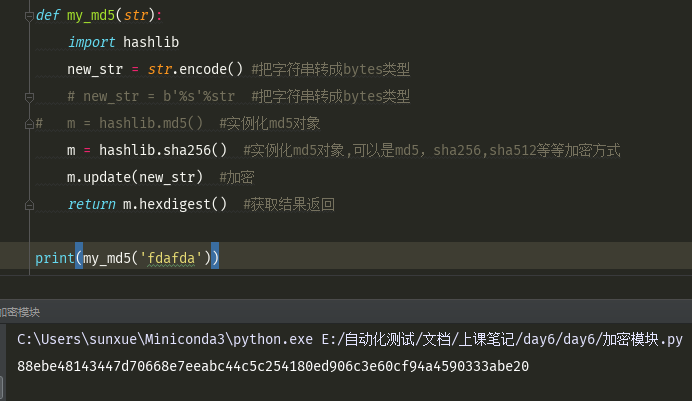
def my_md5(str): import hashlib new_str = str.encode() #把字符串转成bytes类型 # new_str = b'%s'%str #把字符串转成bytes类型 # m = hashlib.md5() #实例化md5对象 m = hashlib.sha256() #实例化md5对象,可以是md5,sha256,sha512等等加密方式 m.update(new_str) #加密 return m.hexdigest() #获取结果返回
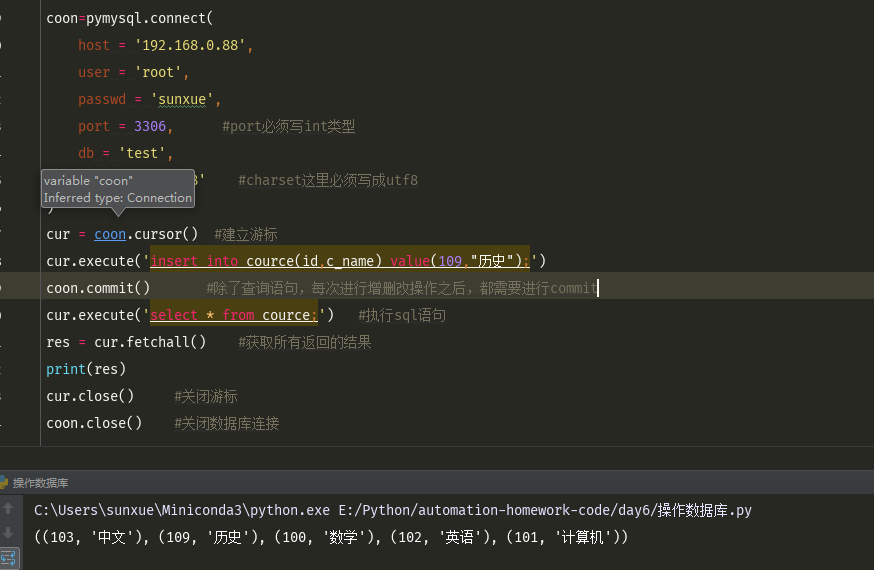
pymysql模块
流程如下:
import pymysql # 1、连上数据库 账号、密码 ip 端口号 数据库 #2、建立游标 #3、执行sql #4 、获取结果 # 5、关闭游标 #6、连接关闭 coon=pymysql.connect( host = '192.168.0.88', user = 'root', passwd = 'sunxue', port = 3306, #port必须写int类型 db = 'test', charset = 'utf8' #charset这里必须写成utf8 ) cur = coon.cursor() #建立游标 cur.execute('insert into cource(id,c_name) value(109,"历史");') coon.commit() #除了查询语句,每次进行增删改操作之后,都需要进行commit cur.execute('select * from cource;') #执行sql语句 res = cur.fetchall() #获取所有返回的结果 print(res) cur.close() #关闭游标 coon.close() #关闭数据库连接
连接数据库函数
def my_db(host,user,passwd,db,sql,port=3306,charset='utf8'): import pymysql coon = pymysql.connect(user=user, host=host, port=port, passwd=passwd, db=db, charset=charset ) cur = coon.cursor() #建立游标 cur.execute(sql)#执行sql if sql.strip()[:6].upper()=='SELECT': res = cur.fetchall() else: coon.commit() res = 'ok' cur.close() coon.close() return res
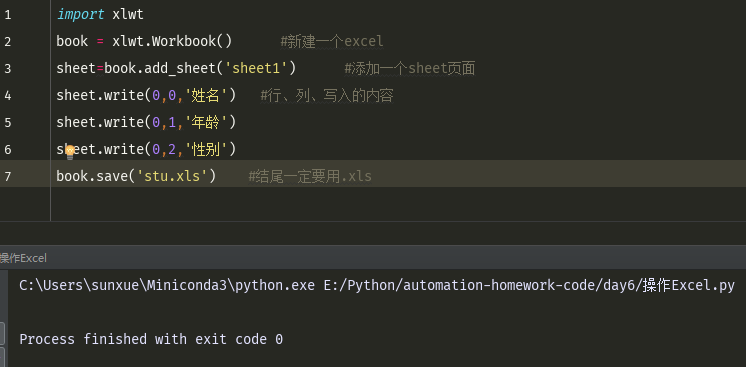
操作excel模块
import xlwt book = xlwt.Workbook() #新建一个excel sheet=book.add_sheet('sheet1') #添加一个sheet页面 sheet.write(0,0,'姓名') #行、列、写入的内容 sheet.write(0,1,'年龄') sheet.write(0,2,'性别') book.save(r'c:\\stu.xls') #保存到一个Excel中,结尾一定要用.xls