shell脚本搭建zk错误记录
网上的正常配置:
- shell脚本
在/usr/local/bin下面创建一个shell程序,命名为start.sh。
#!/bin/bash
echo "========== zookeeper启动 =========="
echo "========== 正在启动zookeeper =========="
for i in donghao@hadoop132 donghao@hadoop133 donghao@hadoop134
do
ssh $i '/opt/module/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start'
sleep 2s
done
echo "========== 正在启动HDFS =========="
ssh donghao@hadoop132 '/opt/module/hadoop/hadoop-2.7.3/sbin/start-dfs.sh'
echo "========== 正在启动YARN =========="
ssh donghao@hadoop133 '/opt/module/hadoop/hadoop-2.7.3/sbin/start-yarn.sh'
echo "========== hadoop132节点正在启动JobHistoryServer =========="
ssh donghao@hadoop132 '/opt/module/hadoop/hadoop-2.7.3/sbin/mr-jobhistory-daemon.sh start historyserver'
- zk的zoo.cfg设置
在zk的conf文件包下,将此zoo.cfg文件修改如下
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/module/zookeeper/zookeeper-3.4.10/zkData
####################cluster####################
#server.1=hadoop132:2888:3888
server.1=hadoop132:2888:3888
server.2=hadoop133:2888:3888
server.3=hadoop134:2888:3888
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
出现的问题
当我使用start.sh之后,
========== zookeeper启动 ==========
========== 正在启动zookeeper ==========
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
========== 正在启动HDFS ==========
Starting namenodes on [hadoop132]
hadoop132: starting namenode, logging to /opt/module/hadoop/hadoop-2.7.3/logs/hadoop-donghao-namenode-hadoop132.out
hadoop132: starting datanode, logging to /opt/module/hadoop/hadoop-2.7.3/logs/hadoop-donghao-datanode-hadoop132.out
hadoop133: starting datanode, logging to /opt/module/hadoop/hadoop-2.7.3/logs/hadoop-donghao-datanode-hadoop133.out
hadoop134: starting datanode, logging to /opt/module/hadoop/hadoop-2.7.3/logs/hadoop-donghao-datanode-hadoop134.out
Starting secondary namenodes [hadoop134]
hadoop134: starting secondarynamenode, logging to /opt/module/hadoop/hadoop-2.7.3/logs/hadoop-donghao-secondarynamenode-hadoop134.out
========== 正在启动YARN ==========
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop/hadoop-2.7.3/logs/yarn-donghao-resourcemanager-hadoop133.out
hadoop134: starting nodemanager, logging to /opt/module/hadoop/hadoop-2.7.3/logs/yarn-donghao-nodemanager-hadoop134.out
hadoop133: starting nodemanager, logging to /opt/module/hadoop/hadoop-2.7.3/logs/yarn-donghao-nodemanager-hadoop133.out
hadoop132: starting nodemanager, logging to /opt/module/hadoop/hadoop-2.7.3/logs/yarn-donghao-nodemanager-hadoop132.out
========== hadoop132节点正在启动JobHistoryServer ==========
starting historyserver, logging to /opt/module/hadoop/hadoop-2.7.3/logs/mapred-donghao-historyserver-hadoop132.out
但是当我在我的hadoop134机器上查询zk服务器情况的时候出现以下情况
[donghao@hadoop133 zookeeper-3.4.10]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
我使用自己编译的stop关闭zk的时候弹出
========== zookeeper关闭 ==========
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... /opt/module/zookeeper/zookeeper-3.4.10/bin/zkServer.sh: 第 182 行:kill: (23740) - 没有那个进程
STOPPED
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... /opt/module/zookeeper/zookeeper-3.4.10/bin/zkServer.sh: 第 182 行:kill: (14020) - 没有那个进程
STOPPED
========== hdfs 关闭 ==========
Stopping namenodes on [hadoop132]
hadoop132: stopping namenode
hadoop132: stopping datanode
hadoop134: stopping datanode
hadoop133: stopping datanode
Stopping secondary namenodes [hadoop134]
hadoop134: stopping secondarynamenode
========== yarn关闭 ===========
stopping yarn daemons
stopping resourcemanager
hadoop133: stopping nodemanager
hadoop134: stopping nodemanager
hadoop132: stopping nodemanager
no proxyserver to stop
========== hadoop132节点正在关闭JobHistoryServer ==========
stopping historyserver

显示的就是133与134的进程没有开启
问题查找
- 我在我的
hadoop132机器上
[donghao@hadoop132 bin]$ jps
23818 NodeManager
23499 DataNode
23936 JobHistoryServer
23316 NameNode
23065 QuorumPeerMain
24066 Jps
此处说明在hadoop132这台机器上,zkServer已经运行好了
- 我在我的
hadoop133机器上
[donghao@hadoop133 zookeeper-3.4.10]$ jps
25429 NodeManager
25142 DataNode
25773 Jps
25298 ResourceManager
此处说明在hadoop133机器上,zkServer未运行。
问题的解决
我查找了好多博客,之后解决了,我也不太清楚以下哪些是无用的,哪些才是关键的,但是我都在下面将我修改的列出来。
- 首先修改conf文件夹下的zoo.cfg文件
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/module/zookeeper/zookeeper-3.4.10/zkData
####################cluster####################
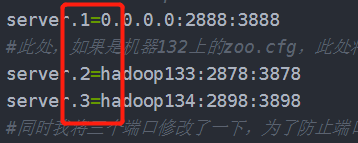
#server.1=hadoop132:2888:3888
server.1=0.0.0.0:2888:3888
#此处,如果是机器132上的zoo.cfg,此处将hadoop132修改成0.0.0.0,如果是133上面的就将hadoop133修改成0.0.0.0
server.2=hadoop133:2878:3878
server.3=hadoop134:2898:3898
#同时我将三个端口修改了一下,为了防止端口被占用情况的发生。(此处我不确定不修改有没有影响,我也没做过测试)
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
- 其次将zoo.cfg设定的dataDir文件夹下的myid
此处将hadoop132机器上的myid修改成下面的参数值
[donghao@hadoop132 zkData]$ cat myid
1
同时将hadoop133、hadoop134中的此值修改成对应的值(看zoo.cfg中的server后面的数值)
- 修改shell程序
我将shell程序进行了一定的修改,此处是我最后做的修改,作此修改以后我的shell运行成功,而且zk集群也运行起来了。
#!/bin/bash
echo "========== zookeeper启动 =========="
echo "========== 正在启动zookeeper =========="
for i in donghao@hadoop132 donghao@hadoop133 donghao@hadoop134
do
ssh $i 'source /etc/profile;/opt/module/zookeeper/zookeeper-3.4.10/bin/zkServer.sh start'
#此处我添加了一个source /etc/profile;
sleep 2s
done
echo "========== 正在启动HDFS =========="
ssh donghao@hadoop132 '/opt/module/hadoop/hadoop-2.7.3/sbin/start-dfs.sh'
echo "========== 正在启动YARN =========="
ssh donghao@hadoop133 '/opt/module/hadoop/hadoop-2.7.3/sbin/start-yarn.sh'
echo "========== hadoop132节点正在启动JobHistoryServer =========="
ssh donghao@hadoop132 '/opt/module/hadoop/hadoop-2.7.3/sbin/mr-jobhistory-daemon.sh start historyserver'
之后再运行,我在hadoop133上面就看到了
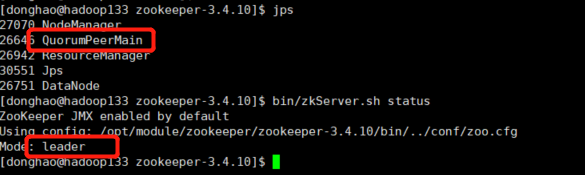
我自己也不太清楚,不过我这样的确成功了。