一.基本格式
from django.conf.urls import url from . import views #循环urlpatterns,找到对应的函数执行,匹配上一个路径就找到对应的函数执行, 就不再往下循环了,并给函数传一个参数request,和wsgiref的environ类似 ,就是请求信息的所有内容 urlpatterns = [ url(正则表达式, views视图函数,参数,别名), ]
参数说明 1.正则表达式:一个正则表达式字符串 2.views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串 3.参数:可选的要传递给视图函数的默认参数(字典形式) 4.别名:一个可选的name参数
注意事项 1.urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续。 2.若要从URL中捕获一个值,只需要在它周围放置一对圆括号(分组匹配)。 3.不需要添加一个前导的反斜杠(也就是写在正则最前面的那个/), 因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。 4.每个正则表达式前面的'r' 是可选的但是建议加上。 5.^articles& 以什么结尾,以什么开头,严格限制路径
二.分组命名匹配
from django.conf.urls import url from . import views urlpatterns = [ url(r'^articles/2003/$', views.special_case_2003), #注意正则匹配出来的内容是字符串,即便是你在url里面写的是2003数字,匹配出来之后也是字符串 url(r'^articles/(\d{4})/$', views.year_archive),#year_archive(request,2003), 小括号为分组,有分组,那么这个分组得到的用户输入的内容,就会作为对应函数的位置参数传进去, 别忘了形参要写两个了,明白了吗? url(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive), #某年的,(?P<year>[0-9]{4})这是命名参数(正则命名匹配还记得吗?), 那么函数year_archive(request,year),形参名称必须是year这个名字。 而且注意如果你这个正则后面没有写$符号,即便是输入了月份路径,也会被它拦截下拉,因为它的正则也能匹配上 url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive), #某年某月的 url(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<day>[0-9]{2})/$', views.article_detail), #某年某月某日的 ]
# urls.py中 from django.conf.urls import url from . import views urlpatterns = [ url(r'^blog/$', views.page), url(r'^blog/page(?P<num>[0-9]+)/$', views.page), ] # views.py中,可以为num指定默认值 def page(request, num="1"): pass 复制代码
三.分发 ( include)
1.分发过程
①主文件中的 urls.py
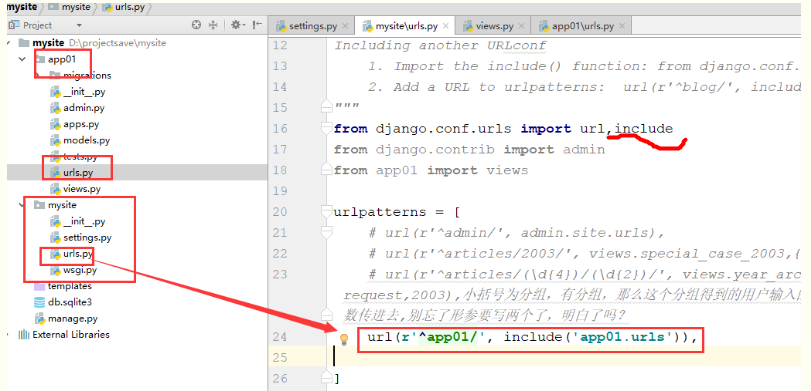
② app文件中的 urls.py

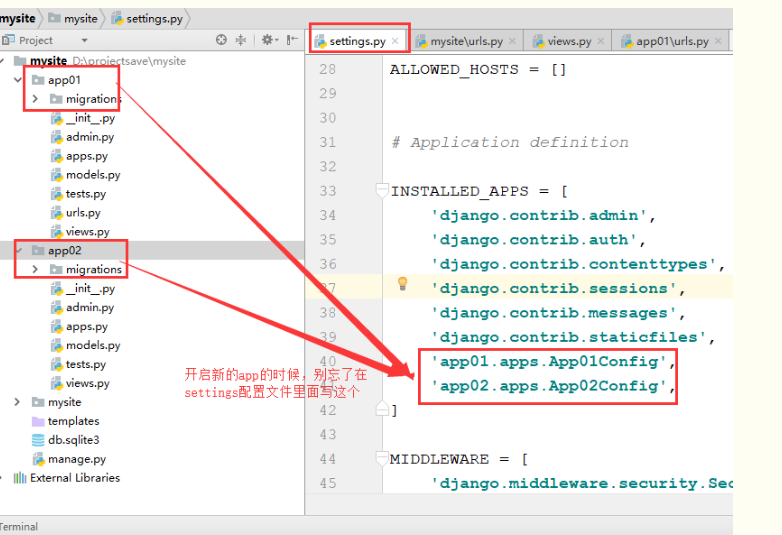
③ settings.py文件中添加 app02
四.参数
1. 从 .html 传到 view.py
在 .html 中 1 2 3 作为参数 <ul> <li><a href="{% url 'articles' 1 %}">第1页</a></li> <li><a href="{% url 'articles' 2 %}">第2页</a></li> <li><a href="{% url 'articles' 3 %}">第3页</a></li> </ul>s 在 urls.py 文件中 参数要用小括号 里面是正则表达式 通过函数传送 url(r'^articles/(\d{1})/',views.articles,name='articles'), 在 view.py 文件中 通过函数传过来 def articles(request,page_number): s = '这是第' + page_number +'页的所有文章' return HttpResponse(s)
2. 从view.py 传到 .html
①. 在view.py 文件中

②. 在 .html 文件中

五.别名 ( URL的反向解析)(软编码)
解决解决网址更换带来的不便
在urls.py文件中 url(r'^index', views.home, name='home'), # 给我的url匹配模式起名(别名)为 home,别名不需要改,路径你就可以随便改了, 别的地方使用这个路径,就用别名来搞 在 .html 文件中(不管文职如何改变,在.html中都不需要改变) <body> <a href="{% url 'home' %}">asdf</a> <form action="{% url home' %}"> </form> <a href="{% url 'home' %}">asdf</a> </body> 在 view.py 中 先引入 from django.urls import reverse def login(request): if request.method == 'POST': url = reverse('home') print(url) return redirect(url) #重定向 return render(request,'login.html')
六.重定向( redirect 响应)
给浏览器一个 30x 的状态码
重定向原因:
(1)网站调整(如改变网页目录结构);
(2)网页被移到一个新地址;
(3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户
得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的
网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
示例
view文件中 from django.shortcuts import render,HttpResponse,redirect def index(request): return redirect('/base/') def base(request): dic = {'name': 'chao'} return render(request,'base.html',dic)
urls.py文件中 from django.conf.urls import url from django.contrib import admin from app01 import views urlpatterns = [ # url(r'^admin/', admin.site.urls), url(r'^$', views.index), url(r'^base/', views.base), ]
301和302的区别。 301和302状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到
一个新的URL地址,这个地址可以从响应的Location首部中获取 (用户看到的效果就是他输入的地址A瞬间变成了另一个地址B)——这是它们的共同点。 他们的不同在于。
301表示旧地址A的资源已经被永久地移除了(这个资源不可访问了),
搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址; 302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时地从旧地址A跳转到地址B,
搜索引擎会抓取新的内容而保存旧的网址。 SEO302好于301
七.请求 与 响应 的常用方法
from django.shortcuts import render,HttpResponse,redirect # Create your views here. def index(request): #请求方式 print(request.method) #获取请求方式 print(request.GET) #获取get请求的所有数据 字典 print(request.POST) #获取post请求的所有数据 字典 # print(request.GET.get()) #字典取值 # print(request.POST.get()) #字典取值 print(request.path) # /index/ #路径 print(request.get_full_path()) # /index/?a=1&b=2 路径带参数 # print(request.META) # 请求头所有信息的一个大字典 print(request.META['HTTP_USER_AGENT']) # Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36 #响应方式 #① HttpResponse(字符串) # return HttpResponse('ok') # ②render 返回页面 # ③redirect 重定向 return redirect('/base/')
八.静态文件配置方式
1

2
