一、累加器简介
在Spark中如果想在Task计算的时候统计某些事件的数量,使用filter/reduce也可以,但是使用累加器是一种更方便的方式,累加器一个比较经典的应用场景是用来在Spark Streaming应用中记录某些事件的数量。
使用累加器时需要注意只有Driver能够取到累加器的值,Task端进行的是累加操作。
创建的Accumulator变量的值能够在Spark Web UI上看到,在创建时应该尽量为其命名,下面探讨如何在Spark Web UI上查看累加器的值。
示例代码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
启动的时候注意观察控制台上输出的Spark Web UI的地址:

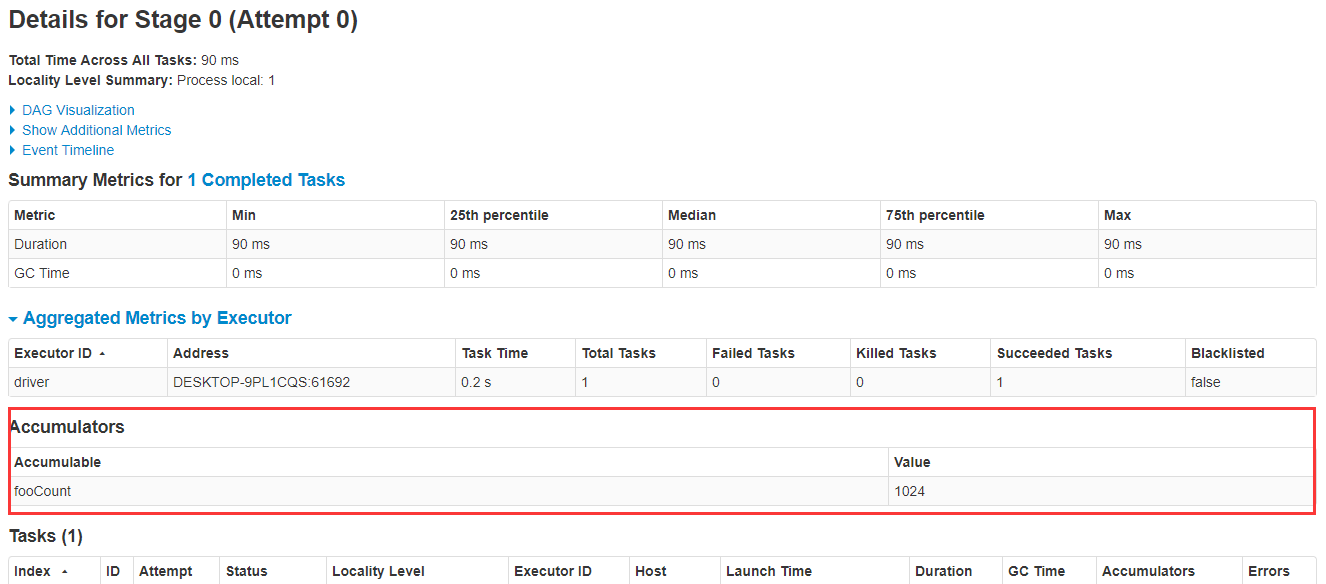
打开此链接,点进去Jobs-->Stage,可以看到fooCount累加器的值已经被累加到了1024:
二、Accumulator的简单使用
Spark内置了三种类型的Accumulator,分别是LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
|
三、自定义Accumulator
当内置的Accumulator无法满足要求时,可以继承AccumulatorV2实现自定义的累加器。
实现自定义累加器的步骤:
1. 继承AccumulatorV2,实现相关方法
2. 创建自定义Accumulator的实例,然后在SparkContext上注册它
假设要累加的数非常大,内置的LongAccumulator已经无法满足需求,下面是一个简单的例子用来累加BigInteger:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
|
思考:内置的累加器LongAccumulator、DoubleAccumulator、CollectionAccumulator和我上面的自定义BigIntegerAccumulator,它们都有一个共同的特点,就是最终的结果不受累加数据顺序的影响(对于CollectionAccumulator来说,可以简单的将结果集看做是一个无序Set),看到网上有博主举例子StringAccumulator,这个就是一个错误的例子,就相当于开了一百个线程,每个线程随机sleep若干毫秒然后往StringBuffer中追加字符,最后追加出来的字符串是无法被预测的。总结一下就是累加器的最终结果应该不受累加顺序的影响,否则就要重新审视一下这个累加器的设计是否合理。
四、使用Accumulator的陷阱
来讨论一下使用累加器的一些陷阱,累加器的累加是在Task中进行的,而这些Task就是我们在Dataset上调用的一些算子操作,这些算子操作有Transform的,也有Action的,来探讨一下不同类型的算子对Accumulator有什么影响。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
|
五、Accumulator使用的奇淫技巧
累加器并不是只能用来实现加法,也可以用来实现减法,直接把要累加的数值改成负数就可以了:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
|