介绍java线程池
本文我们介绍java线程池,学习java标准库的不同实现以及Guava库提供的实现。
1. 什么是线程池
在java中线程被映射至系统级线程(属于操作系统资源)。如果你无限制创建线程,会很快耗尽系统资源。
线程之间切换也是操作系统来调度。为了实现并行机制,一个简单的观点是生成的线程越多,则每个线程花在实际工作上的时间就越少。
线程池模型帮助我们在多线程应用中节省资源,并对并行机制预定义限制。
当使用线程池,写并行任务形式的代码提交至线程池的实例去执行,线程池实例可以重用线程执行提交任务。
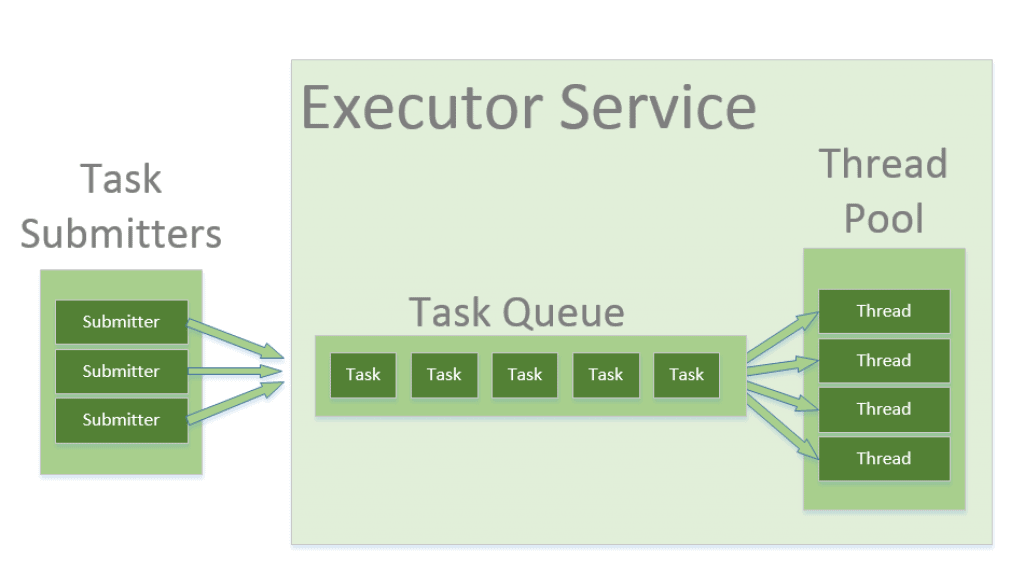
线程池模式可以控制创建线程数、生命周期、调度任务执行以及在队列中保存即将执行的任务。
2. java中线程池实现
2.1. Executors, Executor 和 ExecutorService
Executor助手类包含创建预定义线程池实例的几个方法,如果你不需要自定义细粒度微调参数设置,使用这些方法是最好开始。
Executor和ExecutorService接口用于在Java中处理不同的线程池实现。通常,您应该将业务代码与线程池的实例实现解耦,并在整个应用程序中使用这些接口。
Executor接口只有一个execute方法,用于提交Runable实例以供执行。
情况下面简单示例,展示如何使用Executors API获取由单个线程池实例和无限制队列,以便按顺序执行任务。这里执行一个任务,仅在屏幕上打印“Hello World”。任务作为lambda (Java 8特性)提交,推断为Runnable类型。
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Hello World"));
ExecutorService接口中包含大量控制任务进度及管理服务终止的方法。使用该接口可以提交执行任务并通过Future类型返回值控制其执行。
下面示例,我们创建ExecutorService,提交任务然后使用其返回值Future.get方法等待提交任务执行完毕:
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(() -> "Hello World");
// some operations
String result = future.get();
当然,现实场景中通常不需要立刻调用future.get()方法,而是估计任务已经执行完成开始调用。
submit有重载方法,可以接收Runnable 或 Callable 函数式接口,也可以传入lambda表达式。
Runnable接口不抛出异常,也没有返回值。Callable接口更灵活,允许抛异常并有返回值。
最后,为了让编译器推断Callable类型,可以简单从lambda表达式返回一个值。
2.2. ThreadPoolExecutor
ThreadPoolExecutor是可扩展的线程池实现,有很多参数和Hook用于调优。我们主要讨论的配置参数为:corePoolSize, maximumPoolSize, keepAliveTime。
由固定数量的核心线程组成线程池,并一直驻留在池中。可能产生的多余线程不再需要时会被终止。corePoolSize参数是需实例化并保留在池中的核心线程总数,如果所有核心线程都忙,这时提交新的执行任务,那么线程池可以增长至maximumPoolSize数。
keepAliveTime参数是允许多余线程(即实例化的线程超过corePoolSize)以空闲状态存在的时间间隔。
这些参数能满足大多数应用场景,但Executors的静态方法预定义了很多典型的配置。例如,newFixedThreadPool方法创建corePoolSize和maximunPoolSize相等且keepAliveTime为0的ThreadPoolExecutor,意味着在线程池中的线程总是一样:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(2);
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(2, executor.getPoolSize());
assertEquals(1, executor.getQueue().size());
上面示例中,我们使用固定大小2实例化ThreadPoolExecutor,当同时运行的线程始终小于或等于2,那么这些任务会立刻执行,否则,一些任务可能进入队列等待执行。
我们创建三个Callable任务模拟耗时任务(等待1秒)。前两个立刻执行,第三个进入队列等待执行。提交任务后可以通过getPoolSize() 、 getQueue().size() 方法进行验证。
另一个预配置ThreadPoolExecutor可以使用executor.newcachedthreadpool()方法创建,其不接收任何线程数量参数。corePoolSize实际上设置为0,而maximumPoolSize设置为Integer.MAX_VALUE。keepAliveTime是60秒。
这些参数值意味着缓存线程池可能不受限制增长满足任何提交的任务,但当多余线程不再需要时,会在不活动60秒后被销毁。一个典型的使用场景是有大量短活动任务。
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newCachedThreadPool();
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(3, executor.getPoolSize());
assertEquals(0, executor.getQueue().size());
上面示例队列始终为0,因为内部使用SynchronousQueue实例,在SynchronousQueue里,插入和删除操作总是同时发生,所以队列永不包含任何任务。
Executors.newSingleThreadExecutor() API创建另一个典型的ThreadPoolExecutor包含单个线程。单线程Executor是执行事件循环的理想选择。corePoolSize 和 maximumPoolSize 参数值为1, keepAliveTime 是 0.
上面示例中任务总是按照顺序执行,所以任务完成后标志设为2:
AtomicInteger counter = new AtomicInteger();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> {
counter.set(1);
});
executor.submit(() -> {
counter.compareAndSet(1, 2);
});
此外,这个ThreadPoolExecutor使用不可变包装器进行装饰,因此创建之后不能重新配置。请注意,这也是不能将其强制转换为ThreadPoolExecutor的原因。
2.3. ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承子ThreadPoolExecutor类,同时实现ScheduledThreadPoolService接口,带有几个额外方法:
- schedule 方法在指定延迟时间后执行一次任务;
- scheduleAtFixedRate 方法在指定初始延迟时间后,然后在一定期间内重复执任务; period 参数指两个任务开始时间之间的周期,所以执行率是固定的。
- scheduleWithFixedDelay 方法与scheduleAtFixedRate类型,重复执行给定任务,但指定延迟是指前一个任务结束和下一个任务开始之间的时间,因此,执行率根据执行不同任务所用时间不同而不固定。
Executors.newScheduledThreadPool()方法典型用于创建给定corePoolSize,无限maximunPoolSize以及keepAliveTime为0的ScheduledThreadPoolExecutor。下面是如何安排任务在500毫秒内执行:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
executor.schedule(() -> {
System.out.println("Hello World");
}, 500, TimeUnit.MILLISECONDS);
下面示例演示如何在500毫秒延迟后,然后每100毫秒重复执行任务。计划好任务后,等等其使用CountDownLatch 锁触发三次,然后使用Future.cancel() 取消。
CountDownLatch lock = new CountDownLatch(3);
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
ScheduledFuture<?> future = executor.scheduleAtFixedRate(() -> {
System.out.println("Hello World");
lock.countDown();
}, 500, 100, TimeUnit.MILLISECONDS);
lock.await(1000, TimeUnit.MILLISECONDS);
future.cancel(true);
2.4. ForkJoinPool
ForkJoinPooll是Java 7中引入的fork/join框架的核心部分。它解决了递归算法中生成多个任务的常见问题。使用简单的ThreadPoolExecutor,您将很快耗尽线程,因为每个任务或子任务都需要自己的线程来运行。在fork/join框架中,任何任务都可以派生(fork)许多子任务,并使用join方法等待它们完成。fork/join框架的好处是,它不会为每个任务或子任务创建新的线程,而是实现了工作窃取(Work Stealing)算法。
让我们看一个简单示例,使用ForkJoinPool转换树节点并计算所有叶子节点值之和。下面是一个简单组成树的节点类,包括int值和一组子节点:
static class TreeNode {
int value;
Set<TreeNode> children;
TreeNode(int value, TreeNode... children) {
this.value = value;
this.children = Sets.newHashSet(children);
}
}
现在如果我们想并行计算所有值之和,我们需要实现 RecursiveTask接口。每个任务接收其自己的接口并增加值至所有子节点值之和。为了计算所有子节点值之和,任务实现如下:
- 获取子节点Set集合的stream
- 在map方法中,为每个元素创建新的CountingTask
- 通过fork执行每个子任务
- 对每个fork任务调用join方法收集执行结果
- 使用Collectors.summingInt 收集器求总和
public static class CountingTask extends RecursiveTask<Integer> {
private final TreeNode node;
public CountingTask(TreeNode node) {
this.node = node;
}
@Override
protected Integer compute() {
return node.value + node.children.stream()
.map(childNode -> new CountingTask(childNode).fork())
.collect(Collectors.summingInt(ForkJoinTask::join));
}
}
下面代码运行实际树的计算:
TreeNode tree = new TreeNode(5,
new TreeNode(3), new TreeNode(2,
new TreeNode(2), new TreeNode(8)));
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
int sum = forkJoinPool.invoke(new CountingTask(tree));