在了解numpy前先来了解一下数组:
数组和列表的区别:
- 数组: 存储的时同一种数据类型;
- list:容器, 可以存储任意数据类型;
# 一维数组和数组的计算
a = [1, 2, 3, 4]
b = [2, 3, 4, 5]
add = lambda x: x[0] + x[1]
# [(1,2), (2,3), (3,4), (4,5)]
print([add(item) for item in zip(a, b)])
mul = lambda x: x[0] * x[1]
# [(1,2), (2,3), (3,4), (4,5)]
print([mul(item) for item in zip(a, b)])
不论一维数组还是二维数组都不能直接进行加减乘除运算,需要嵌套for循环很麻烦,这就有了numpy,让数组计算变得简单:
文章目录
1 什么numpy?
快速, 方便的科学计算基础库(主要时数值的计算, 多维数组的运算);
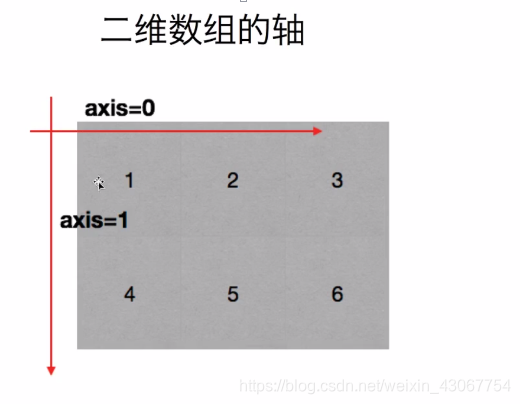
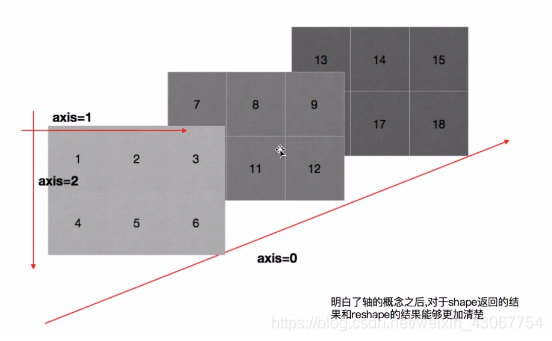
2 numpy基础概念
- 轴的理解(axis): 0轴, 1轴, 2轴
- 一维数组: [1,2,3,45] ----0轴
- 二维数组: [[1,2,3,45], [1,2,3,45]] ----0轴, 1轴
3 numpy常用的方法
1. numpy中如何创建数组(矩阵)?
# 方法1:
a = np.array([1,2,3,4,5])
b = np.array([1,2,3,4,5])
c1 = np.array(range(1,6))
print(a+b)
# 方法2:
c2 = np.arange(1,6)
print(c1)
print(c2)
# [1 2 3 4 5]
print(type(c2))
# 类名:numpy.ndarray
print(c2.dtype)
# 元素类型int64
2 修改类型.astype

print(c.astype('float'))
# [1. 2. 3. 4. 5.]
print(c.astype('bool'))
# [ True True True True True]
print(c.astype('?'))
# [ True True True True True]
3. 修改浮点数的小数位数np.round
c3 = np.array([1.234556, 3.45464456, 5.645657567])
print(np.round(c3, 2))
#[1.23 3.45 5.65]
4 numpy读取操作
eg6-a-student-data.txt这个文档我放在云盘提取码:mys5
import numpy as np
fname = "doc/eg6-a-student-data.txt"
dtype = np.dtype([('gender', '|S1'), ('height', 'f2')])
# fname: 文件的名称, 可以是文件名, 也可以是ugz或者bz2的压缩文件;
# dtype: 数据类型, 可选, 默认是float;
# delimiter: 分隔符字符串, 默认情况是任何的空格,
# skiprows: 跳过前xx行, 一般情况跳过第一行;
# usecols: 读取指定的列, 可以是元组;
# unpack: 如果为True, 对返回的数组对象转置;
data = np.loadtxt(fname=fname, dtype=dtype, skiprows=9, usecols=(1, 3), unpack=True)
# loadtxt源代码
# def loadtxt(fname, dtype=float, comments='#', delimiter=None,
# converters=None, skiprows=0, usecols=None, unpack=False,
# ndmin=0, encoding='bytes', max_rows=None):
print(data)
输出:
[array([b'M', b'M', b'F', b'M', b'F', b'F', b'M', b'M', b'F', b'F', b'M',
b'M', b'M', b'F', b'F', b'M', b'F', b'F', b'M'], dtype='|S1'), array([1.82, 1.77, 1.68, 1.72, 1.78, 1.6 , 1.72, 1.83, 1.56, 1.64, 1.63,
1.67, 1.66, 1.59, 1.7 , 1.97, 1.66, 1.63, 1.69], dtype=float16)]
5 数组的转置
import numpy as np
# 将一维数组转换为3行4列的二维数组
data = np.arange(12).reshape((3, 4))
print(data)
#[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
# 转置的三种方法
# 1).转置
print(data.transpose())
# 2). 0轴 , 1 轴
print(data.swapaxes(1, 0))
# 3).简写T
print(data.T)
输出:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
6numpy切片和索引
import numpy as np
data = np.arange(12).reshape((3,4))
print(data)
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# 第一行
print(data[0])
# [0 1 2 3]
#
# 第一列
print(data[:,0])
print(data.T[0]) # [0 4 8]
#
#
# # 获取多行
print(data[:2])
# [[0 1 2 3]
# [4 5 6 7]]
#
# 获取多列的两种方法
print(data)
print(data[:,:2])
# [[0 1]
# [4 5]
# [8 9]]
print(data.T[:2])
# [[0 4 8]
# [1 5 9]]
# 获取指定行的前几列
# 前两行的第一列和第三列
print(data[:2,[0,2]])
# [[0 2]
# [4 6]]
# 获取第一行和第三行的前两列
print(data[[0,2],:2])
# [[0 1]
# [8 9]]
7numpy中数值的修改
import numpy as np
# 1.一维---->3行4列
data = np.arange(12).reshape((3,4))
print(data)
# 1第一行数据全为0
data[0] = 0
print(data)
# 2前两列全为0
data.T[:2] = 0
print(data)
# 3data中所有大于10的数字替换为0
print(data>10)
# [[False False False False]
# [False False False False]
# [False False False True]]
data[data>8]=0
print(data)
# [[0 1 2 3]
# [4 5 6 7]
# [8 0 0 0]]
# 4 data中所有大于10的数字替换为0,否则替换为1
# 注释掉前面的操作
data[data<=8]=1
data[data>8] =0
print(data)
# [[1 1 1 1]
# [1 1 1 1]
# [1 0 0 0]]
# 第二种方法
print(np.where(data<=8,1,0))
# [[1 1 1 1]
# [1 1 1 1]
# [1 0 0 0]]
# 裁剪
# 小于等于8的替换为8,大于等于10的替换为10
print(data.clip(8,10))
# [[ 8 8 8 8]
# [ 8 8 8 8]
# [ 8 9 10 10]]
# # 数组的拼接
t1 = np.arange(12).reshape(2,6)
t2 = np.arange(12).reshape(2,6)
# 竖直拼接
print(np.vstack((t1,t2)))
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]
# [ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
# 水平拼接
print(np.hstack((t1,t2)))
# [[ 0 1 2 3 4 5 0 1 2 3 4 5]
# [ 6 7 8 9 10 11 6 7 8 9 10 11]]
# 行交换
t4 = np.arange(12).reshape(2,6)
print(t4)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
t4[[0,1],:] = t4[[1,0],:]
print(t4)
# [[ 6 7 8 9 10 11]
# [ 0 1 2 3 4 5]]
# 列交换
t4[:,[0,1]] = t4[:,[1,0]]
print(t4)
# [[ 7 6 8 9 10 11]
# [ 1 0 2 3 4 5]]
8numpy中最大值、最小值、全为0的数组、全为1的数组、对角线全为1的正方形数组
import numpy as np
# 将一维数组转换为3行4列的二维数组
data = np.arange(12).reshape((3, 4))
data[0, 0] = 80 #(0,0)处改为80
print(data)
# [[80 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# 1. 获取最大值和最小值的位置;
# 获取当前数组里面最大值的索引;
max_item1 = np.argmax(data)
print(max_item1)
# 0
# 获取每一列的最大值对应的索引;
print(np.argmax(data, axis=0))
# [0 2 2 2]
# 获取每一行的最大值对应的索引;
print(np.argmax(data, axis=1))
# [0 3 3]
# 2. 创建一个全为0的数组;
print(np.zeros((3, 3), dtype=np.int))
# [[0 0 0]
# [0 0 0]
# [0 0 0]]
# 3. 创建一个全为1的数组;
print(np.ones((3, 4)))
# [[1. 1. 1. 1.]
# [1. 1. 1. 1.]
# [1. 1. 1. 1.]]
# 4. 创建一个对角线全为1的正方形数组(方阵)
print(np.eye(3))
# [[1. 0. 0.]
# [0. 1. 0.]
# [0. 0. 1.]]
9深拷贝与浅拷贝
列表的深拷贝和浅拷贝
- 浅拷贝: a= b[::] a = copy.copy(b)
- 深拷贝: a = copy.deepcopy(b)
- numpy中的拷贝
- data1 = data: 完全不复制, 两个变量相互影响, 指向同一块内存空间;
- data2 = data[::], 会创建新的对象data2,
但是data的数据完全由data2保管, 两个的数据变化是一致的; - data3 = data.copy(), 深拷贝, 两个变量不湖影响;
import numpy as np
data = np.arange(8).reshape(2,4)
data
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
data1 = data
id(data)
140444611238448
id(data1)
140444611238448
data2 = data[::]
id(data)
140444611238448
id(data2)
140444621241360
id(data[0])
140444621241200
id(data2[0])
140444620515568
data
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
data2
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
np.where(data2<4,4,10)
array([[ 4, 4, 4, 4],
[10, 10, 10, 10]])
data2
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
data2[0] = 0
data2
array([[0, 0, 0, 0],
[4, 5, 6, 7]])
data
array([[0, 0, 0, 0],
[4, 5, 6, 7]])
data3 = data.copy()
data
array([[0, 0, 0, 0],
[4, 5, 6, 7]])
data3
array([[0, 0, 0, 0],
[4, 5, 6, 7]])
data3[0] = 10
data3
array([[10, 10, 10, 10],
[ 4, 5, 6, 7]])
data
array([[0, 0, 0, 0],
[4, 5, 6, 7]])
10缺失值nan和负无穷inf
nan(not a number): 表示不是一个数字, 代表的是数据缺失
inf(infinity): inf代表正无穷, -inf代表负无穷
# nan的特殊属性:
- 两个nan的值是不相等的, 是float类型:
>>> np.nan == np.nan
False
>>> np.nan != np.nan
True
- 如何判断有多少个缺失值:
data = np.arange(12, dtype=np.float).reshape(3, 4)
data
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
data[:2, 2] = np.nan
data
array([[ 0., 1., nan, 3.],
[ 4., 5., nan, 7.],
[ 8., 9., 10., 11.]])
np.count_nonzero(data!=data)
2
data!=data
array([[False, False, True, False],
[False, False, True, False],
[False, False, False, False]])
# 判断data里面的缺失值
np.isnan(data)
array([[False, False, True, False],
[False, False, True, False],
[False, False, False, False]])
np.count_nonzero(np.isnan(data))
2
data[np.isnan(data)]=0
11常用统计函数
import numpy as np
data = np.arange(12, dtype=np.float).reshape(3, 4)
print(data.sum())
# 每一列数据的和;
print(data.sum(axis=0))
# 每一行数据的和;
print(data.sum(axis=1))
# - 均值
print(data.mean())
print(data.mean(axis=0))
print(data.mean(axis=1))
# - 中值
print(data)
print(np.median(data))
print(np.median(data, axis=0))
print(np.median(data, axis=1))
# - 最大值
print(data.max())
print(data.max(axis=0))
print(data.max(axis=1))
# - 最小值
# - 极差
print(np.ptp(data))
print(np.ptp(data, axis=0))
print(np.ptp(data, axis=1))
# - 标准差: 代表的是数据的波动稳定情况, 数字越大, 越不稳定;
print(data.std())
print(data.std(axis=0))
print(data.std(axis=1))